k8setcd集群took too long to execute慢日志告警问题分析
Posted 1994jinnan
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了k8setcd集群took too long to execute慢日志告警问题分析相关的知识,希望对你有一定的参考价值。
背景
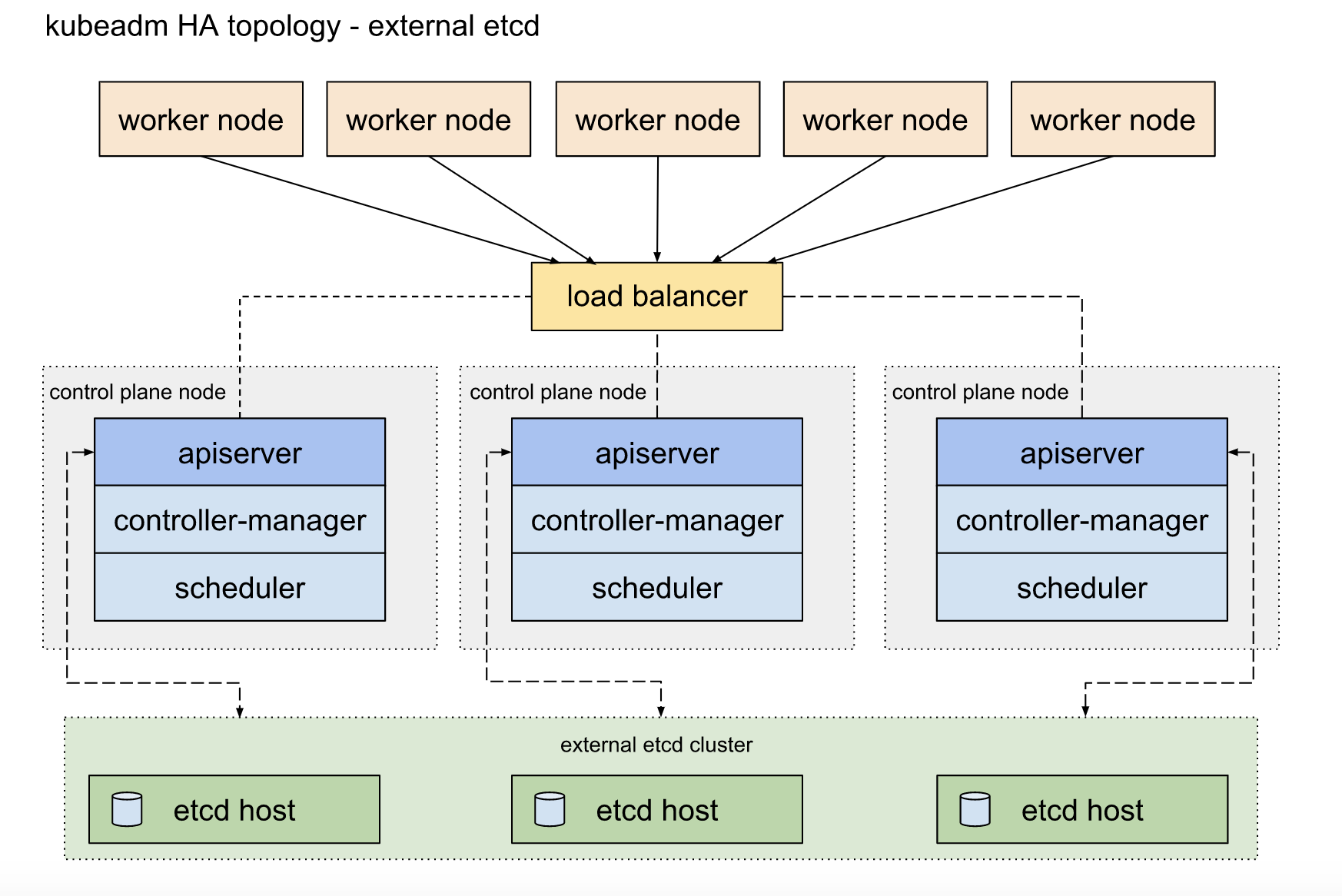
- 目前 机器学习平台 后端采用k8s架构进行GPU和CPU资源的调度和容器编排。总所周知,k8s的后端核心存储使用etcd进行metadata持久化存储。机器学习平台采取[External etcd topology](http://way.xiaojukeji.com/article/External etcd topology)结构进行etcd的HA部署。
- etcd集群的稳定性直接关系到k8s集群和机器学习平台的稳定性。odin平台直接接入etcd集群的慢日志(etcd请求操作>100ms)告警,实时监控etcd的稳定性。
问题记录
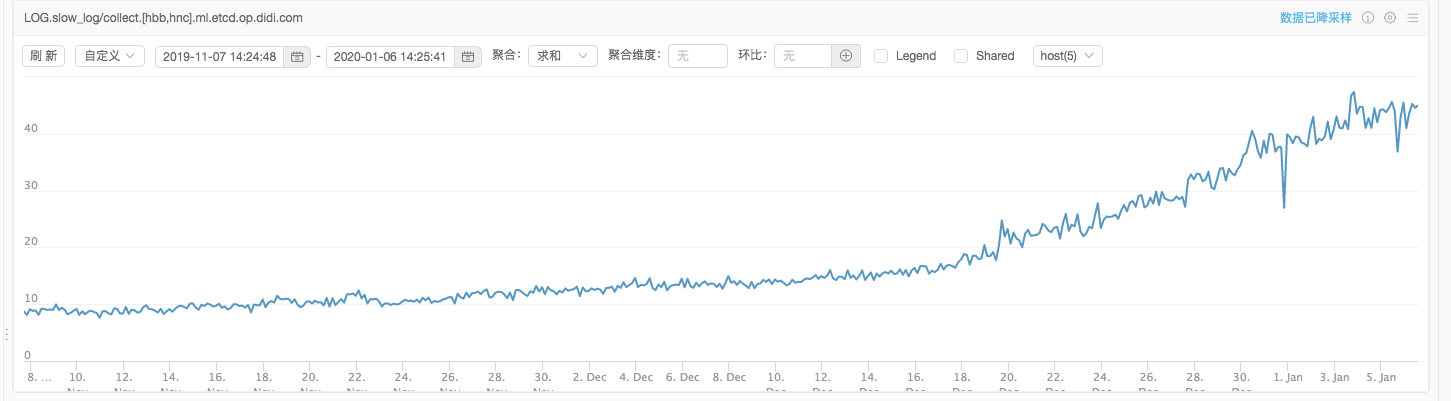
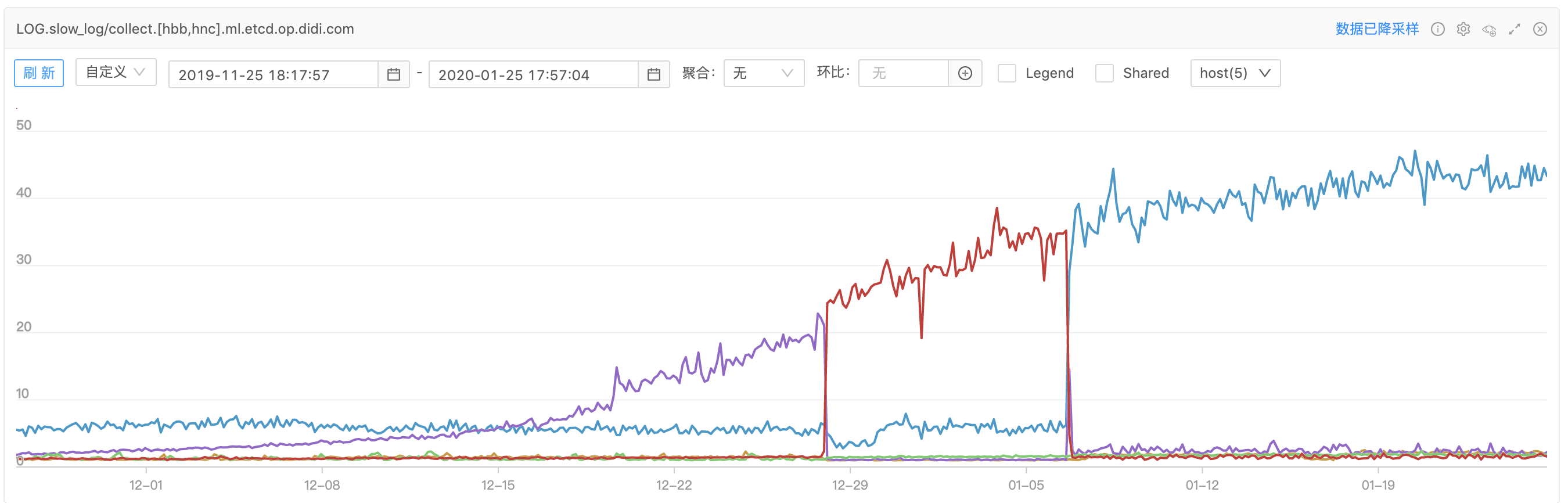
- 2020-01-06 运维同学反馈2019年12月中旬etcd慢日志监控出现大量的告警记录,而且告警呈上升趋势。
- 2020-01-20 运维同学继续反馈etcd慢日志告警数量继续上涨,未呈现稳态趋势。
问题分析
-
2020-01-06 运维同学反馈告警问题时,当时怀疑etcd 集群磁盘latency性能问题,通过etcd metrics接口dump backend_commit_duration_seconds 和 wal_fsync_duration_seconds,latency区间在128ms。etcd官方文档
what-does-the-etcd-warning-apply-entries-took-too-long-mean
建议排查磁盘性能问题,保证 "p99 duration should be less than 25ms"。和运维同学讨论,先将etcd设置的慢日志阈值调整到100,继续跟踪告警问题。
root@xxx-ser00:~$ curl -L -s http://localhost:2379/metrics | grep backend_commit_duration_seconds # HELP etcd_disk_backend_commit_duration_seconds The latency distributions of commit called by backend. # TYPE etcd_disk_backend_commit_duration_seconds histogram etcd_disk_backend_commit_duration_seconds_bucket{le="0.001"} 28164 etcd_disk_backend_commit_duration_seconds_bucket{le="0.002"} 