Coredns+Nodelocaldns cache解决Coredns域名解析延迟
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Coredns+Nodelocaldns cache解决Coredns域名解析延迟相关的知识,希望对你有一定的参考价值。
目前18.6版本和之前的coredns都会出现超时5s的情况,那么为什么会出现coredns超时的情况发生?
背景
在Kubernetes中,Pod访问DNS服务器(kube-dns)的最常见方法是通过服务抽象。 因此,在尝试解释问题之前,了解服务的工作原理以及因此在Linux内核中如何实现目标网络地址转换(DNAT)至关重要。
服务是如何工作的?
在iptables模式下(默认情况下),每个服务的kube-proxy在主机网络名称空间的nat表中创建一些iptables规则。
让我们考虑在集群中具有两个DNS服务器实例的kube-dns服务。 相关规则如下:
(1) -A PREROUTING -m comment --comment "kubernetes service portals" -j KUBE-SERVICES
<...>
(2) -A KUBE-SERVICES -d 10.96.0.10/32 -p udp -m comment --comment "kube-system/kube-dns:dns cluster IP" -m udp --dport 53 -j KUBE-SVC-TCOU7JCQXEZGVUNU
<...>
(3) -A KUBE-SVC-TCOU7JCQXEZGVUNU -m comment --comment "kube-system/kube-dns:dns" -m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-LLLB6FGXBLX6PZF7
(4) -A KUBE-SVC-TCOU7JCQXEZGVUNU -m comment --comment "kube-system/kube-dns:dns" -j KUBE-SEP-LRVEW52VMYCOUSMZ
<...>
(5) -A KUBE-SEP-LLLB6FGXBLX6PZF7 -p udp -m comment --comment "kube-system/kube-dns:dns" -m udp -j DNAT --to-destination 10.32.0.6:53
<...>
(6) -A KUBE-SEP-LRVEW52VMYCOUSMZ -p udp -m comment --comment "kube-system/kube-dns:dns" -m udp -j DNAT --to-destination 10.32.0.7:53在我们的示例中,每个Pod的/etc/resolv.conf中都有填充的名称服务器10.96.0.10条目。 因此,来自Pod的DNS查找请求将发送到10.96.0.10,它是kube-dns服务的ClusterIP(虚拟IP)。
由于(1),请求进入KUBE-SERVICE链,然后匹配规则(2)最后根据(3)随机值,跳转到(5)或(6)根据规则( 负载平衡),将请求UDP数据包的目标IPv4地址修改为DNS服务器的“实际” IPv4地址。 这种修饰是由DNAT完成的。
10.32.0.6和10.32.0.7是Weave Net网络中Kubernetes DNS服务器容器的IPv4地址。
Linux内核中的DNAT
如上所示,服务(在iptables模式下)的基础是DNAT,它由内核执行。
DNAT的主要职责是同时更改传出数据包的目的地,答复数据包的源,并确保对所有后续数据包进行相同的修改。
后者严重依赖于连接跟踪机制,也称为conntrack,它被实现为内核模块。顾名思义,conntrack会跟踪系统中正在进行的网络连接。
以一种简化的方式,conntrack中的每个连接都由两个元组表示-一个元组用于原始请求(IP_CT_DIR_ORIGINAL),另一个元组用于答复(IP_CT_DIR_REPLY)。对于UDP,每个元组都由源IP地址,源端口以及目标IP地址和目标端口组成。答复元组包含存储在src字段中的目标的真实地址。
例如,如果IP地址为10.40.0.17的Pod向kube-dns的ClusterIP发送一个请求,该请求被转换为10.32.0.6,则将创建以下元组:
原始:src = 10.40.0.17 dst = 10.96.0.10 sport = 53378 dport = 53
