Sketch介绍
为什么要用Sketch
- 网络流主要根据五元组、主机地址、包的大小来分类。在网络中存在各种各样的包,如果按照上述分类方法,对每一种包都分配一个计数器来储存,虽然测量准确,那么存放计数器的空间开销会非常大。所以使用哈希的方法,根据哈希值的范围来确定的所需的存储空间,各种包根据哈希值再次归类,可以大大减少存储空间。这样使用哈希来估计流的方法称为Sketch-based方法。
Count-min sketch
如何处理包
- 使用哈希的方法会产生冲突,多个种类的包哈希到同一个桶内,那么这个桶的计数值就会偏大,为了减少误差,设计了count-min sketch
- 设置多个哈希函数,开辟一个二维地址空间,包经过不同哈希函数的处理,得到对应的哈希值,而这个哈希值就是sketch(概要)。这些哈希值可能产生冲突,多个种类的包可能有相同的哈希值,则根据哈希值来确定包出现的次数则会偏大,所以设立多个哈希函数,取最小的哈希值,则最接近实际包数据。
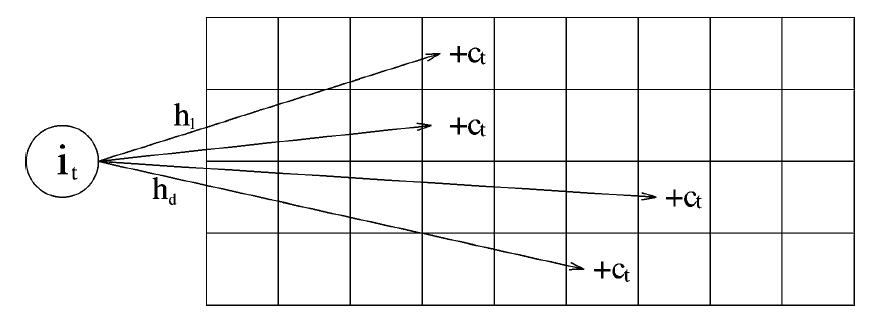
count-min sketch 某种实现
class CountMinSketch {
long estimators[][] = new long[d][w] // d and w are design parameters
long a[] = new long[d]
long b[] = new long[d]
long p // hashing parameter, a prime number. For example 2^31-1
void initializeHashes() { //初始化hash函数family,不同的hash函数中a,b参数不同
for(i = 0; i < d; i++) {
a[i] = random(p) // random in range 1..p
b[i] = random(p)
}
}
void add(value) {
for(i = 0; i < d; i++)
estimators[i][ hash(value, i) ]++ //简单的对每个bucket经行叠加
}
long estimateFrequency(value) {
long minimum = MAX_VALUE
for(i = 0; i < d; i++)
minimum = min( //取出最小的估计值
minimum,
estimators[i][ hash(value, i) ]
)
return minimum
}
hash(value, i) {
return ((a[i] * value + b[i]) mod p) mod w //hash函数,a,b参数会变化
}
}
Count-min sketch分析
- 优点:
- 空间利用率和1/ε成比例(从1/ε^2降到1/ε);
- 亚线性的更新时间
- 只需要构建相互独立的哈希函数,简单方便部署
- 这个sketch可以应用于多种应用和查询
- 所有常量都是精细且小的
- 缺点: 对于大量重复的element或top的element比较准确,但对于较少出现的element准确度比较差
现有方法及其改进
- 现有sketch方法大多是针对某个特定问题的求解,不具有普遍性
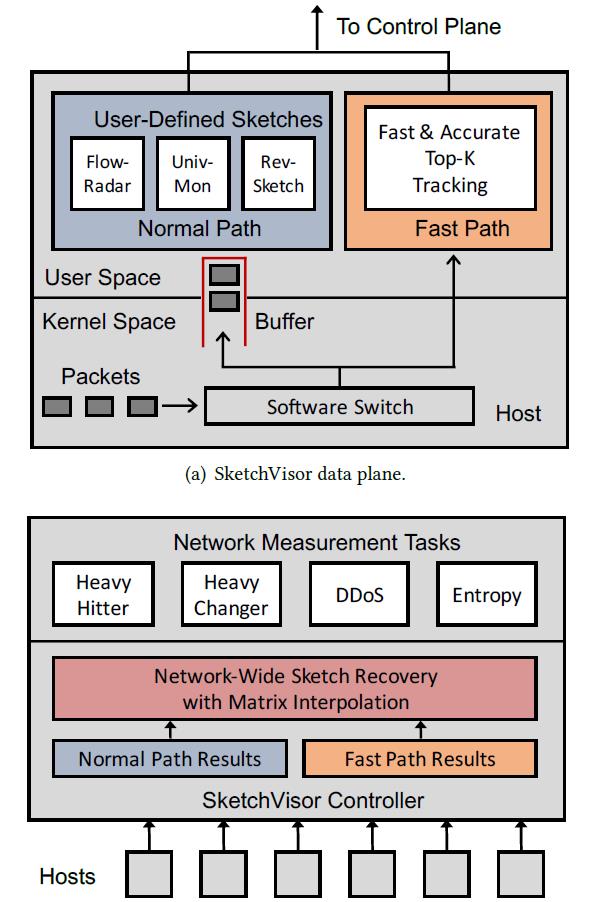
- SketchVisor可以选择多种sketch方法以应对不同种类的问题,对于过载流量,则将它导入fast path
sketch的优缺点
- 瓶颈:hash的计算开销和堆的维护开销,更新计数器和对包的头部的处理
- 优势:节省内存,理论上的可靠性
通过哈希函数的设置、减少开销
sketch检测大流
- 对流的大小设定一个阈值,当超过这个阈值时,报出大流。但是这个阈值通常是不可预知的,为了防止误报,需要检测所有可能出现的流大小,以确定这个阈值。由于需要检测的流非常多,所以在确定阈值上要花费很多时间。
总结
- Sketch是使用哈希来进行估计网络流的一种测量方法,可以减少存储开销
- Count-Min Sketch取多个哈希函数的最小哈希值作为网络流的估计,实现简单,空间开销较少
- SketchVisor可以选择多种sketch方法以应对不同种类的问题,对于过载流量,则将它导入Fast path
- 瓶颈主要在hash的计算开销、堆的维护开销、更新计数器、对包的头部的处理
- 优势主要在理论上的可靠性,节省内存
参考文献
- https://www.cnblogs.com/fxjwind/p/3289221.html
- SketchVisor: Robust Network Measurement for Software Packet Processing
- An improved data stream summary: the count-min sketch and its applications