字符级卷积神经网络(Char-CNN)实现文本分类--模型介绍与TensorFlow实现
Posted liuchongee
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了字符级卷积神经网络(Char-CNN)实现文本分类--模型介绍与TensorFlow实现相关的知识,希望对你有一定的参考价值。
本篇博客主要用于记录“Character-level Convolutional Networks for Text Classification”论文的模型架构和仿真实现方法。这是一篇2016年4月份刚发的文章,在此之前,原作者还发表过一篇“Text Understanding from Scratch”的论文,两篇论文基本上是一样的,不同之处在于后者从写了Introduction部分,然后又补充做了很多实验。第一次见到这种,还是惊呆了我自己,因为中间一章模型架构原封不动的搬移了过来,没有任何改变==好了,不多说,下面来介绍论文中所提出的模型,此外,这部分代码我将放在自己的gihub上面。
模型架构
在此之前很多基于深度学习的模型都是使用更高层面的单元对文本或者语言进行建模,比如单词(统计信息或者n-grams、word2vec等),短语(phrases),句子(sentence)层面,或者对语义和语法结构进行分析,但是本文则提出了从字符层面进行文本分类,提取出高层抽象概念。这样做的好处是不需要使用预训练好的词向量和语法句法结构等信息。除此之外,字符级还有一个好处就是可以很容易的推广到所有语言。首先看一下模型架构图:
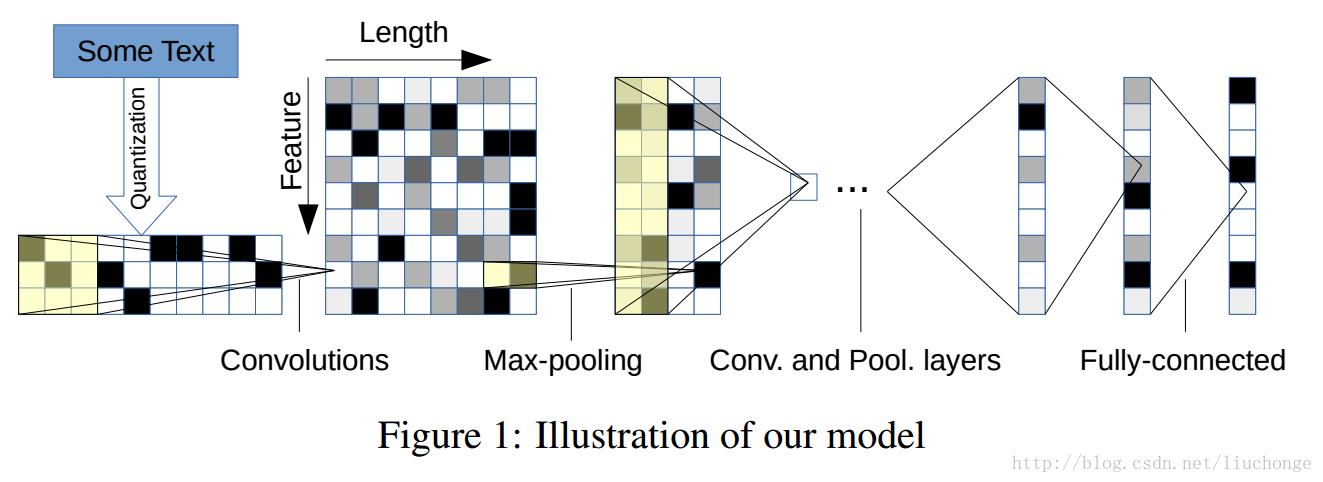
1,字符编码层
为了实现Char-CNN,首先要做的就是构建字母表,本文中使用的字母标如下,共有69个字符,对其使用one-hot编码,外加一个全零向量(用于处理不在该字符表中的字符),所以共70个。文中还提到要反向处理字符编码,即反向读取文本,这样做的好处是最新读入的字符总是在输出开始的地方。:
abcdefghijklmnopqrstuvwxyz0123456789
-,;.!?:’’’/\\|_@#$%ˆ&*˜‘+-=<>()[]2,模型卷积-池化层
文中提出了两种规模的神经网络–large和small。都由6个卷积层和3个全连接层共9层神经网络组成。这里使用的是1-D卷积神经网络。除此之外,在三个全连接层之间加入两个dropout层以实现模型正则化。其参数配置如下图所示:
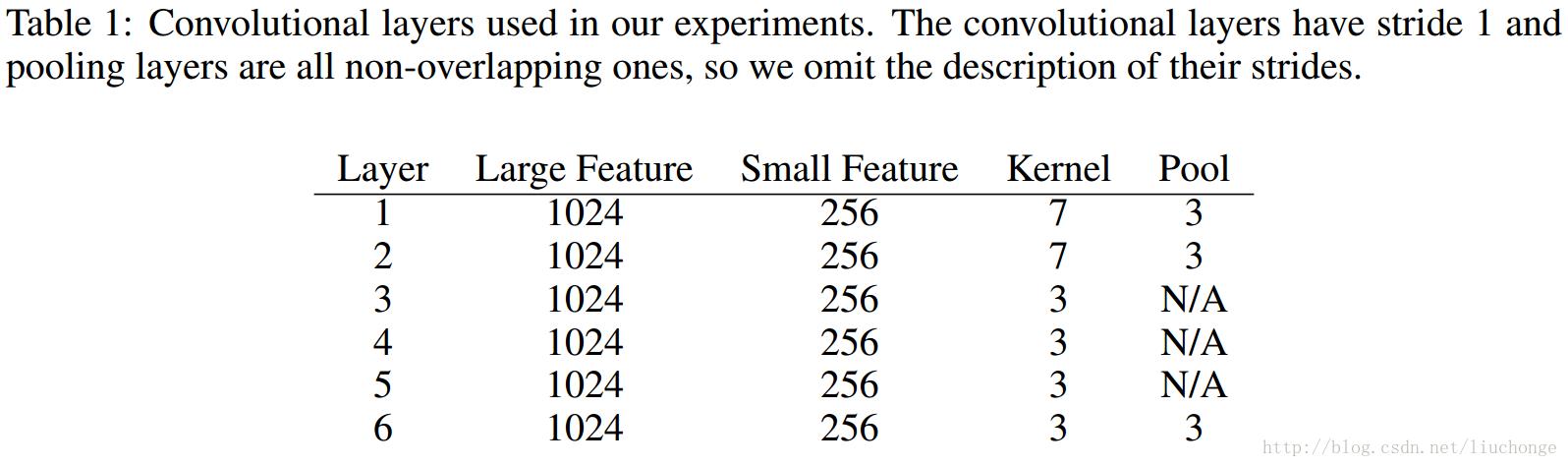

上图中第九层也就是输出层的输出单元个数没有标明,是因为针对不同任务取决于具体的类别数。
使用同义词词库替换数据集
论文中说到深度学习中为了减少模型的泛化误差,经常会对数据集进行一定程度的改动,比如说图像处理中对图片进行缩放、平移、旋转等操作不会改变图片本身含义;语音识别中对语音的声调、语速、噪声也不会改变其结果。但是在文本处理中,却不能随意挑换字符顺序,因为顺序就代表了语义。所以其提出使用同义词替换技术实现对数据集的处理。为了实现该技术,需要解决两个问题:
- 哪些词应当被替换
- 应该是用哪个同义词来替换该词
其提出以一定概率的方式随机进行选择,如下图所示,其中q和p都取0.5。但是本文不会对这部分进行代码实现。

数据集和数据预处理
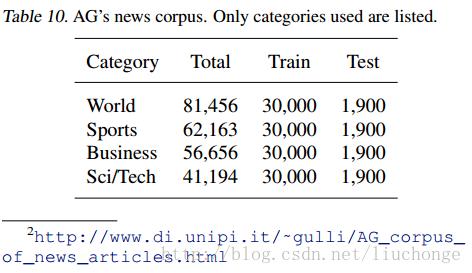
本文仿真的是AG’s news新闻分类数据集。其包含了496835个新闻,我们选择其中4个最大的类别,每个选出30000篇文章用于训练,1900篇用于测试。数据集如下图所示,每一行有三项,第一项是类别,第二项是title,第三项是描述。我们使用二三项连接起来作为训练数据,这里我们设置每天训练数据的字符长度最大为1014,所以最终每个样本数据会被转化为1014*69的矩阵传入神经网络:
数据预处理部分代码如下所示:
class Data(object):
#定义一些全局变量、超参数
def __init__(self,
data_source,
alphabet="abcdefghijklmnopqrstuvwxyz0123456789-,;.!?:'\\"/\\\\|_@#$%^&*~`+-=<>()[]",
l0=1014,
batch_size=128,
no_of_classes=4):
self.alphabet = alphabet