357239 etcd_disk_backend_commit_duration_seconds_bucket{le="0.004"} 1.9119004e+07 etcd_disk_backend_commit_duration_seconds_bucket{le="0.008"} 2.07783083e+08 etcd_disk_backend_commit_duration_seconds_bucket{le="0.016"} 3.02929134e+08 etcd_disk_backend_commit_duration_seconds_bucket{le="0.032"} 3.0395167e+08 etcd_disk_backend_commit_duration_seconds_bucket{le="0.064"} 3.04047027e+08 etcd_disk_backend_commit_duration_seconds_bucket{le="0.128"} 3.04051485e+08 # 大部分disk_backend_commit_duration <= 128ms etcd_disk_backend_commit_duration_seconds_bucket{le="0.256"} 3.04051486e+08 etcd_disk_backend_commit_duration_seconds_bucket{le="0.512"} 3.04051486e+08 etcd_disk_backend_commit_duration_seconds_bucket{le="1.024"} 3.04051486e+08 etcd_disk_backend_commit_duration_seconds_bucket{le="2.048"} 3.04051486e+08 etcd_disk_backend_commit_duration_seconds_bucket{le="4.096"} 3.04051486e+08 etcd_disk_backend_commit_duration_seconds_bucket{le="8.192"} 3.04051486e+08 etcd_disk_backend_commit_duration_seconds_bucket{le="+Inf"} 3.04051486e+08 etcd_disk_backend_commit_duration_seconds_sum 2.193424564702583e+06 etcd_disk_backend_commit_duration_seconds_count 3.04051486e+08 root@xxx-ser00:~$ curl -L -s http://localhost:2379/metrics | grep wal_fsync_duration_seconds # HELP etcd_disk_wal_fsync_duration_seconds The latency distributions of fsync called by wal. # TYPE