回复:src = 10.32.0.6 dst = 10.40.0.17 sport = 53 dport = 53378通过具有这些条目,内核可以相应地修改任何相关数据包的目的地和源地址,而无需再次遍历DNAT规则。此外,它将知道如何修改回复以及应将回复发送给谁。
创建conntrack条目后,将首先对其进行确认。稍后,如果没有已确认的conntrack条目具有相同的原始元组或回复元组,则内核将尝试确认该条目。
conntrack创建和DNAT的简化流程如下所示:
+---------------------------+
| | 为一个给定的包创建一个conntrack,如果
| 1. nf_conntrack_in | 它并不存在;IP_CT_DIR_REPLY是
| | 反向的IP_CT_DIR_ORIGINAL元组,因此
+------------+--------------+ 回复元组的src还没有改变。
|
v
+---------------------------+
| |
| 2. ipt_do_table | 找到一个匹配的DNAT规则。
| |
+------------+--------------+
|
v
+---------------------------+
| | 根据DNAT规则更新回复元组src部分
| 3. get_unique_tuple | 使其不被任何已经确认的连接使用。
| |
+------------+--------------+
|
v
+---------------------------+
| |
| 4. nf_nat_packet | 根据应答元组打乱数据包的目的端口和地址。
| |
+------------+--------------+
|
v
+----------------------------+
| | 如果没有与相同的原始元组或应答元组确认的连
| 5. __nf_conntrack_confirm | 则确认连接道;
| |
+----------------------------+ 递增insert_failed计数器并删除数据包(如果在)。问题
当从不同线程通过同一套接字同时发送两个UDP数据包时,会出现问题。
UDP是无连接协议,因此connect(2)syscall(与TCP相反)不会发送任何数据包,因此,在调用之后没有创建conntrack条目。
该条目仅在发送数据包时创建。这导致以下可能:
1、两个包都没有在1中找到一个确认的conntrack。nf_conntrack_in一步。为两个包创建具有相同元组的两个conntrack条目。
2、与上面的情况相同,但一个包的conntrack条目在另一个包调用3之前被确认。get_unique_tuple。另一个包通常在源端口更改后得到一个不同的应答元组。
3、与第一种情况相同,但是在步骤2中选择了具有不同端点的两个不同规则。ipt_do_table。
竞争的结果是相同的—其中一个包在步骤5中被丢弃。__nf_conntrack_confirm。
这正是在DNS情况下发生的情况。 GNU C库和musl libc都并行执行A和AAAA DNS查找。由于竞争,内核可能会丢弃其中一个UDP数据包,因此客户端通常会在5秒的超时后尝试重新发送它。
值得一提的是,这个问题不仅是针对Kubernetes的-任何并行发送UDP数据包的Linux多线程进程都容易出现这种竞争情况。
另外,即使您没有任何DNAT规则,第二场竞争也可能发生-加载nf_nat内核模块足以启用对get_unique_tuple的调用就足够了。
可以使用conntrack -S获得的insert_failed计数器可以很好地指示您是否遇到此问题。
缓解措施
意见建议
建议采取多种解决方法:禁用并行查找,禁用IPv6以避免AAAA查找,使用TCP进行查找,改为在Pod的解析器配置文件中设置DNS服务器的真实IP地址,等等。不幸的是,由于常用的容器基础映像Alpine Linux使用musl libc的限制,它们中的许多不起作用。
对于Weave Net用户来说似乎可靠的方法是使用tc延迟DNS数据包。
另外,您可能想知道在ipvs模式下的kube-proxy是否可以绕过这个问题。答案是否定的,因为conntrack也是在这种模式下启用的。此外,在使用rr调度程序时,可以在DNS流量较高的集群中轻松重现第3次竞争。
内核修复
无论采用哪种解决方法,都决定在内核中修复根本原因。
结果是以下内核补丁:
1、 “ netfilter:nf_conntrack:解决冲突以匹配conntracks”修复了第一场比赛(被接受)。
2、 “ netfilter:nf_nat:返回相同的答复元组以匹配CT”修复了第二场比赛(等待复审)。
这两个补丁解决了仅运行一个DNS服务器实例的群集的问题,同时降低了其他实例的超时命中率。
为了在所有情况下完全消除问题,需要解决第三场竞争。一种可能的解决方法是在步骤5中将冲突的conntrack条目与来自同一套接字的不同目的地合并。__nf_conntrack_confirm。但是,这会使在该步骤中更改了目的地的数据包的先前iptables规则遍历的结果无效。
另一种可能的解决方案是在每个节点上运行DNS服务器实例,并按照我的同事的建议,通过Pod查询运行在本地节点上的DNS服务器。
结论
首先,我展示了“ DNS查找需要5秒”问题的基本细节,并揭示了罪魁祸首-Linux conntrack内核模块,它本质上是不受欢迎的。有关模块中也存在其他可能的问题
解决方案如下:
方案(一):使用 TCP 协议发送 DNS 请求
通过resolv.conf的use-vc选项来开启 TCP 协议
测试
1、修改/etc/resolv.conf文件,在最后加入一行文本:
options use-vc
2、此压测可根据下面测试的go文件进行测试,编译好后放进一个pod中,进行压测:
#200个并发,持续30秒,记录超过5s的请求个数 ./dns -host {service}.{namespace} -c 200 -d 30 -l 5000
方案(二):避免相同五元组 DNS 请求的并发
通过resolv.conf的single-request-reopen和single-request选项来避免:
single-request-reopen (glibc>=2.9) 发送 A 类型请求和 AAAA 类型请求使用不同的源端口。这样两个请求在 conntrack 表中不占用同一个表项,从而避免冲突。
single-request (glibc>=2.10) 避免并发,改为串行发送 A 类型和 AAAA 类型请求,没有了并发,从而也避免了冲突。
测试 single-request-reopen
修改/etc/resolv.conf文件,在最后加入一行文本:
options single-request-reopen
此压测可根据下面测试的go文件进行测试,编译好后放进一个pod中,进行压测:
#200个并发,持续30秒,记录超过5s的请求个数 ./dns -host {service}.{namespace} -c 200 -d 30 -l 5000
测试 single-request
修改/etc/resolv.conf文件,在最后加入一行文本:
options single-request
此压测可根据下面测试的go文件进行测试,编译好后放进一个pod中,进行压测:
#200个并发,持续30秒,记录超过5s的请求个数 ./dns -host {service}.{namespace} -c 200 -d 30 -l 5000
最后结果,如果你测试过,相信coredns的测试如果还是增加使用 TCP 协议发送 DNS 请求,还是避免相同五元组 DNS 请求的并发,都没有显著的解决coredns延迟的结果
那么其实 k8s 官方也意识到了这个问题比较常见,所以也给出了 coredns 以 cache 模式作为 daemonset 部署的解决方案
在 Kubernetes 集群中使用 NodeLocal DNSCache
https://github.com/kubernetes/kubernetes/tree/master/cluster/addons/dns/nodelocaldns
NodeLocal DNSCache 通过在集群节点上作为 DaemonSet 运行 dns 缓存代理来提高集群 DNS 性能。 在当今的体系结构中,处于 ClusterFirst DNS 模式的 Pod 可以连接到 kube-dns serviceIP 进行 DNS 查询。 通过 kube-proxy 添加的 iptables 规则将其转换为 kube-dns/CoreDNS 端点。 借助这种新架构,Pods 将可以访问在同一节点上运行的 dns 缓存代理,从而避免了 iptables DNAT 规则和连接跟踪。 本地缓存代理将查询 kube-dns 服务以获取集群主机名的缓存缺失(默认为 cluster.local 后缀),并有效解决5秒延迟问题