self.alphabet_size = len(self.alphabet)
self.dict =
self.no_of_classes = no_of_classes
for i, c in enumerate(self.alphabet):
self.dict[c] = i + 1
self.length = l0
self.batch_size = batch_size
self.data_source = data_source
def loadData(self):
data = []
with open(self.data_source, 'rb') as f:
rdr = csv.reader(f, delimiter=',', quotechar='"')
#将每行数据的二三项进行处理拼接得到文本
for row in rdr:
txt = ""
for s in row[1:]:
txt = txt + " " + re.sub("^\\s*(.-)\\s*$", "%1", s).replace("\\\\n", "\\n")
#第一项为标签,构造训练数据
data.append ((int(row[0]), txt))
self.data = np.array(data)
self.shuffled_data = self.data
def shuffleData(self):
#shufflter数据。为每次epoch打乱数据顺序
data_size = len(self.data)
shuffle_indices = np.random.permutation(np.arange(data_size))
self.shuffled_data = self.data[shuffle_indices]
def getBatchToIndices(self, batch_num=0):
#将data分成batch,并将字符转化为one-hot编码
data_size = len(self.data)
start_index = batch_num * self.batch_size
end_index = data_size if self.batch_size == 0 else min((batch_num + 1) * self.batch_size, data_size)
#获取第batch_num批数据(根据开始和结束索引)
batch_texts = self.shuffled_data[start_index:end_index]
#将单词转化为索引存储在batch_indices中
batch_indices = []
#类别的one-hot编码,一共4类
one_hot = np.eye(self.no_of_classes, dtype='int64')
classes = []
for c, s in batch_texts:
batch_indices.append(self.strToIndexs(s))
c = int(c) - 1
classes.append(one_hot[c])
return np.asarray(batch_indices, dtype='int64'), classes
def strToIndexs(self, s):
#将一个字符串进行padding并转化为索引
s = s.lower()
m = len(s)
n = min(m, self.length)
#padding
str2idx = np.zeros(self.length, dtype='int64')
for i in range(1, n):
c = s[i]
if c in self.dict:
str2idx[i] = self.dict[c]
return str2idx
#注意,上面的函数使用的是正序读入数据,也可以使用论文中提到的倒序读取数据如下所示:
def strToIndexs2(self, s):
s = s.lower()
m = len(s)
n = min(m, self.length)
str2idx = np.zeros(self.length, dtype='int64')
k = 0
for i in range(1, n+1):
c = s[-i]
if c in self.dict:
str2idx[i-1] = self.dict[c]
return str2idx
