Web服务器如何实现高吞吐低延迟?Dropbox从操作系统到应用层优化指南
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Web服务器如何实现高吞吐低延迟?Dropbox从操作系统到应用层优化指南相关的知识,希望对你有一定的参考价值。
Web服务器如何实现高吞吐低延迟?Dropbox从操作系统到应用层优化指南
导读:本文是 Dropbox 对其如何优化网络延迟问题的经验总结。本文内容覆盖了从硬件选型到 Web 服务器优化的整个技术栈,值得大家收藏深入学习。
这是我在 2017 年 9 月 6 日在 nginxConf 2017 上演讲的扩展版。作为 Dropbox Traffic Team 的 SRE,我负责边缘网络优化,主要包括可靠性,性能和效率。 Dropbox 边缘网络 [1] 基于 Nginx 代理,旨在处理延迟敏感的元数据事务和高吞吐量数据传输。 在处理数万个延迟敏感事务的同时,处理数以千计的延迟敏感事务,在整个技术栈中,从对驱动程序和中断,到 TCP/IP 和内核还有库和应用程序进行效率/性能优化。
免责声明
在这篇文章中,我们将讨论很多调整 Web 服务器的方法。你需要使用科学的方法测量它们的效果,并确定在你的环境中是否确实起作用。
这不是一篇有关 Linux 性能调优的文章,即使我将对 bcc 工具, eBPF[2] 和 perf 进行大量的引用,这绝对不是使用性能分析工具的综合指南。 如果您想了解更多信息,您可能需要阅读 Brendan Gregg 的博客 [3]。
这也不是专注于浏览器性能的帖子。 在覆盖延迟相关的优化时,我将会触及客户端的性能,但只能简单地介绍。 如果您想了解更多,您应该阅读 Ilya Grigorik 的“ 高性能浏览器网络” [4] 。
而且,这也不是 TLS 最佳实践汇编。 虽然我会提到一些 TLS 库及其设置,您和您的安全小组应评估其中每一个修改和设置的性能以及安全性。 您可以使用 Qualys SSL Test [5],根据当前的最佳做法来进行验证,如果您想了解更多关于 TLS 的信息,请考虑订阅 Feisty Duck Bulletproof TLS 通讯 [6]。
本文结构
我们将讨论系统在不同层次上的效率/性能优化。 从硬件和驱动程序开始(这些调优可以几乎应用于任何高负载服务器), 到 Linux 内核及其 TCP / IP 协议栈(在任何使用 TCP / IP 协议栈的应用都可以尝试),最后我们将讨论库和应用程序级别的调整(这些调整主要适用于一般的 Web 服务器和 Nginx)。
对于每个潜在的优化领域,我将尝试给出延迟/吞吐量权衡,监控指南以及最后针对不同工作负载的调整建议。
硬件
(对硬件调优不感兴趣的读者可以直接跳到操作系统部分)
CPU
如果需要提高非对称 RSA / EC 的性能,则需要至少具有 AVX2( avx2 in /proc/cpuinfo )支持的处理器,最适合的是具有大整数运算 [7] 能力的硬件(支持 bmi 和 adx )的处理器。 对于对称加密的情况,需要支持 AES-NI(针对 AES)和 AVX512(针对 ChaCha + Poly)的硬件。 英特尔有一个针对 OpenSSL 1.0.2 在不同硬件产品性能比较 。
延迟敏感的场景,将受益于更少的 NUMA 节点和禁用 HT。 高吞吐量的任务在多核心上运行得更好,并且将受益于超线程(除非它们具有缓存限制),并且通常不会关心 NUMA。
具体来说,如果选用英特尔硬件,你至少要找 Haswell / Broadwell(理想情况需要 Skylake CPU)。 如果您正在使用 AMD, EPYC 的表现非常好。
NIC
在这里你至少要找 10G,最好甚至 25G。 如果您想通过单个服务器 (TLS) 进行推送,则此处所述的调整将不够,您可能需要将 TLS 框架调整进入内核级别(例如 FreeBSD , Linux )。
在软件方面,您应该查找具有活动邮件列表和用户社区的开源驱动程序。 如果您将调试与驱动程序有关的问题,这非常重要。
内存
这里的经验法则是延迟敏感的任务需要更快的内存,而吞吐量敏感的任务需要更多的内存。
硬盘
这取决于您的缓冲/缓存要求,但如果要缓存很多文件,您应该使用闪存。 有些甚至使用专门的 Flash 友好的文件系统(通常是日志结构的),但是它们未必比普通的 ext4 / xfs 更好。
无论如何,请不要因为您忘记了启用 TRIM 或更新固件而引起一些故障。
操作系统:低级别
固件
您应该保持您的固件是最新的,以避免痛苦和冗长的故障排除过程。 尝试使用最新的 CPU 微码,主板,网卡和固态硬盘的固件。 这并不意味着你需要保持最新固件,这里的经验法则是运行次新固件,除非它在最新版本中修复了严重错误。
驱动程序
这里的更新规则与固件几乎相同。 尽量保持次新的状态。 这里的一个注意事项是尝试将内核升级与驱动程序更新分离。 例如,您可以使用 DKMS 打包驱动程序,也可以为您使用的所有内核版本预先编译驱动程序。 这样当您更新内核并且某些功能无法正常工作时,您只需少量处理故障。
CPU