etcd_disk_wal_fsync_duration_seconds histogram etcd_disk_wal_fsync_duration_seconds_bucket{le="0.001"} 9.661794e+06 etcd_disk_wal_fsync_duration_seconds_bucket{le="0.002"} 1.134905564e+09 etcd_disk_wal_fsync_duration_seconds_bucket{le="0.004"} 1.638654117e+09 etcd_disk_wal_fsync_duration_seconds_bucket{le="0.008"} 1.64588859e+09 etcd_disk_wal_fsync_duration_seconds_bucket{le="0.016"} 1.646517588e+09 etcd_disk_wal_fsync_duration_seconds_bucket{le="0.032"} 1.646521494e+09 etcd_disk_wal_fsync_duration_seconds_bucket{le="0.064"} 1.646521531e+09 etcd_disk_wal_fsync_duration_seconds_bucket{le="0.128"} 1.646521634e+09 # 大部分disk_wal_fsync_duration <= 128ms etcd_disk_wal_fsync_duration_seconds_bucket{le="0.256"} 1.646521635e+09 etcd_disk_wal_fsync_duration_seconds_bucket{le="0.512"} 1.646521635e+09 etcd_disk_wal_fsync_duration_seconds_bucket{le="1.024"} 1.646521635e+09 etcd_disk_wal_fsync_duration_seconds_bucket{le="2.048"} 1.646521635e+09 etcd_disk_wal_fsync_duration_seconds_bucket{le="4.096"} 1.646521635e+09 etcd_disk_wal_fsync_duration_seconds_bucket{le="8.192"} 1.646521635e+09 etcd_disk_wal_fsync_duration_seconds_bucket{le="+Inf"} 1.646521635e+09 etcd_disk_wal_fsync_duration_seconds_sum 3.2505764775865404e+06 etcd_disk_wal_fsync_duration_seconds_count 1.646521635e+09 -
2020-01-20 运维同学继续反馈慢日志告警,调整到100个告警阈值,慢日志告警数量还是呈上升趋势。查看每台etcd服务的监控,发现告警集中在某一台etcd服务上,当etcd服务重启时,告警会发生迁移;告警值会继上一个etcd服务重启后的数,继续上涨。