def getLength(self):
return len(self.data)经过上面的数据预处理过程,我们就可以获得batch_size*1014*70的输入数据了。
模型构建
接下来要做的就是构建我们的Char-CNN,其实代码也十分简单,因为可以直接调用TensorFlow提供好的API接口。代码入下:
class CharConvNet(object):
def __init__(self,
conv_layers = [
[256, 7, 3],
[256, 7, 3],
[256, 3, None],
[256, 3, None],
[256, 3, None],
[256, 3, 3]
],
fully_layers = [1024, 1024],
l0 = 1014,
alphabet_size = 69,
no_of_classes = 4,
th = 1e-6):
with tf.name_scope("Input-Layer"):
self.input_x = tf.placeholder(tf.int64, shape = [None, l0], name='input_x')
self.input_y = tf.placeholder(tf.float32, shape = [None, no_of_classes], name = 'input_y')
self.dropout_keep_prob = tf.placeholder(tf.float32, name="dropout_keep_prob")
with tf.name_scope("Embedding-Layer"), tf.device('/cpu:0'):
#构建look_up表,70*69的one-hot矩阵
Q = tf.concat([tf.zeros([1, alphabet_size]),tf.one_hot(range(alphabet_size), alphabet_size, 1.0, 0.0)], 0, name='Q')
#将输入转化为one-hot编码
x = tf.nn.embedding_lookup(Q, self.input_x)
x = tf.expand_dims(x, -1)
var_id = 0
for i, cl in enumerate(conv_layers):
var_id += 1
with tf.name_scope("ConvolutionLayer"):
filter_width = x.get_shape()[2].value
filter_shape = [cl[1], filter_width, 1, cl[0]]
#初始化卷积核权重参数
stdv = 1/sqrt(cl[0]*cl[1])
W = tf.Variable(tf.random_uniform(filter_shape, minval=-stdv, maxval=stdv), dtype='float32', name='W' )
b = tf.Variable(tf.random_uniform(shape=[cl[0]], minval=-stdv, maxval=stdv), name = 'b')
#卷积
conv = tf.nn.conv2d(x, W, [1, 1, 1, 1], "VALID", name='Conv')
x = tf.nn.bias_add(conv, b)
if not cl[-1] is None:
with tf.name_scope("MaxPoolingLayer" ):
pool = tf.nn.max_pool(x, ksize=[1, cl[-1], 1, 1], strides=[1, cl[-1], 1, 1], padding='VALID')
x = tf.transpose(pool, [0, 1, 3, 2]) # [batch_size, img_width, img_height, 1]
else:
x = tf.transpose(x, [0, 1, 3, 2], name='tr%d' % var_id)
with tf.name_scope("ReshapeLayer"):
#Reshape layer
vec_dim = x.get_shape()[1].value * x.get_shape()[2].value
x = tf.reshape(x, [-1, vec_dim])