这里最好的助力是内核仓库和工具。 在 Ubuntu/Debian 中,您可以安装 Linux-tools 软件包,其中包含几个 Linux-tools ,但现在我们只使用 cpupower, x86_energy_perf_policy 和 x86_energy_perf_policy 。 为了验证与 CPU 相关的优化,您可以使用自己喜欢的负载生成工具(例如, Yandex 使用 Yandex.Tank )对软件进行压力测试。以下是来自开发人员的最新 NginxConf 的演示文稿,介绍了有关 Nginx loadtesting 最佳做法的内容:“Nginx 性能测试” [7] 。
cpupower
使用这个工具比抓取 /proc/ 更容易。 要查看有关您的处理器及其调速器的信息:
检查是否启用了 Turbo Boost,对于 Intel CPU,请确保您正在运行 intel_pstate ,而不是 acpi-cpufreq ,甚至是 pcc-cpufreq 。 如果您仍然使用 acpi-cpufreq ,那么您应该升级内核,否则可能会导致使用 performance 调节器。 当使用 intel_pstate 运行时,甚至 intel_pstate 应该表现得更好,但是您需要自己验证。
说到空闲,看看 CPU 发生了什么改变,你可以使用 turbostat 直接查看处理器的MSR并获取电源,频率和空闲状态信息:
在这里,您可以看到实际的 CPU 频率, 以及核心/包空闲状态 。
如果即使使用intel_pstate驱动程序,CPU 会花费比您想象的更多的空闲时间,您可以:
- 将 governor 设为 performance 。
- 将 x86_energy_perf_policy 设置为性能模式。
或者,只有对于非常延迟的关键任务,您可以:
- 使用 /dev/cpu_dma_latency 接口。
- 对于 UDP 流量,请使用 busy-polling 。
您可以从 LinuxCon Europe 2015 了解更多关于处理器电源管理和P状态相关资料,特别是英特尔 OpenSource 技术中心演示文稿“ 平衡 Linux 内核中的功能和性能 ”。
CPU 亲和性
您可以通过在每个线程/进程上应用 CPU 关联来额外减少延迟,例如,nginx 具有 worker_cpu_affinity 指令,可以将每个 Web 服务器进程自动绑定到其自身的核心。 这应该可以消除CPU迁移,减少高速缓存未命中和页面缺失。 所有这一切都可以通过 perf stat 验证。
可悲的是,启用亲和力也可能会因为增加进程花费等待可用 CPU 的时间量来对性能产生负面影响。 这可以通过在您的一个 nginx 工作者的 PID 上运行 runqlat 进行监控: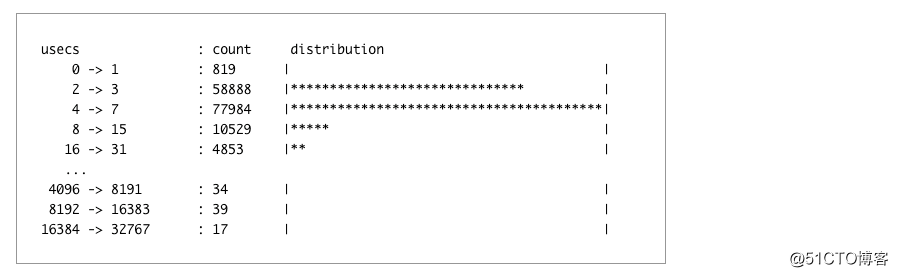
如果您看到多毫秒的尾部延迟,那么除了 nginx 本身之外,您的服务器上可能还有太多东西,而CPU亲和力会增加延迟,而不是减少它。
内存
所有内存调优通常是通用的,只有几件事要推荐:
- 将 THP 设置为 madvise 并且只有确定它们是有益的时候才能使用它们 ,否则可能会减速一个数量级。
- 除非您只使用一个 NUMA 节点,否则您应该将 vm.zone_reclaim_mode 设置为 0. ## NUMA
现代 CPU 实际上是通过非常快速的互连连接的多个独立的 CPU,并且共享各种资源,从 HT 内核上的 L1 缓存开始,到 L3 缓存,到插槽内的内存和 PCIe 链路。这基本上是 NUMA:具有快速互连的多个执行和存储单元。
有关 NUMA 及其影响的综合概述,请参阅 Frank Denneman 的系列文章。
然而长话短说,你可以选择:
- 忽略它 ,通过在Bios中禁用它或在numactl --interleave=all下运行您的软件,。
- 拒绝它,通过使用单节点服务器, 就像Facebook的OCP Yosemite platform 。
- 拥抱它,通过优化CPU/内存放置在用户和内核空间。
让我们来谈谈第三个选择,因为前两个没有太多的优化空间。
要正确使用 NUMA,您需要将每个 numa 节点视为单独的服务器,因为您应该首先检查拓扑,这可以通过 numactl --hardware 来完成:
需要考虑到:
- 节点数量
- 每个节点的内存大小。
- 每个节点的CPU数量。
- 节点之间的距离。
这是一个特别糟糕的例子,因为它有4个节点以及没有连接内存的节点。 在不牺牲系统一半内核的情况下,将每个节点视为单独的服务器是不可能的。
我们可以通过使用numastat来验证: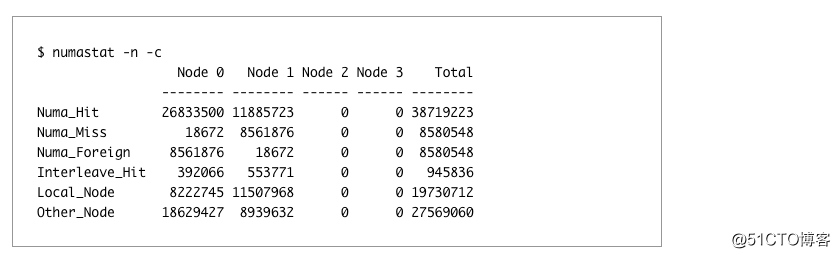
您还可以要求 numastat 以 /proc/meminfo 格式输出每节点内存使用情况统计信息:
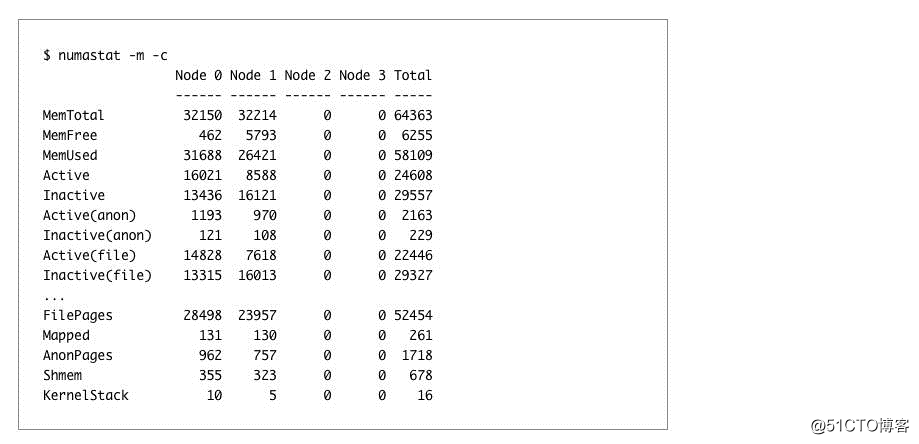
现在看看一个更简单拓扑的例子。
由于节点大部分是对称的,所以我们可以使用 numactl --cpunodebind=X --membind=X 将每个 NUMA 节点的应用程序绑定到另一个端口上,这样可以利用两个节点获得更好的吞吐量并通过保留内存局部性来优化延迟。