在集群中运行 NodeLocal DNSCache 有如下几个好处:
如果本地没有 CoreDNS 实例,则具有最高 DNS QPS 的 Pod 可能必须到另一个节点进行解析,使用 NodeLocal DNSCache 后,拥有本地缓存将有助于改善延迟
跳过 iptables DNAT 和连接跟踪将有助于减少 conntrack 竞争并避免 UDP DNS 条目填满 conntrack 表。(常见的5s超时问题就是这个原因造成的)
从本地缓存代理到 kube-dns 服务的连接可以升级到 TCP,TCP conntrack 条目将在连接关闭时被删除,而 UDP 条目必须超时(默认 nf_conntrack_udp_timeout 是 30 秒)
将 DNS 查询从 UDP 升级到 TCP 将减少归因于丢弃的 UDP 数据包和 DNS 超时的尾部等待时间,通常长达 30 秒(3 次重试+ 10 秒超时)。
可以重新启用负缓存,从而减少对 kube-dns 服务的查询数量。
架构图
启用 NodeLocal DNSCache 之后,这是 DNS 查询所遵循的路径: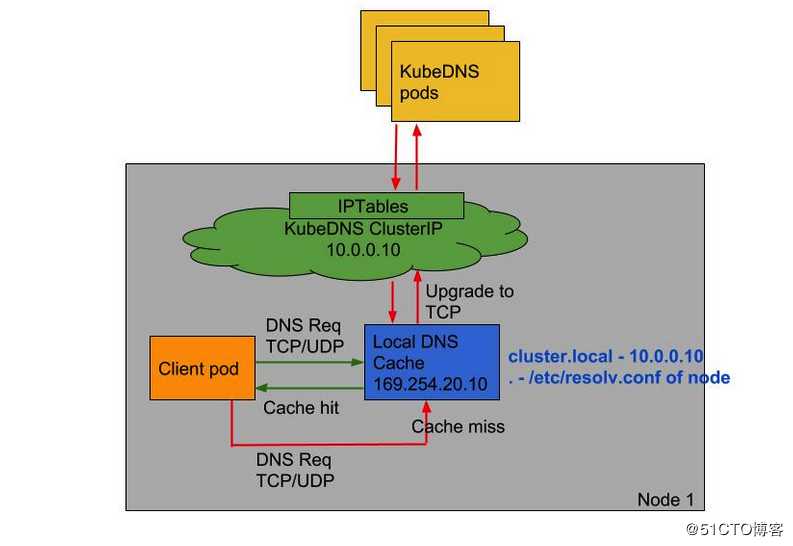
环境检查
该资源清单文件中包含几个变量,其中:
PILLARDNSSERVER :表示 kube-dns 这个 Service 的 ClusterIP,可以通过命令 kubectl get svc -n A | grep kube-dns | awk ‘{ print $4 }‘ 获取
PILLARLOCALDNS:表示 DNSCache 本地的 IP,默认为 169.254.20.10
PILLARDNSDOMAIN:表示集群域,默认就是 cluster.local
另外还有两个参数 PILLARCLUSTERDNS 和 PILLARUPSTREAMSERVERS,这两个参数会通过镜像 1.15.6 版本以上的去进行配置,对应的值来源于 kube-dns 的 ConfigMap 和定制的 Upstream Server 配置。直接执行如下所示的命令即可安装:
运行nodelocaldns需要进行替换以下操作,如果下载过慢,可以直接使用下面的yaml来使用,需要替换的话,只有10.96.0.10,这个是kube-dns service的clusterIP
开始部署
wget -O nodelocaldns.yaml "https://github.com/kubernetes/kubernetes/raw/master/cluster/addons/dns/nodelocaldns/nodelocaldns.yaml" && sed -i ‘s/k8s.gcr.io/zhaocheng172/g‘ nodelocaldns.yaml && sed -i ‘s/__PILLAR__DNS__SERVER__/10.96.0.10/g‘ nodelocaldns.yaml && sed -i ‘s/__PILLAR__LOCAL__DNS__/169.254.20.10/g‘ nodelocaldns.yaml && sed -i ‘s/__PILLAR__DNS__DOMAIN__/cluster.local/g‘ nodelocaldns.yaml 最终替换结果
#Copyright 2018 The Kubernetes Authors.
#Licensed under the Apache License, Version 2.0 (the "License");
#you may not use this file except in compliance with the License.
#You may obtain a copy of the License at
#http://www.apache.org/licenses/LICENSE-2.0
#Unless required by applicable law or agreed to in writing, software
#distributed under the License is distributed on an "AS IS" BASIS,
#WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
#See the License for the specific language governing permissions and
#limitations under the License.