weights = [vec_dim] + list(fully_layers)
for i, fl in enumerate(fully_layers):
var_id += 1
with tf.name_scope("LinearLayer" ):
#Fully-Connected layer
stdv = 1/sqrt(weights[i])
W = tf.Variable(tf.random_uniform([weights[i], fl], minval=-stdv, maxval=stdv), dtype='float32', name='W')
b = tf.Variable(tf.random_uniform(shape=[fl], minval=-stdv, maxval=stdv), dtype='float32', name = 'b')
x = tf.nn.xw_plus_b(x, W, b)
with tf.name_scope("DropoutLayer"):
x = tf.nn.dropout(x, self.dropout_keep_prob)
with tf.name_scope("OutputLayer"):
stdv = 1/sqrt(weights[-1])
W = tf.Variable(tf.random_uniform([weights[-1], no_of_classes], minval=-stdv, maxval=stdv), dtype='float32', name='W')
b = tf.Variable(tf.random_uniform(shape=[no_of_classes], minval=-stdv, maxval=stdv), name = 'b')
self.p_y_given_x = tf.nn.xw_plus_b(x, W, b, name="scores")
self.predictions = tf.argmax(self.p_y_given_x, 1)
with tf.name_scope('loss'):
losses = tf.nn.softmax_cross_entropy_with_logits(labels = self.input_y, logits = self.p_y_given_x)
self.loss = tf.reduce_mean(losses)
with tf.name_scope("Accuracy"):
# Accuracy
correct_predictions = tf.equal(self.predictions, tf.argmax(self.input_y, 1))
self.accuracy = tf.reduce_mean(tf.cast(correct_predictions, "float"), name="accuracy")模型训练和实验结果
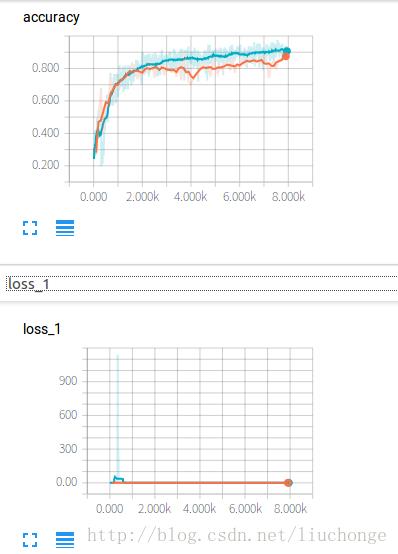
构建完模型接下来要做的工作就是训练,由于模型比较复杂,所以在自己的笔记本上跑起来很费事,一开始自己跑了很久准确率都很低,loss也一直在1.8附近徘徊,感觉是陷入了一个震荡区。但是好在放在那里让程序跑了一晚上,第二天醒来发现跑了6000多步,准确率已经达到了95以上,测试机准确度也达到了85左右,虽然仍有小幅震荡,但整体效果还会是很好的,也达到了论文中提到了85左右的准确度。训练部分代码如下所示,其实看下来很多工作都是在重复造轮子,就比如训练部分的代码,基本上和之前写的几篇差不多,首先构建模型,然后写summary,然后循环,获取数据训练。。。希望以后可以把这部分直接提出来,当然这是后话,先看代码:
import datetime
import time
import numpy as np
import tensorflow as tf
import sys
import os
import config
from data_utils import Data
from char_cnn import CharConvNet
learning_rate = 0.001
if __name__ == '__main__':
print 'start...'
execfile("config.py")
print config.model.th
print 'end...'