您可以通过延迟内存操作来验证 NUMA 布局效率,例如通过使用 bcc 的 funclatency 来测量内存重操作的延迟,例如 memmove 。
在内核方面,您可以通过使用 perf stat 查看效率,并查找相应的内存和调度程序事件:
针对网络繁重工作负载的 NUMA 相关优化的最后一点是,网卡是 PCIe 设备,每个设备都绑定到其自己的 NUMA 节点,因此一些 CPU 在与网络通话时具有较低的延迟。 当我们讨论 NIC/CPU 亲和性时,我们将讨论可以应用于此的优化,但现在可以将交换机切换到 PCI-Express。
PCIe
通常,除非您有某种硬件故障,否则您不需要太深入研究 PCIe 故障排除 。通过为您的 PCIe 设备创建“链路宽度”,“链路速度”以及可能的 RxErr / BadTLP 警报,可以节省您的故障排除时间。 您可以使用 lspci :
如果您有多个高速设备竞争带宽(例如,将快速网络与快速存储组合在一起)时,PCIe可能会成为一个瓶颈,因此您可能需要通过CPU物理分割PCIe设备以获得最大的吞吐量。
另请参阅 Mellanox 网站上的文章“了解最佳性能的 PCIe 配置”,这将进一步深入到 PCIe 配置中,如果您在网卡和操作系统之间观察到数据包丢失,在更高的速度下本文会有所帮助。
英特尔指出有时 PCIe 电源管理(ASPM)可能导致更高的延迟,从而导致更高的数据包丢失。 您可以通过将 pcie_aspm=off 添加到内核 cmdline 来禁用它。
NIC
在我们开始之前,值得一提的是, Intel和Mellanox都有自己的性能调优指南,无论您选择哪种供应商,阅读它们都是有益的。 驱动程序通常还有自己的README和一组有用的实用程序。
操作系统手册也需要仔细阅读,例如“红帽企业Linux网络性能调优指南”,它解释了下面提到的大多数优化。
Cloudflare 还有一篇关于调整网络堆栈的一部分的好文章 ,尽管它主要针对低延迟的用例。
当优化 NIC 时,ethtool 非常有帮助。
这里的一个小笔记:如果您使用的是较新的内核,对于网络操作,您可能需要更新版本的ethtool , iproute2和iptables / nftables软件包。
可以通过 ethtool -S 了解网卡上发生的动作:
请咨询您的NIC制造商了解详细的统计描述,例如Mellanox 为他们提供专门的维基页面。
从内核方面看,你会看到 /proc/interrupts, /proc/softirqs 和 /proc/net/softnet_stat。 这里有两个有用的 bcc 工具: hardirqs 和 softirqs 。 您优化网络的目标是调整系统,直到您的 CPU 使用率最少,同时没有丢包。
中断亲和性
这里的调优通常是从处理器间扩展中断开始。 你应该如何具体地调整取决于你的目标:
- 为了最大的吞吐量,您可以在系统中的所有NUMA节点上分配中断。
- 为了最小化延迟,您可以将中断限制到单个NUMA节点。 要做到这一点,您可能需要减少队列数以适应单个节点(这通常意味着用ethtool -L将其数量减少一半)。
供应商通常提供脚本来做到这一点,例如 Intel 有 set_irq_affinity 。
缓冲区大小
网卡需要与内核交换信息。 这通常通过称为“环”的数据结构完成,通过ethtool -g查看该环的当前/最大大小:
您可以使用 -G 调整这些预设值。 一般来说,数值越大越好,因为它将为您提供更多的针对突发性保护,从而减少由于没有缓冲区空间/错过中断而导致的丢弃数据包的数量。 但有几个注意事项:
- 在旧的内核或没有 BQL 支持的驱动程序上,高值可能导致 tx 端的更高的缓冲区。
- 更大的缓冲区也会增加缓存压力 ,所以如果你遇到了,请尝试降低它们。
Coalescing 聚合
中断合并允许您通过在单个中断中聚合多个事件来延迟内核关于新事件的通知。 当前设置可以通过 ethtool -c 查看:
您可以使用静态限制,硬限制每个内核每秒中断的最大数量,或者取决于硬件根据吞吐量自动调整中断速率 。
启用合并(使用 -C )将增加延迟并可能引入数据包丢失。 另一方面,完全禁用它可能导致中断限制,从而限制您的性能。
Offloads
现代网卡比较聪明,可以将大量的工作卸载到硬件或驱动程序本身。
所有可能的卸载都可以用 ethtool -k 获得:
在输出中,所有不可调的卸载都标有[fixed]后缀。
这里有一些经验法则:
- 不要启用 LRO,而是使用 GRO。
- 对 TSO 要谨慎,因为它高度依赖于您的驱动程序/固件的质量。
- 不要在旧的内核上启用 TSO / GSO,因为它可能会导致过多的缓冲区。 所有现代 NIC 都针对多核硬件进行了优化 ,因此内部将数据包分为虚拟队列,通常为每个 CPU 一个。 当它在硬件中完成时,称为 RSS,当 OS 负责 CPU 间的数据包负载均衡时,称为 RPS(其 TX 对应物称为 XPS)。 当操作系统也试图智能化并且路由流程到当前处理该套接字的 CPU 时,称为 RFS。 当硬件这样做时,它被称为“加速 RFS”或简称为 aRFS。