-
登陆其中一台慢日志告警etcd服务器,在/var/log/message 日志中统计etcd ‘took too long‘ 超过100ms的慢日志,68%的range request,其中87%的job查询。
root@xxx-ser00:/var/log$ grep ‘took too long‘ /var/log/messages | grep ‘Jan 19‘ | wc -l 176013 root@xxx-ser00:/var/log$ grep ‘took too long‘ /var/log/messages | grep ‘Jan 19‘ | grep ‘read-only range request‘ | wc -l 120199 root@xxx-ser00:/var/log$ echo ‘ibase=10; obase=10; scale=2; 120199/176013‘ | bc .68 root@xxx-ser00:/var/log$ grep ‘took too long‘ /var/log/messages | grep ‘Jan 19‘ | grep ‘read-only range request‘ | grep ‘/registry/jobs‘ | wc -l 104698 root@xxx-ser00:/var/log$ echo ‘ibase=10; obase=10; scale=2; 104698/120199‘ | bc .87 -
随机抽取一条慢日志,通过日志,直接使用etcdctl 查询,返回500条job数据。怀疑有服务通过kube-apiserver 进行大量的get job lists的请求。
Jan 20 19:40:09 xxx-ser00 etcd: read-only range request "key:"/registry/jobs/65-ns/k8s-job-tdc6eu-1576247407339\000" range_end:"/registry/jobs0" limit:500 revision:1712050719 " took too long (117.960324ms) to execute root@xxx-ser00:/home/xiaoju/etcd/bin$ cd /home/xiaoju/etcd/bin/ root@xxx-ser00:/home/xiaoju/etcd/bin$ export ETCDCTL_API=3 root@xxx-ser00:/home/xiaoju/etcd/bin$ ./etcdctl get /registry/jobs/65-ns/k8s-job-tdc6eu-1576247407339\000 --limit=500 --keys-only /registry/jobs0 | sed ‘/^$/d‘ | wc -l 500 -
在其中一台apiserver和xxx-ser00服务器上进行抓包