print "Loading data ....",
train_data = Data(data_source = config.train_data_source,
alphabet = config.alphabet,
l0 = config.l0,
batch_size = config.batch_size,
no_of_classes = config.no_of_classes)
train_data.loadData()
dev_data = Data(data_source = config.dev_data_source,
alphabet = config.alphabet,
l0 = config.l0,
batch_size = config.batch_size,
no_of_classes = config.no_of_classes)
dev_data.loadData()
num_batches_per_epoch = int(train_data.getLength() / config.batch_size) + 1
num_batch_dev = dev_data.getLength()
print "Loaded"
print "Training ===>"
with tf.Graph().as_default():
session_conf = tf.ConfigProto(allow_soft_placement = True,
log_device_placement = False)
sess = tf.Session(config = session_conf)
with sess.as_default():
char_cnn = CharConvNet(conv_layers = config.model.conv_layers,
fully_layers = config.model.fully_connected_layers,
l0 = config.l0,
alphabet_size = config.alphabet_size,
no_of_classes = config.no_of_classes,
th = config.model.th)
global_step = tf.Variable(0, trainable=False)
optimizer = tf.train.AdamOptimizer(learning_rate)
grads_and_vars = optimizer.compute_gradients(char_cnn.loss)
train_op = optimizer.apply_gradients(grads_and_vars, global_step = global_step)
# Keep track of gradient values and sparsity (optional)
grad_summaries = []
for g, v in grads_and_vars:
if g is not None:
grad_hist_summary = tf.summary.histogram("/grad/hist".format(v.name), g)
sparsity_summary = tf.summary.scalar("/grad/sparsity".format(v.name), tf.nn.zero_fraction(g))
grad_summaries.append(grad_hist_summary)
grad_summaries.append(sparsity_summary)
grad_summaries_merged = tf.summary.merge(grad_summaries)
# Output directory for models and summaries
timestamp = str(int(time.time()))
out_dir = os.path.abspath(os.path.join(os.path.curdir, "runs", timestamp))
print("Writing to \\n".format(out_dir))
# Summaries for loss and accuracy
loss_summary = tf.summary.scalar("loss", char_cnn.loss)
acc_summary = tf.summary.scalar("accuracy", char_cnn.accuracy)
# Train Summaries
train_summary_op = tf.summary.merge([loss_summary, acc_summary, grad_summaries_merged])
train_summary_dir = os.path.join(out_dir, "summaries", "train")
train_summary_writer = tf.summary.FileWriter(train_summary_dir, sess.graph_def)
# Dev summaries
dev_summary_op = tf.summary.merge([loss_summary, acc_summary])