以下是我们生产中的几种最佳做法:
- 您正在使用较新的 25G+ 硬件,它可能具有足够的队列和巨大的间接表,以便能够在所有内核上进行 RSS。 一些较旧的网卡具有仅使用前 16 个 CPU 的局限性。
- 您可以尝试通过以下方式启用 RPS:
- 如果您正在使用较新的 25G+ 硬件,它可能具有足够的队列和巨大的间接表,以便能够在所有内核中使用 RSS 。 一些较旧的网卡具有仅使用前 16 个CPU的局限性。
- 您可以尝试启用 RPS :
- 您具有比硬件队列更多的CPU,并且您要牺牲吞吐量的延迟。
- 您正在使用内部隧道(例如 GRE / IPinIP),NIC 不能 RSS;
- 如果您的CPU相当旧且没有 x2APIC,请勿启用 RPS 。
- 通过 XPS 将每个 CPU 绑定到自己的 TX 队列通常是一个好主意。
- RFS 的有效性高度依赖于您的工作负载,以及是否对其应用 CPU 亲和性。
Flow Director 和 ATR
启用 flow director(或英特尔术语中的 fdir ) 默认情况下在应用程序定向路由模式下运行,该模式通过将数据包和转向流采样到实际处理核心的方式实现 aFS 。 它的统计数据也可以通过 ethtool -S 看到。
虽然英特尔声称 fdir 在某些情况下会提高性能,但外部研究表明, 它还可以引入高达 1% 的数据包重新排序 ,这对 TCP 性能来说可能是非常有害的。 因此,请测试该特性,并查看 FD 是否对您的工作负载有用,同时注意 TCPOFOQueue 计数器。
操作系统:网络栈
有无数的书籍,视频和教程来调优 Linux 网络栈。 最近的内核版本不需要像 10 年前那样运行那么多的调整,大多数新的 TCP / IP 功能默认启用和调优,但是人们仍然将其古老的 sysctls.conf 复制粘贴到新内核。
为了验证网络相关优化的有效性,您应该:
- 通过 /proc/net/snmp 和 /proc/net/netstat 收集系统级 TCP 指标。
- 从 ss -n --extended --info getsockopt( TCP_INFO ) 或从您的网络服务器内调用getsockopt( TCP_INFO ) / getsockopt( TCP_CC_INFO ) 获取的每个连接的总体度量指标。
- tcptrace (1)采样 TCP 流。
- 从应用/浏览器分析 RUM 指标。
关于网络优化的信息来源,我通常会喜欢和做 CDN 人一起交谈,因为他们一般都知道他们正在做什么 。 聆听 Linux 内核开发人员对网络的看法也是非常有启发性的 。
值得一提的是,由 PackageCloud 强调了对 Linux 网络堆栈的深入了解,特别是因为它们将监控重点放在监控上,而不是盲目调整:
- 监控和调优 Linux 网络堆栈:接收数据
- 监控和调优 Linux 网络堆栈:发送数据
在我们开始之前,让我再说一遍: 升级你的内核 ! 因为新版内核有大量新的网络堆栈改进。 我正在谈论的新热点如:TSO 自动化,FQ,TLP 和 RACK 等。 通过升级到新内核,您将获得一系列可扩展性改进,例如: 删除路由缓存 , 无锁监听套接字 , SO_REUSEPORT 等等 。
概观
从最近的 Linux 网络文章中,脱颖而出的是“ 快速制作 Linux TCP ”,它通过将 Linux 发送端的 TCP 协议栈分解成功能块,将 4 年内的 Linux 内核改进整合在一起: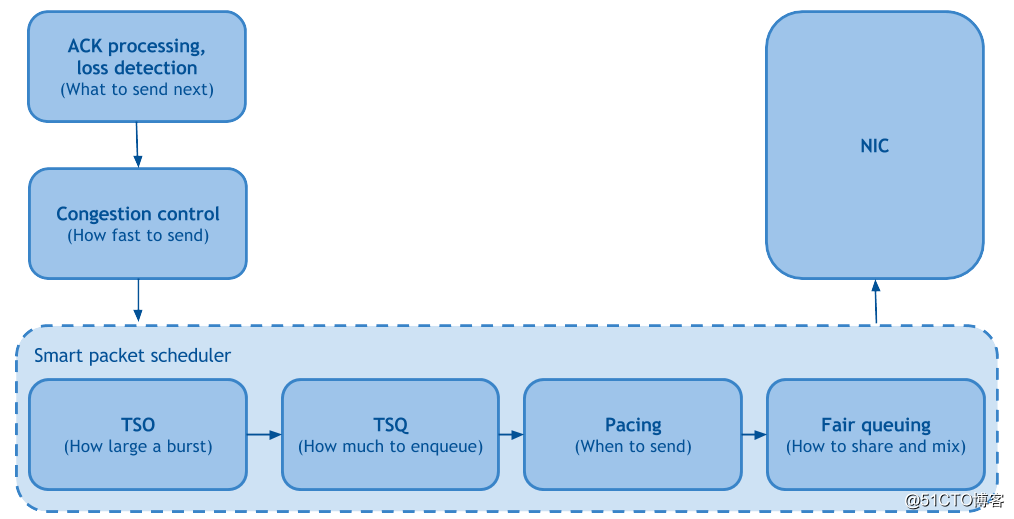
公平排队和 Pacing
公平排队负责提高公平性,减少TCP流之间的线路阻塞,从而对数据包丢失率产生积极的影响。 起搏通过拥塞控制设置的速率调度分组,时间间隔相等,从而进一步减少数据包丢失,从而提高吞吐量。
作为附注:公平排队和 Pacing 可通过 fq qdisc 在 linux 中使用。 有些人可能知道这些是 BBR 的要求,但是它们都可以与 CUBIC 一起使用,从而可以降低 15-20% 的丢包率,从而降低基于丢失的 CC 的吞吐量。 只是不要在旧的内核(<3.19)中使用它。
TSO 自动化和 TSQ
这两者都负责限制TCP堆栈内的缓冲,从而减少延迟,而且不会牺牲吞吐量。
拥塞控制
CC算法本身就是一个很大课题。 这里是其中一些: tcp_cdg ( CAIA ), tcp_nv (Facebook)和 tcp_bbr (Google)。 我们不会太深入讨论他们到底是如何工作的,我们只要说所有这些都更依赖于延迟增加。
BBR 可以说是所有新的拥塞控制中最实用的。 基本思想是基于分组传输速率创建网络路径的模型,然后执行控制环路以最大化带宽,同时最小化 rtt。 这正是我们寻求已久的。
我们的边缘 PoP 上 BBR 实验的初步数据显示文件下载速度有所增加: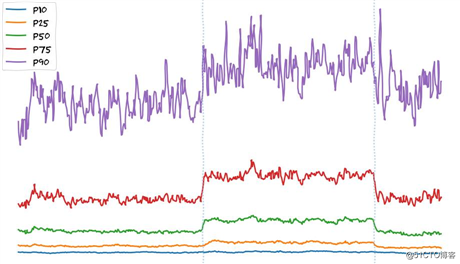
东京6小时TCP BBR实验PoP:x轴 - 时间,y轴 - 客户端下载速度