root@kube-master-ser01:~$ tcpdump -v -i any -s 0 -w apiserver.pcap port 8080 root@xxx-ser00:~$ tcpdump -v -i eth0 -s 0 -w etcd.pcap port 2379 -
将慢日志中的job name k8s-job-tdc6eu-1576247407339 在etcd.pcap中查询,看到源IP是xx.xx.128.58 kube-master-ser01,端口20994,就是kube-apiserver的发起的请求。
root@kube-master-ser01:~$ netstat -antp | grep 20994 tcp 0 0 xx.xx.128.58:20994 xx.xx.76.33:2379 ESTABLISHED 25969/kube-apiserve -
将慢日志中的job name k8s-job-tdc6eu-1576247407339 在apiserver.pcap中查询,能查询到job相关信息,查看wireshark http stream的上下文,发现kube-controller-manager中cronjob-controller调用了get jobs。解析url中的参数,发现和etcd中慢日志告警类似,将apiserver.pcap中的url 另存为日志。可以查询到url请求,也是cronjob-controller调用了get jobs。
root@kube-master-ser01:~$ echo eyJ2IjoibWV0YS5rOHMuaW8vdjEiLCJydiI6MTcxMjA1MDcxOSwic3RhcnQiOiI2NS1ucy9rOHMtam9iLXN2Z2Q5NC0xNTczNzQyNDAyNDMyXHUwMDAwIn0 | base64 -d {"v":"meta.k8s.io/v1","rv":1712050719,"start":"65-ns/k8s-job-svgd94-1573742402432u0000"}base64: invalid input Jan 20 19:40:09 xxx-ser00 etcd: read-only range request "key:"/registry/jobs/65-ns/k8s-job-tdc6eu-1576247407339\000" range_end:"/registry/jobs0" limit:500 revision:1712050719 " took too long (117.960324ms) to execute root@kube-master-ser01:~$ grep limit=500 apiserver.log | cut -d ‘=‘ -f2 | cut -d ‘&‘ -f1 | while read line; do echo $line | base64 -D | grep k8s-job-tdc6eu-1576247407339 && echo $line; done {"v":"meta.k8s.io/v1","rv":1712050719,"start":"65-ns/k8s-job-tdc6eu-1576247407339u0000 eyJ2IjoibWV0YS5rOHMuaW8vdjEiLCJydiI6MTcxMjA1MDcxOSwic3RhcnQiOiI2NS1ucy9rOHMtam9iLXRkYzZldS0xNTc2MjQ3NDA3MzM5XHUwMDAwIn0 -