apiVersion: v1
kind: ServiceAccount
metadata:
name: node-local-dns
namespace: kube-system
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
---
apiVersion: v1
kind: Service
metadata:
name: kube-dns-upstream
namespace: kube-system
labels:
k8s-app: kube-dns
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
kubernetes.io/name: "KubeDNSUpstream"
spec:
ports:
- name: dns
port: 53
protocol: UDP
targetPort: 53
- name: dns-tcp
port: 53
protocol: TCP
targetPort: 53
selector:
k8s-app: kube-dns
---
apiVersion: v1
kind: ConfigMap
metadata:
name: node-local-dns
namespace: kube-system
labels:
addonmanager.kubernetes.io/mode: Reconcile
data:
Corefile: |
cluster.local:53 {
errors
cache {
success 9984 30
denial 9984 5
}
reload
loop
bind 169.254.20.10 10.96.0.10
forward . __PILLAR__CLUSTER__DNS__ {
force_tcp
}
prometheus :9253
health 169.254.20.10:8080
}
in-addr.arpa:53 {
errors
cache 30
reload
loop
bind 169.254.20.10 10.96.0.10
forward . __PILLAR__CLUSTER__DNS__ {
force_tcp
}
prometheus :9253
}
ip6.arpa:53 {
errors
cache 30
reload
loop
bind 169.254.20.10 10.96.0.10
forward . __PILLAR__CLUSTER__DNS__ {
force_tcp
}
prometheus :9253
}
.:53 {
errors
cache 30
reload
loop
bind 169.254.20.10 10.96.0.10
forward . __PILLAR__UPSTREAM__SERVERS__ {
force_tcp
}
prometheus :9253
}
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: node-local-dns
namespace: kube-system
labels:
k8s-app: node-local-dns
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
spec:
updateStrategy:
rollingUpdate:
maxUnavailable: 10%
selector:
matchLabels:
k8s-app: node-local-dns
template:
metadata:
labels:
k8s-app: node-local-dns
annotations:
prometheus.io/port: "9253"
prometheus.io/scrape: "true"
spec:
priorityClassName: system-node-critical
serviceAccountName: node-local-dns
hostNetwork: true
dnsPolicy: Default # Don‘t use cluster DNS.
tolerations:
- key: "CriticalAddonsOnly"
operator: "Exists"
- effect: "NoExecute"
operator: "Exists"
- effect: "NoSchedule"
operator: "Exists"
containers:
- name: node-cache
image: zhaocheng172/k8s-dns-node-cache:1.15.13
resources:
requests:
cpu: 25m
memory: 5Mi
args: [ "-localip", "169.254.20.10,10.96.0.10", "-conf", "/etc/Corefile", "-upstreamsvc", "kube-dns-upstream" ]
securityContext:
privileged: true
ports:
- containerPort: 53
name: dns
protocol: UDP
- containerPort: 53
name: dns-tcp
protocol: TCP
- containerPort: 9253
name: metrics
protocol: TCP
livenessProbe:
httpGet:
host: 169.254.20.10
path: /health
port: 8080
initialDelaySeconds: 60
timeoutSeconds: 5
volumeMounts:
- mountPath: /run/xtables.lock