在这里我想强调,我们观察到有明显的速度增长。 后端更改不是这样。 这些通常只会惠及p90 +用户(互联网连接速度最快的用户),因为我们认为所有其他用户已经被限制了带宽。 诸如改变拥塞控制或启用FQ /起搏的网络级调优表明,用户没有受到带宽的限制,但如果我能这么说,它们是“TCP限制的”。
如果您想了解更多有关BBR的信息, APNIC有一个良好的入门级概述 (以及与丢失的拥塞控制的比较)。 有关BBR的更多详细信息,您可能需要阅读bbr-dev邮件列表存档。 对于一般对拥塞控制感兴趣的人来说,跟踪拥塞控制研究小组活动可能很有趣。
ACK处理和丢失检测
足够的拥塞控制之后,让我们来谈谈关于丢失检测的问题,这里运行最新的内核将会有所帮助。 新的启发式算法如TLP和RACK非常游泳。它们将默认启用,因此您不需要在升级后调整任何系统设置。
用户空间优先级和HOL
用户空间 socket API 提供隐式缓冲,并且无法在发送之后重新排序块,因此在多路复用方案(例如 HTTP/2)中,这可能导致 HOL 阻塞和 h2 优先级的反转。TCP_NOTSENT_LOWAT 套接字选项(和相应的 net.ipv4.tcp_notsent_lowat sysctl) 旨在通过设置阈值来解决这个问题 (即epoll会对您的应用程序造成的影响)。 这可以解决 HTTP/2 优先级排序的问题,但也可能会对吞吐量造成负面影响,因此您可以自己的情况评估。
sysctl
没有提到需要调整的sysctl,不能简单地进行网络优化。 但是让我先从你不想触摸的东西开始:
- net.ipv4.tcp_tw_recycle=1 - 不要使用 。
- net.ipv4.tcp_timestamps=0不要禁用它们,除非您知道所有副作用,并且您可以使用它们。
至于您应该使用的sysctls:
- net.ipv4.tcp_slow_start_after_idle=0 - 空闲之后的缓慢启动的主要问题是“空闲”被定义为一个太小的RTO。
- net.ipv4.tcp_mtu_probing=1 - 如果您和您的客户端之间存在ICMP黑洞 (很可能存在),则很有用。
- net.ipv4.tcp_rmem , net.ipv4.tcp_wmem应该调整为适合BDP。
- echo 2 > /sys/module/tcp_cubic/parameters/hystart_detect - 如果您使用fq + cubic,这可能有助于tcp_cubic过早退出慢启动 。
还值得注意的是,Daniel Stenberg的RFC草案(尽管有点不活跃),名为TCP Tuning for HTTP ,它试图将所有可能对HTTP有利的系统调整集中在一个地方。
应用程度:中级
工具
就像内核一样,拥有最新的用户空间非常重要。 您应该开始升级您的工具,例如您可以打包更新版本的 perf , bcc 等。
一旦你有了新的工具,就可以正确调整和观察系统的行为了。 通过这一部分的帖子,我们将主要依靠从头到尾的简单剖析 , CPU 上的火焰图以及来自 bcc 的 adhoc 直方图。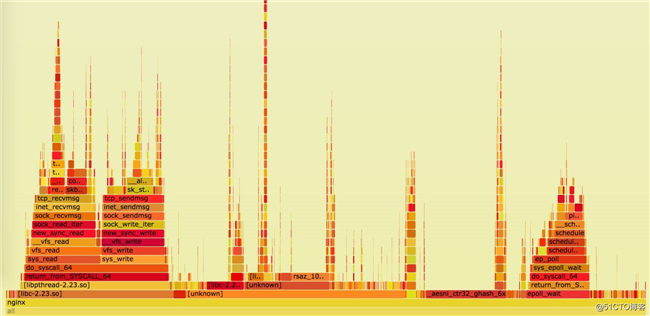
编译器工具链
如果您要编译硬件优化的程序集,那么使用现代化的编译器工具链是至关重要的,该程序集存在于Web服务器通常使用的许多库中。除了性能之外,较新的编译器还具有新的安全功能。
系统库
它也值得升级系统库,如glibc,因为否则你可能会错过最近在-lc , -lm , -lrt等的低级函数中进行的优化 。
Zlib
通常Web服务器将负责压缩。 根据代理服务器的数据量,您可能会偶尔在perf top看到zlib,例如:
有一些优化方法可以在最低级别进行优化: 英特尔和Cloudflare以及独立的zlib-ng项目都有其zlib分支,通过使用新的指令集来提供更好的性能。
malloc
在讨论到目前为止的优化之前,我们一直主要面向CPU,但是我们来讨论与内存相关的优化。 如果您使用大量的Lua与FFI或重的第三方模块进行自己的内存管理,则可能会因为碎片而观察到内存使用量增加。 您可以尝试通过切换到jemalloc或tcmalloc来解决该问题。
使用自定义 malloc 也有以下好处:
- 将 nginx 二进制文件与环境分开,以便 glibc 版本升级和操作系统迁移会影响更少。
- 更好的反思 , 分析和统计 。
如果您在 nginx 配置中使用了许多复杂的正则表达式,或者很大程度上依赖于 Lua,则可能会在 perf top 看到 pcre 相关的符号。 您可以通过使用 JIT 编译 PCRE 来优化,也可以通过pcre_jit on;在nginx中进行pcre_jit on; 。
您可以通过查看火焰图或使用funclatency来检查优化结果:
TLS
TLS性能优化可能非常有价值。 我们将着重讨论调优服务器端的效率。
