双向链表
原理
单链表在遍历其每一个元素的过程中,一旦通过某个节点的next进入了下一个节点之后,就没有办法再回到上一个节点了,单链表只能往前走,而不能往后,这样子显然非常的不方便。解决的办法是我们在单链表的基础上给每一个元素附上两个指针域,一个是指向下一个节点的next,另一个是指向下一个节点的prev,如此来实现双向链表。
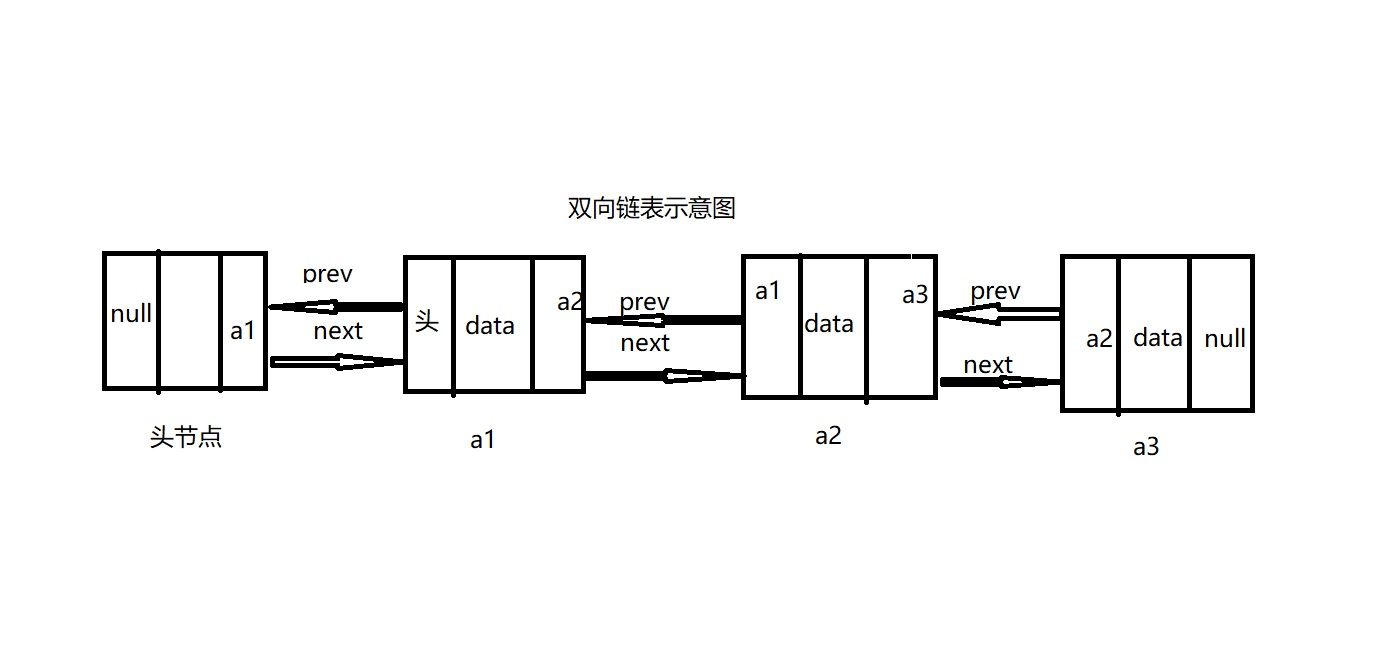
算法实现
算法实现与单链表类似,这里仅仅实现了双向链表节点的插入。
typedef struct Node {
int data;
Node* next;
Node* prev;
}LinkList,LinkNode;
bool initDbList(LinkList*& L) {
if (!L) {
L = new LinkList;
L->data = -1;
L->next = NULL;
L->prev = NULL;
if (!L) return false;
return true;
}
return false;
}
bool addDbListEnd(LinkList*& L, LinkNode*& N) {
if (!L || !N) return false;
LinkNode* p = L;
while (p->next) {
p = p->next;
}
if (!p->next) {
N->prev = p;
N->next = NULL;
}else{
p->prev->next = N;
N->prev = p->prev;
N->next = p;
}
p->next = N;
return true;
}
void printDbList(LinkList*& L) {
if (!L) {
cout << "打印链表失败!" << endl;
return;
}
else if (!L->next) {
cout << "链表为空!" << endl;
return;
}
cout << "正向打印双向链表!" << endl;
LinkNode* p = L;
while (p->next) {
p = p->next;
cout << p->data << "\\t" << endl;
}
cout << "正在反向打印双向链表!" << endl;
while (p->prev) {
cout << p->data << "\\t" << endl;
p = p->prev;
}
return;
}
共享双向链表
原理:在linux,有大量的数据结构需要使用双向链表,若采用传统的双向链表的实现方式,每一个双向链表都只能存储一种特定的数据,那么每个双向链表都需要为维护和各自的函数,这样子是非常麻烦的。因此,我们用共享双向链表来解决。
这个双向链表只作为承载数据的货车,货车相同,而上面放置的数据,可以是任意的。
代码实现
typedef struct _DoubleLinkNode{
_DoubleLinkNode* next;
_DoubleLinkNode* prev;
}DbLinkNode,DbLinkList;
typedef struct {
int fd;
time_t timeout;
DbLinkList node;
}ConnTimeout;
bool initDbList(DbLinkNode& L) {
L.next = NULL;
L.prev = NULL;
return true;
}
bool addDbListEnd(DbLinkList& L, DbLinkNode& N) {
DbLinkNode* p = &L;
while (p->next) {
p = p->next;
}
if (!p->next) {
N.prev = p;
N.next = NULL;
}
else {
p->prev->next = &N;
N.prev = p->prev;
N.next = p;
}
p->next = &N;
return true;
}
int main() {
ConnTimeout* c = NULL,*s = NULL;
int fd = 0;
int n = 0;
c = new ConnTimeout;
c->fd = -1;
c->timeout = -1;
initDbList(c->node);
cout << "请输入元素的个数:";
cin >> n;
for (int i = 0;i < n;i++) {
s = new ConnTimeout;
cout << "输入第" << i + 1 << "个元素的fd:";
cin >> s->fd;
initDbList(s->node);
addDbListEnd(c->node, s->node);
}
//遍历双向链表中元素
cout << "开始遍历双向链表中的所有元素的fd" <<endl;
DbLinkNode* p = NULL;
p = &(c->node);
int offset = offsetof(ConnTimeout, node),number = 0;
cout << "offset = " << offset << endl;
while (p) {
int* ptr = (int*)((size_t)p - offset);
cout << "第" << number << "个元素:" << *ptr << endl;
p = p->next;
number++;
}
//销毁链表
p = &(c->node);
while (p) {
ConnTimeout* ct = (ConnTimeout*)((size_t)p - offset);
int* ptr = (int*)((size_t)p - offset);
cout << "删除fd = " << *ptr << endl;
p = p->next;
delete ct;
}
return 0;
}
这里定义了一个ConnTimeout结构体里面放着对应的链表节点,fd和timeout。在函数addDbListEnd()中,在尾部追加元素的方法采用的是,讲ConnTimeout结构体中的链表节点相连,而访问其fd和timeout值的方法是:先定位到头节点的node,然后在通过offsetof来得知node相对于结构体首部的偏移量offset,对指针做一些转化减去这个偏移量,我们就可以通过node来访问到fd和timeout。