name: xtables-lock
readOnly: false
- name: config-volume
mountPath: /etc/coredns
- name: kube-dns-config
mountPath: /etc/kube-dns
volumes:
- name: xtables-lock
hostPath:
path: /run/xtables.lock
type: FileOrCreate
- name: kube-dns-config
configMap:
name: kube-dns
optional: true
- name: config-volume
configMap:
name: node-local-dns
items:
- key: Corefile
path: Corefile.base可以通过如下命令来查看对应的 Pod 是否已经启动成功:

需要注意的是这里使用 DaemonSet 部署 node-local-dns 使用了 hostNetwork=true,会占用宿主机的 8080 端口,所以需要保证该端口未被占用。
另外我们还需要修改 kubelet 的 --cluster-dns 参数,将其指向 169.254.20.10,Daemonset 会在每个节点创建一个网卡来绑这个 IP,Pod 向本节点这个 IP 发 DNS 请求,缓存没有命中的时候才会再代理到上游集群 DNS 进行查询。
两种方案测试nodelocaldns实效性
第一种就是定制一个pod,Kubernetes Pod dnsPolicy 可以针对每个Pod设置DNS的策略,通过PodSpec下的dnsPolicy字段可以指定相应的策略
这种方式可以直接启动一个pod,Pods将直接可以访问在同一节点上运行的 dns 缓存代理,从而避免了 iptables DNAT 规则和连接跟踪,但是这种对于整体集群来讲并不适合,只提高了当前pod的DNScache的命中率,这种适合定制一些dns策略
apiVersion: apps/v1
kind: Deployment
metadata:
creationTimestamp: null
labels:
app: web
name: web
namespace: kube-system
spec:
replicas: 1
selector:
matchLabels:
app: web
strategy: {}
template:
metadata:
creationTimestamp: null
labels:
app: web
spec:
containers:
- image: nginx
name: nginx
dnsConfig:
nameservers:
- 169.254.20.10
searches:
- public.svc.cluster.local
- svc.cluster.local
- cluster.local
options:
- name: ndots
value: "5"
dnsPolicy: None第二种如果对于集群来讲,需要全部生效
需要替换每个节点的clusterDNS的地址
clusterDNS:
- 10.96.0.10替换的话可以直接使用sed直接替换,另外需要所有节点替换并重启kubelet
sed -i ‘s/10.96.0.10/169.254.20.10/g‘ /var/lib/kubelet/config.yaml
systemctl daemon-reload
systemctl restart kubelet待 node-local-dns 安装配置完成后,我们可以部署一个新的 Pod 来验证下:(test-node-local-dns.yaml)
apiVersion: v1
kind: Pod
metadata:
name: test-node-local-dns
spec:
containers:
- name: local-dns
image: busybox
command: ["/bin/sh", "-c", "sleep 60m"]直接部署:
$ kubectl apply -f test-node-local-dns.yaml
$ kubectl exec -it test-node-local-dns /bin/sh
/ # cat /etc/resolv.conf
nameserver 169.254.20.10
search default.svc.cluster.local svc.cluster.local cluster.local
options ndots:5需要注意
我们现在已经可以看到 nameserver 已经变成 169.254.20.10 了,当然对于之前的历史 Pod 要想使用 node-local-dns 则需要重建所有的pod
1、linux 中glibc的 resolver 的缺省超时时间是 5s,而导致超时的原因是内核conntrack模块的 bug。
2、DNS client (glibc 或 musl libc) 会并发请求 A 和 AAAA 记录,跟 DNS Server 通信自然会先 connect (建立 fd),后面请求报文使用这个 fd 来发送,由于 UDP 是无状态协议, connect 时并不会发包,也就不会创建 conntrack 表项, 而并发请求的 A 和 AAAA 记录默认使用同一个 fd 发包,send 时各自发的包它们源 Port 相同(因为用的同一个 socket 发送),当并发发包时,两个包都还没有被插入 conntrack 表项,所以 netfilter 会为它们分别创建 conntrack 表项,而集群内请求 kube-dns 或 coredns 都是访问的 CLUSTER-IP,报文最终会被 DNAT 成一个 endpoint 的 POD IP,当两个包恰好又被 DNAT 成同一个 POD IP 时,它们的五元组就相同了,在最终插入的时候后面那个包就会被丢掉,如果 dns 的 pod 副本只有一个实例的情况就很容易发生(始终被 DNAT 成同一个 POD IP),现象就是 dns 请求超时,client 默认策略是等待 5s 自动重试,如果重试成功,我们看到的现象就是 dns 请求有 5s 的延时。