查看cronjob_controller的代码,发现不是使用的 JobInformer 而是通过clientset list了所有namespace下的job。当前
机器学习平台
k8s集群,全部namespace下的job,一次list 分页查询会返回慢日志。
root@kube-master-ser01:~$ time kubectl get jobs -A | wc -l xxxx real 2m1.287s user 0m32.263s sys 0m8.845s
解决方案
- 平台job需要配置ttlSecondsAfterFinished,执行完成的job可以自动过期。防止大数据量的任务查询,造成etcd库查询压力。
- 平台未使用cronjob,可以禁止cronjob_controller的功能。
- 之前k8s社区有相关issue跟踪CronJob controller should use shared informers已提交相关信息给Contributor,重新修改问题。
- Cronjob后续GA版本KEP for Graduating CronJob to GA
实施方案
- 生产环境历史job数据通过patch ttlSecondsAfterFinished,更新job过期时间
- 生产环境新建job通过增加ttlSecondsAfterFinished,配置job过期时间
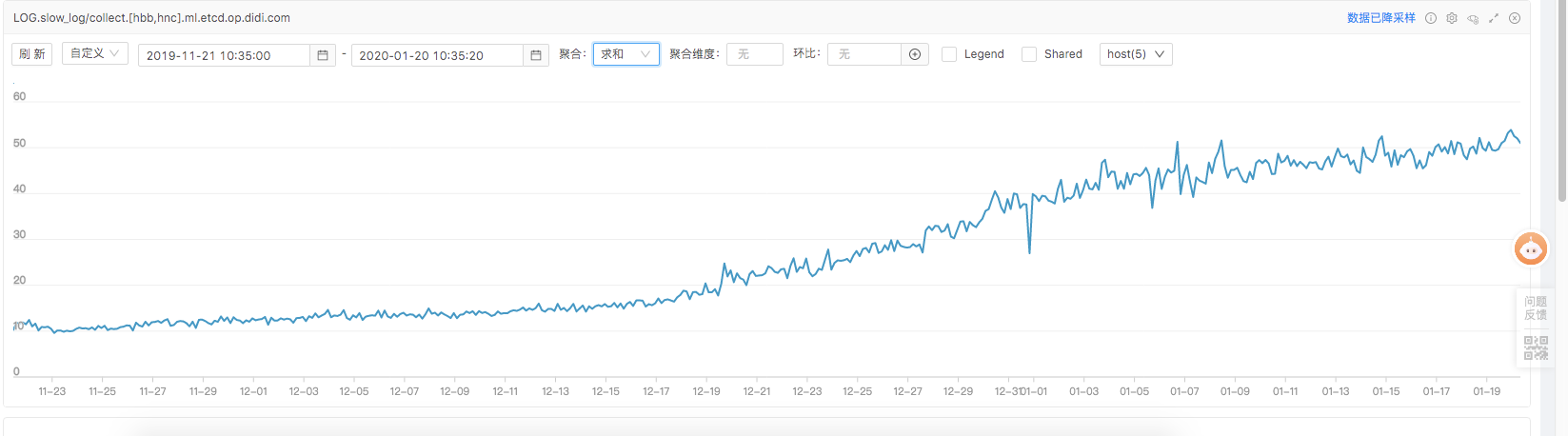
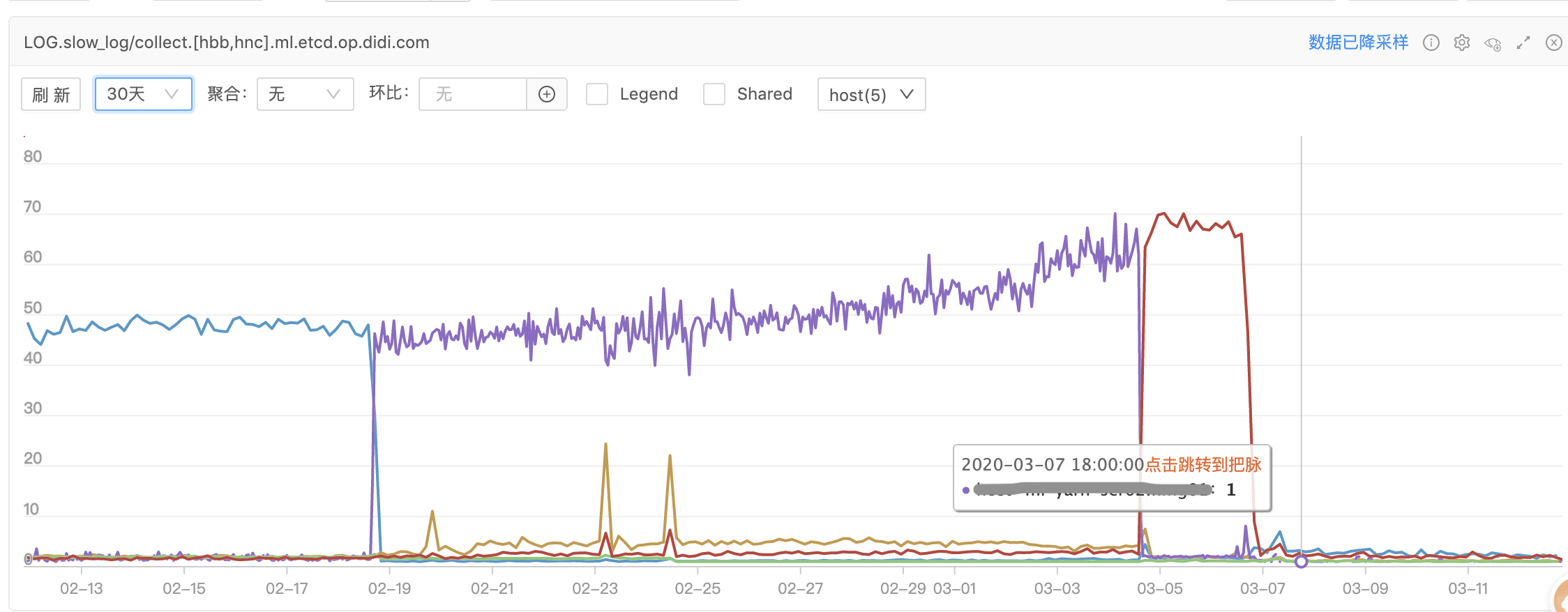
- 变更后的etcd慢查询告警曲线
- 来源:http://www.totozhan.com/sitemap.html
以上是关于k8setcd集群took too long to execute慢日志告警问题分析的主要内容,如果未能解决你的问题,请参考以下文章
Python int too large to convert to C long
python 提示 :OverflowError: Python int too large to convert to C long
Git error: unable to create file xxx: Filename too long
[踩坑] Django "OverflowError: Python int too large to convert to C long" 错误
解决:Command line is too long. In order to reduce its length classpath file can be used.
解决:Command line is too long. In order to reduce its length classpath file can be used.