所以现在您需要决定使用哪个TLS库:Vanilla OpenSSL ,OpenBSD的LibreSSL或Google的BoringSSL 。 选择TLS库后,您需要正确构建它:例如,OpenSSL具有一堆内置启动模式,可根据构建环境进行优化 ; BoringSSL具有确定性的构建,但可悲的是,这种方式更保守,并且默认情况下禁用一些优化 。 无论如何,这里选择现代CPU应该终于得到回报:大多数TLS库可以利用AES-NI和SSE到ADX和AVX512等硬件加速。 您可以使用TLS库附带的内置性能测试,例如BoringSSL的bssl speed 。
大多数的性能提升不是来自你的硬件,而是来自您将要使用的密码套件,因此您必须仔细地优化它们。这里的变化可以影响您的Web服务器,最快的密码套件的安全性并不一定是最好的。如果不确定是什么加密设置来使用,Mozilla的SSL配置生成器是一个良好的开端。
非对称加密
如果你的服务上的优势,那么你可能会发现相当数量的TLS握手,因此有你的CPU通性能在非对称加密上会有很大的消耗,优化这里就成了我们的目的。
为了优化服务器端的CPU使用可以切换到ECDSA证书,其通常比10倍RSA快。ECDSA比较小,因此可以加速加速握手。但ECDSA也严重依赖于系统的随机数发生器的质量,因此,如果您正在使用OpenSSL,确保有足够的熵(如果使用BoringSSL 你不必担心)。
作为一个侧面说明,但值得一提的是更大的并不总是更好,例如使用RSA 4096个将证降低一个数量级的性能指标:
更糟糕的是,小的不一定是最好的选择之一:通过使用非公共P-224场为ECDSA你会相比,更常见的P-256得到更糟糕的表现:60%
这里的经验法则是,最常用的加密通常是最优化的。
当运行适当优化OpenTLS(基于库的使用RSA证书),你应该会看到下面的痕迹perf top:AVX2能力,但没有ADX 的CPU(如Haswell的)应该使用AVX2代码路径:
新的硬件应该使用一个通用的蒙哥马利乘法ADX代码路径:
对称加密
如果您有批量转让的大量的如视频,照片,或更一般的文件,那么你可以开始观察分析器的输出对称加密符号。在这里,你只需要确保你的CPU有AES-NI支持,并且您设置了服务器端的喜好AES-GCM密码。适当调整硬件应该有以下perf top:
不仅是你的服务器需要处理的加密/解密,客户端也能够减小CPU消耗。如果没有硬件加速,这可能是非常具有挑战性的,因此,你可以考虑使用被设计成无需硬件加速快的算法,如ChaCha20-Poly1305。
ChaCha20-Poly1305在BoringSSL支持开箱即用,使用OpenSSL 1.0.2的话可以考虑使用CloudFlare的补丁。BoringSSL还支持“ 具有相同的优先密码组 ”,所以您可以使用下面的配置,让客户决定根据自己的硬件功能决定:
应用程序级别:高层
要分析该级别的优化效果,你需要收集 RUM 数据。在浏览器中,你可以使用 Navigation Timing APIs 和 Resource Timing APIs。你的主要指标 TTFB 和 TTV / TTI。具有易于可查询和 graphable 格式将大大简化重复数据。
压缩
nginx 的压缩开始于 mime.types 文件,它定义文件扩展名和 MIME 类型之间默认的对应关系。然后,你需要定义什么类型使用 gzip_types。如果你想完整的列表,你可以使用 MIME-DB 到自动生成的 mime.types,并与添加这些 .compressible == true 到 gzip_types。
当启用 gzip,必须注意的是两个方面:
- 增加内存使用情况。这可以通过限制来解决 gzip_buffers。
- 增加 TTFB 缓冲。这可以通过 gzip_no_buffer 来解决。
HTTP 压缩不限于只 gzip 压缩:nginx 具有第三方 ngx_brotli 模块,较 gzip 的压缩比可以提高 30%。
至于压缩设置本身,让我们讨论两个独立的用例:静态和动态数据。
- 对于静态数据,可以通过预压缩静态资产作为构建过程的一部分来归档最大压缩比。
- 对于动态数据,你需要仔细权衡一个完整的往返:时间压缩数据+时间以进行传输+时间在客户端上解压缩。因此,在设置尽可能高的压缩级别可能是不明智的,不仅是从CPU使用率的角度来看,而且要从TTFB一起看。
代理中的缓冲区可以极大地影响 Web 服务器的性能,特别是相对于延迟。nginx 的代理模块具有多种缓冲开关。您可以分别控制缓冲 proxy_request_buffering 和 proxy_buffering。如果想启用缓冲存储器上消耗上限是设置 client_body_buffer_size 和proxy_buffers 这两个选项。为了响应这可以通过设置被禁用 proxy_max_temp_file_size 为 0。
缓冲最常用的方法有:
- 缓冲器请求/响应达到内存中的某个阈值之后,溢出到磁盘。如果请求启用了请求缓冲,您只在它完全接收后向后端发送一个请求,并且通过响应缓冲,一旦响应准备就绪,就可以立即释放后端线程。这种方法可以提高吞吐量但是会增加响应时间。
- 无缓冲。缓冲可能不是对延迟敏感路由的一个好选择,尤其是使用流媒体的情况。对于他们,你可能想禁用它,但现在你的后端需要处理慢客户机(包括恶意慢/慢读的***)。