另外如果要想去跟踪 DNS 的解析过程的话可以去通过抓包来观察具体超时的最大时间。
测试coredns+nodelocaldns的效果
我们可以通过Go的一个测试用例来测试DNS的解析是否得到提升
首先安装一个Go的环境
#wget https://dl.google.com/go/go1.12.5.linux-amd64.tar.gz
#tar -zxf go1.12.5.linux-amd64.tar.gz -C /usr/local
#export PATH=$PATH:/usr/local/go/bin
#go version主要是要测试 dns 服务的性能,相当于压测工具只做域名解析的耗时时间
cat dns-test.go
package main
import (
"context"
"flag"
"fmt"
"net"
"sync/atomic"
"time"
)
var host string
var connections int
var duration int64
var limit int64
var timeoutCount int64
func main() {
// os.Args = append(os.Args, "-host", "www.baidu.com", "-c", "200", "-d", "30", "-l", "5000")
flag.StringVar(&host, "host", "", "Resolve host")
flag.IntVar(&connections, "c", 100, "Connections")
flag.Int64Var(&duration, "d", 0, "Duration(s)")
flag.Int64Var(&limit, "l", 0, "Limit(ms)")
flag.Parse()
var count int64 = 0
var errCount int64 = 0
pool := make(chan interface{}, connections)
exit := make(chan bool)
var (
min int64 = 0
max int64 = 0
sum int64 = 0
)
go func() {
time.Sleep(time.Second * time.Duration(duration))
exit <- true
}()
endD:
for {
select {
case pool <- nil:
go func() {
defer func() {
<-pool
}()
resolver := &net.Resolver{}
now := time.Now()
_, err := resolver.LookupIPAddr(context.Background(), host)
use := time.Since(now).Nanoseconds() / int64(time.Millisecond)
if min == 0 || use < min {
min = use
}
if use > max {
max = use
}
sum += use
if limit > 0 && use >= limit {
timeoutCount++
}
atomic.AddInt64(&count, 1)
if err != nil {
fmt.Println(err.Error())
atomic.AddInt64(&errCount, 1)
}
}()
case <-exit:
break endD
}
}
fmt.Printf("request count:%d
error count:%d
", count, errCount)
fmt.Printf("request time:min(%dms) max(%dms) avg(%dms) timeout(%dn)
", min, max, sum/count, timeoutCount)
}直接go build,会有一个dns-test的二进制文件
将此文件放到pod里面#kubectl cp /root/dns-test web-7f5df76d5f-r76xx:/root -n kube-system
下面来进行测试
进行压测
200个并发,持续30秒,记录超过5s的请求个数
/dns -host {service}.{namespace} -c 200 -d 30 -l 5000
结果如下:
1.14.3版本原生集群不加参数测试默认使用iptables性能方面可能不是那么好,不过已经没有5s延迟情况发生,最高耗时2.9s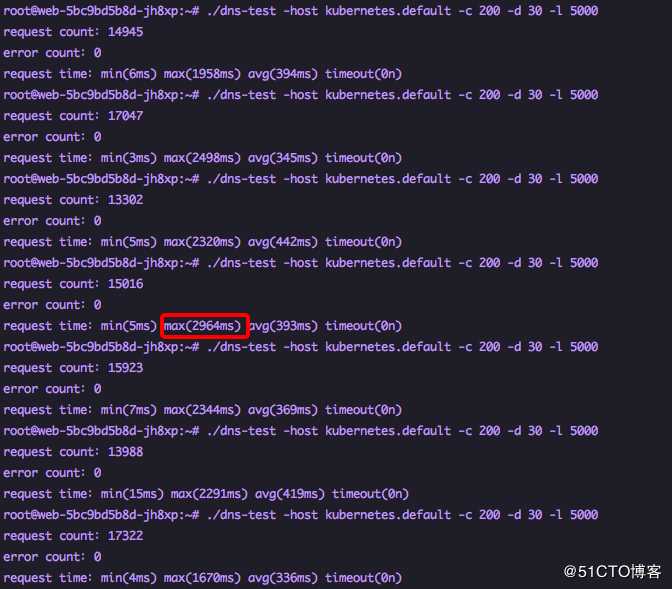
1.18.6原生集群不加参数测试
结论没有延迟操作最大耗时为0.5s,默认采用ipvs,效率非常高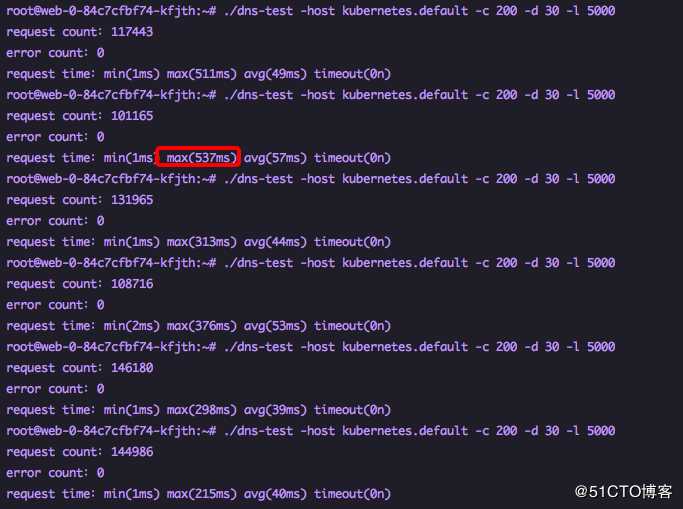
最后总结:
通过测试结果得到以下结论
1.14.3集群使用coredns+nodelocaldns配合使用避免相同五元组 DNS 请求的并发,增加options single-request-reopen,最大耗时降低到2.25s左右,不会出现5s超时情况,效果最好
1.18.6集群使用coredns+nodelocaldns不加参数测试最大耗时降低到0.53s左右,效率明显提升,效果最好
以上是关于Coredns+Nodelocaldns cache解决Coredns域名解析延迟的主要内容,如果未能解决你的问题,请参考以下文章