dev_summary_dir = os.path.join(out_dir, "summaries", "dev")
dev_summary_writer = tf.summary.FileWriter(dev_summary_dir, sess.graph_def)
# Checkpoint directory. Tensorflow assumes this directory already exists so we need to create it
checkpoint_dir = os.path.abspath(os.path.join(out_dir, "checkpoints"))
checkpoint_prefix = os.path.join(checkpoint_dir, "model")
if not os.path.exists(checkpoint_dir):
os.makedirs(checkpoint_dir)
saver = tf.train.Saver(tf.all_variables())
sess.run(tf.global_variables_initializer())
def train_step(x_batch, y_batch):
feed_dict =
char_cnn.input_x: x_batch,
char_cnn.input_y: y_batch,
char_cnn.dropout_keep_prob: config.training.p
_, step, summaries, loss, accuracy = sess.run(
[train_op,
global_step,
train_summary_op,
char_cnn.loss,
char_cnn.accuracy],
feed_dict)
time_str = datetime.datetime.now().isoformat()
print(": step , loss :g, acc :g".format(time_str, step, loss, accuracy))
train_summary_writer.add_summary(summaries, step)
def dev_step(x_batch, y_batch, writer=None):
feed_dict =
char_cnn.input_x: x_batch,
char_cnn.input_y: y_batch,
char_cnn.dropout_keep_prob: 1.0 # Disable dropout
step, summaries, loss, accuracy = sess.run(
[global_step,
dev_summary_op,
char_cnn.loss,
char_cnn.accuracy],
feed_dict)
time_str = datetime.datetime.now().isoformat()
print(": step , loss :g, acc :g".format(time_str, step, loss, accuracy))
if writer:
writer.add_summary(summaries, step)
for e in range(config.training.epoches):
print e
train_data.shuffleData()
for k in range(num_batches_per_epoch):
batch_x, batch_y = train_data.getBatchToIndices(k)
train_step(batch_x, batch_y)
current_step = tf.train.global_step(sess, global_step)
if current_step % config.training.evaluate_every == 0:
xin, yin = dev_data.getBatchToIndices()
print("\\nEvaluation:")
dev_step(xin, yin, writer=dev_summary_writer)
print("")
if current_step % config.training.checkpoint_every == 0:
path = saver.save(sess, checkpoint_prefix, global_step=current_step)
print("Saved model checkpoint to \\n".format(path)) 不再对代码进行过多的解释,直接看实验结果吧,由第一张图可以看出其测试集和训练集的准确度都已经接近达到了论文中的精度,但是剩下的两张权重图究竟是什么含义自己一直都还没有搞清楚,究竟怎样的图才是表明训练过程是正确的呢==:

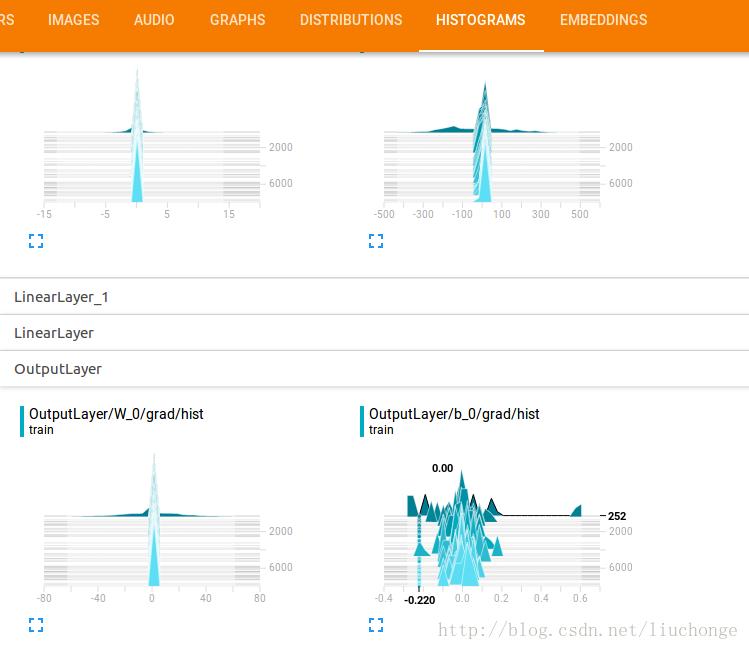
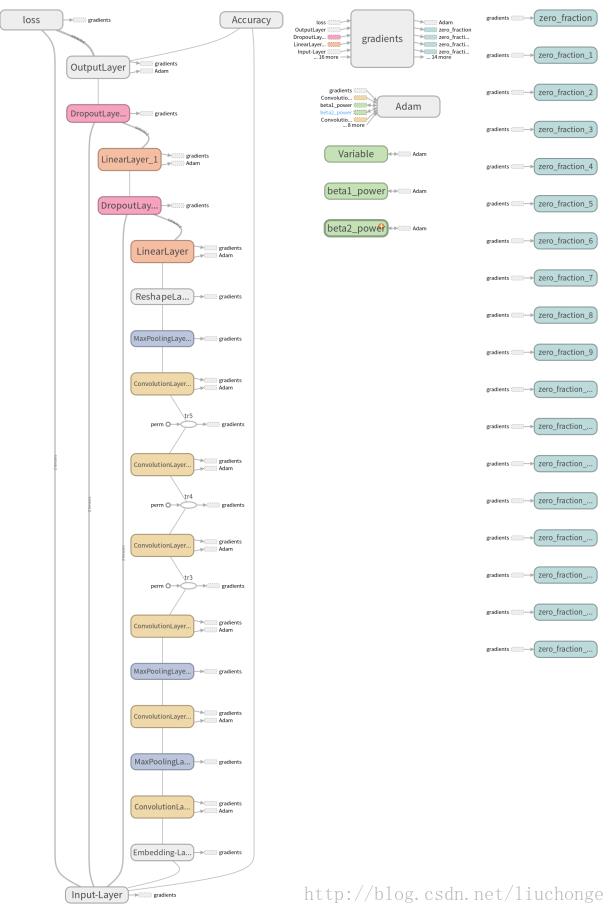
以上是关于字符级卷积神经网络(Char-CNN)实现文本分类--模型介绍与TensorFlow实现的主要内容,如果未能解决你的问题,请参考以下文章