- 应用通过控制响应缓冲X-Accel-Buffering报头。
无论您选择何种方式,不要忘记测试其在TTFB和TTLB效果。此外,如前面提到的,缓冲会影响IO使用情况,甚至后端的利用率,所以要留意这一点。
TLS
现在我们要谈论TLS和改善延迟,高层次的方面,可以通过正确配置nginx的完成。大部分优化都在nginx conf 2014的 High Performance Browser Networking’s “Optimizing for TLS” 中谈到了,如果不确定,请咨询Mozilla的服务器端TLS指南和/或您的安全团队。
为了验证你可以使用优化的结果:
- WebpageTest 对性能的影响。
- SSL 服务器测试从 Qualys 公司,或 Mozilla TLS 对安全的影响。
会话恢复
作为数据库管理员爱说“最快的查询是你什么也不查”,同样,TLS 可以缓存的握手结果从而减少一个 RTT。有这样做的方法有两种:
- 你可以要求客户端存储所有会话参数(签名和加密方式),在下一次握手(类似于一个cookie)时将其发送给您。在nginx这边,通过配置ssl_session_tickets指令。这不不会消耗在服务器端的任何内存,但是有一些缺点的:
- 你需要的基础设施来创建,旋转,并为您的TLS会话分配随机加密/签名密钥。只要记住,你真的不应该1)使用源代码控制存储票键2)生成其它非短暂的物质,如日期或证书这些密钥。
- PFS不会在每个会话的基础,但每个TLS票键的基础上,因此,如果***者获取票据密钥的时候,就可以潜在地解密任何捕获流量票的时间。
- 你的密码将被限制在您的标签密钥的大小。如果您正在使用128位的标签密钥则没有多大意义,推荐使用AES256。Nginx的同时支持128位和256位的TLS票键。
- 并非所有的客户端都支持。
- 或者你也可以存储服务器上的TLS会话参数,只给出一个引用(一个ID)给客户端。这是通过完成ssl_session_cache指令。它有助于在会话之间保持PFS和大大限制***面。虽然门票键有缺点:
- 在服务器上,每个会话消耗256字节的内存,这意味着您不能存储过多的数据。
- 他们不能在服务器之间轻松共享。因此您可能需要负载均衡器,这需要在同一客户端发送到同一台服务器保存缓存位置,或者使用ngx_http_lua_module写一个分布式TLS会话存储。
作为一个侧面说明,如果你用会话票据的办法,使用 3 个选项:
你将永远与当前的密钥加密,但接受与未来都和以前的密钥加密的会话。
OCSP Stapling
你应该缩短您 OCSP 响应,否则的话:
- TLS握手可能需要更长的时间,因为客户将需要联系认证机构来获取OCSP状态。
- OCSP的故障可能导致可用性降低。
- 你可能会损害用户的隐私,因为他们的浏览器将与第三方服务联系。
- OCSP 响应您可以定期从你的证书颁发机构获取它,结果分发到您的网络服务器,并与使用它 ssl_stapling_file 的指令:

TLS 记录大小
TLS数据分解成块称为记录,在您完全接收它之前,无法对其进行验证和解密。
默认情况下nginx的使用16K块,甚至不适合IW10拥塞窗口,因此需要额外的往返。nginx提供了一种通过设置记录大小ssl_buffer_size指令:
- 为了优化低延迟,你应该把它设置为小块,比如4K,从CPU使用的角度来看,进异步减少会更昂贵。
- 为了优化高通量应设置在16K。
有两个问题:
- 您需要手动调整它。
- 您只能在每个 nginx 配置或每服务器块基础上设置 ssl_buffer_size, 因此, 如果您有一个具有混合延迟/吞吐量工作负载的服务器就搞不定了。
还有另一种方法:动态记录大小调整。有一个从CloudFlare的Nginx补丁,增加了对动态记录大小的支持。最初的配置比较痛苦,一旦就绪就一劳永逸。
TLS 1.3
TLS 1.3 功能的确听起来很不错,但除非你有资源,否则我建议不启用它,因为:
- 它仍然是一个草案。
- 0-RTT 握手有一定的安全隐患。你的应用程序需要做好准备。
- 还有中间件(防病毒软件,干粉吸入器等),阻止未知 TLS 版本。
Nginx的是基于事件循环的Web服务器,这意味着它在同一时间内只能做一件事情。尽管似乎它所有的这些事情同时,所有nginx的不只是快速的事件之间切换。它所有的工作,因为处理每个事件只需要几微秒。但是如果它开已经占用了太多的时间,延迟可能扶摇直上。
如果你开始注意到你的nginx花费太多的时间内ngx_process_events_and_timers功能,并且分布是双峰的,那么你很可能是由事件循环摊位的影响。
AIO 和线程池
由于事件循环摊位特别是在旋转磁盘的主要来源是 IO,你应该检查这里。通过运行 fileslower 可以测量你多少受到它的影响: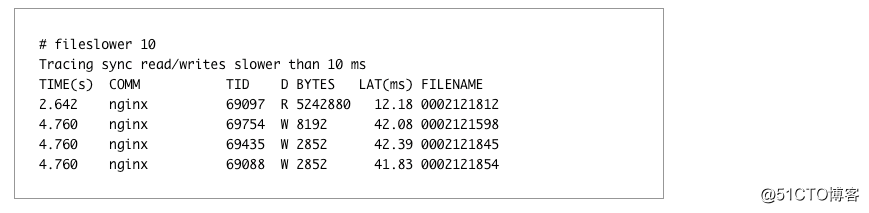
为了解决这个问题,Nginx 已经卸载的 IO 线程池的支持(也有支持 AIO,但 Unix 本地 AIO 有很多怪癖,所以最好避免它,除非你知道你在做什么)。基本的设置包括简单的:
aio threads;
aio_write on;
对于更复杂的情况下,您可以设置自定义thread_pool的,如果一个磁盘出故障不会影响请求的其余部分。线程池可以大大减少nginx进程数困在D状态,改善延迟和吞吐量。但这并不能消除eventloop的问题。
日志写日志也可能会导致长时间卡顿,因为这也是在做磁盘操作。您可以通过运行ext4slower来检查,并寻求获得/错误日志引用: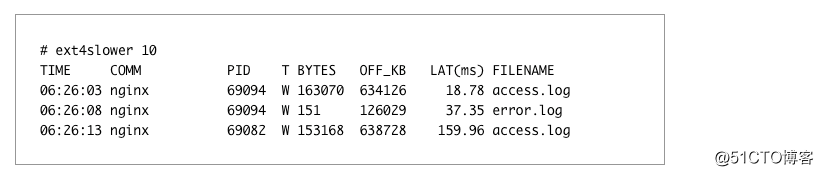
这是可能通过使用写他们之前在内存中后台访问日志来解决此 buffer 参数的 access_log 指令。通过使用 gzip 参数,您也可以将它们写入磁盘,写入磁盘前压缩也可以减少IO压力。
但要完全消除日志 IO 影响,写你应该通过系统日志,这样日志将被完全nginx的事件循环集成。
打开文件缓存
由于 open(2) 调用本质上是阻塞的,Web 服务器通常打开/读取/关闭文件,因此打开文件的缓存可能是有益的。通过 ngx_open_cached_file 可以看到效果:
如果你能看到太多 open 调用或有一些 open 调用花费太多时间,你可以可以考虑打开 open_file_cache:
启用后 open_file_cache,你可以通过观察所有的高速缓存未命中 opensnoop,并决定是否需要调整高速缓存限制: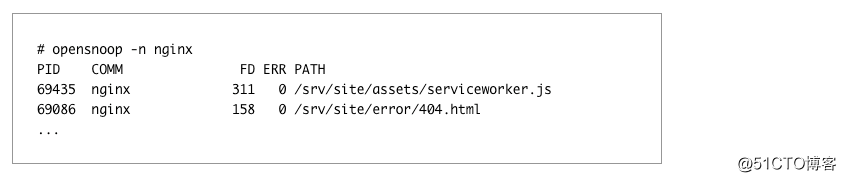
小结
文中所描述的所有优化都是单个 Web 服务器框的优化。他们中的一些可以提高可扩展性和性能。如果您希望以最小的延迟服务请求,或者更快地向客户机发送字节,其他服务也适用。但在我们的经验中,用户可见的大量性能来自于一个更高级别的优化,它影响了整个 Dropbox 边缘网络的行为,如入口/出口流量工程和更聪明的内部负载平衡。这些问题是知识的边缘,而工业才刚刚开始接近它们。
相关链接
[1]https://blogs.dropbox.com/tech/2017/06/evolution-of-dropboxs-edge-network/
[2]https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/
[3]http://www.brendangregg.com/linuxperf.html
[4]https://hpbn.co
[5]https://www.ssllabs.com/ssltest/
[6]https://www.feistyduck.com/bulletproof-tls-newsletter/
[7]https://www.intel.com/content/dam/www/public/us/en/documents/white-papers/large-integer-squaring-ia-paper.pdf
[8]https://software.intel.com/en-us/articles/improving-openssl-performance
[9]https://openconnect.netflix.com/publications/asiabsd_tls_improved.pdf
[10]https://netdevconf.org/1.2/papers/ktls.pdf
[11]https://github.com/yandex/yandex-tank
[12]https://software.intel.com/en-us/articles/power-management-states-p-states-c-states-and-package-c-states
[13]https://access.redhat.com/articles/65410
[14]https://www.netdevconf.org/2.1/papers/BusyPollingNextGen.pdf
[15]http://events.linuxfoundation.org/sites/events/files/slides/LinuxConEurope_2015.pdf
英文原文:https://blogs.dropbox.com/tech/2017/09/optimizing-web-servers-for-high-throughput-and-low-latency/
本文作者 Alexey Ivanov,由 Jesse 翻译,转载译文请注明出处,技术原创及架构实践文章,欢迎通过公众号菜单「联系我们」进行投稿。
推荐阅读
- 美图 HTTPS 优化探索与实践
- 腾讯 TMQ 团队移动 App 的网络优化:24 小时流量优化到原来 15% 历程
- HTTPS 环境使用第三方 CDN 的证书难题与最佳实践 CDN 架构详解
- 如何使用 HTTPS 防止流量劫持
高可用架构
改变互联网的构建方式

以上是关于Web服务器如何实现高吞吐低延迟?Dropbox从操作系统到应用层优化指南的主要内容,如果未能解决你的问题,请参考以下文章