结合中断上下文切换和进程上下文切换分析Linux内核的一般执行过程
Posted asclin
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了结合中断上下文切换和进程上下文切换分析Linux内核的一般执行过程相关的知识,希望对你有一定的参考价值。
一、实验目标
以fork和execve系统调用为例分析中断上下文的切换
分析execve系统调用中断上下文的特殊之处
分析fork子进程启动执行时进程上下文的特殊之处
以系统调用作为特殊的中断,结合中断上下文切换和进程上下文切换分析Linux系统的一般执行过程
二、实验过程
理解task_struct数据结构
进程是处于执行期的程序以及它所管理的资源(如打开的文件、挂起的信号、进程状态、地址空间等等)的总称。
在linux操作系统下,当触发任何一个事件时,系统都将它定义为一个进程,并且给予这个进程一个ID,即PID。
那么如何产生一个进程呢?简单来说就是“执行一个程序或命令”。
Linux内核通过一个被称为进程描述符的task_struct结构体来管理进程,这个结构体包含了一个进程所需的所有信息。
为了管理进程,操作系统必须对每个进程所做的事情进行清楚的描述,为此,操作系统使用数据结构来代表处理不同的实体,这个数据结构就是通常所说的进程描述符或进程控制块(PCB)。
系统调用
fork函数
函数说明:在Unix/Linux中用fork函数创建一个新的进程。进程是由当前已有进程调用fork函数创建,分叉的进程叫子进程,创建者叫父进程。该函数的特点是调用一次,返回两次,一次是在父进程,一次是在子进程。两次返回的区别是子进程的返回值为0,父进程的返回值是新子进程的ID。子进程与父进程继续并发运行。如果父进程继续创建更多的子进程,子进程之间是兄弟关系,同样子进程也可以创建自己的子进程,这样可以建立起定义关系的进程之间的一种层次关系。
不管系统使用clone(),vfork(),fork()最后都是调用do_fork()实现子程序的创建,首先会从内存分配一个8k的空间用来存储进程描述符和内核栈,拷贝父进程的描述符内容到新进程的描述符中,检查拥有当前进程的用户所拥有的进程最大数,如果进程使用了模块,则增加对应模块的引用计数,更新从父进程拷贝过来的一些标志,获得一个进程id号,更新一些不能从父进程继承的描述符的内容,建立进程的fs,files,mm,sighand结构并拷贝相应的父进程的内容,利用cpu寄存器中的值来初始化子进程的内核堆栈,把eax寄存器值为0(eax保存返回值),同时保存esp和eip的值。将子进程描述符插入到进程链表中,同时插入到进程运行链表中,这时候已完成大部分工作,当系统调用结束时会调用调度程序来决定何时调用子程序,同时调度程序调度子程序时会继续完善子程序,利用上面保存的esp,eip值来装载寄存器,同时进入到ret_from_sys_call()函数中,该函数是系统调用的返回程序,会利用子进程前面初始化好的内核栈来装在cpu寄存器(恢复现场),由于子进程和父进程执行的是同样的代码,所以当系统调用结束返回时检查eax寄存器中的返回值,如果是0就给子进程,如果是pid就给父进程,所以通常当fork一个新的子进程时我们可以通过返回值来判断当前进程是父进程还是子进程,所以我们可以在fork程序下面加上if语句在配合execv系统调用来装载我们需要执行的代码。
fork, vfork和clone的系统调用定义是依赖于体系结构的, 因为在用户空间和内核空间之间传递参数的方法因体系结构而异,但他们都调用体系结构无关的_do_fork(或者早期的do_fork)函数, 负责进程的复制。
_do_fork以调用copy_process开始, 后者执行生成新的进程的实际工作, 并根据指定的标志复制父进程的数据。在子进程生成后, 内核必须执行一些收尾操作,如复制进程信息,子进程加入调度器等。
copy_process流程:调用 dup_task_struct复制当前的task_struct->检查进程数限制并初始化CPU 定时器等信息->调用 sched_fork 初始化进程数据结构,并把进程状态设置为 TASK_RUNNING->复制所以进程信息并调用copy_thread_tls初始化子进程内核栈->为新进程分配设置新的pid。
do_fork的部分代码如下:
long do_fork(unsigned long clone_flags, unsigned long stack_start, unsigned long stack_size, int __user *parent_tidptr, int __user *child_tidptr) { struct task_struct *p; int trace = 0; long nr; // ... // 复制进程描述符,返回创建的task_struct的指针 p = copy_process(clone_flags, stack_start, stack_size, child_tidptr, NULL, trace); if (!IS_ERR(p)) { struct completion vfork; struct pid *pid; trace_sched_process_fork(current, p); // 取出task结构体内的pid pid = get_task_pid(p, PIDTYPE_PID); nr = pid_vnr(pid); if (clone_flags & CLONE_PARENT_SETTID) put_user(nr, parent_tidptr); // 如果使用的是vfork,那么必须采用某种完成机制,确保父进程后运行 if (clone_flags & CLONE_VFORK) { p->vfork_done = &vfork; init_completion(&vfork); get_task_struct(p); } // 将子进程添加到调度器的队列,使得子进程有机会获得CPU wake_up_new_task(p); // ... // 如果设置了 CLONE_VFORK 则将父进程插入等待队列,并挂起父进程直到子进程释放自己的内存空间 // 保证子进程优先于父进程运行 if (clone_flags & CLONE_VFORK) { if (!wait_for_vfork_done(p, &vfork)) ptrace_event_pid(PTRACE_EVENT_VFORK_DONE, pid); } put_pid(pid); } else { nr = PTR_ERR(p); } return nr;
execve系统调用跟之前的过的fork系统调用的总体流程大致相同,只是在具体系统调用函数处理时略有不同。execve系统调用加载一个新的可执行程序,在处理过程中单独创建了一个中断上下文,即修改了触发该系统调用时所保存的那个中断上下文,使得返回到用户态的位置修改为新程序的elf_entry或者ld动态链接器的起点地址
sys_execve的核心是调用do_execve函数,传给do_execve的第一个参数是已经拷贝到内核空间的路径名filename,第二个和第三个参数仍然是系统调用execve的第二个参数argv和第三个参数envp,它们代表的传给可执行文件的参数和环境变量仍然保留在用户空间中。简单分析一下这个函数的思路:先通过open_err()函数找到并打开可执行文件,然后要从打开的文件中将可执行文件的信息装入一个数据结构linux_binprm,do_execve先对参数和环境变量的技术,并通过prepare_binprm读入开头的128个字节到linux_binprm结构的bprm缓冲区,最后将执行的参数从用户空间拷贝到数据结构bprm中。内核中有一个formats队列,该队列的每个成员认识并只处理一种格式的可执行文件,bprm缓冲区中的128个字节中有格式信息,便要通过这个队列去辨认。do_execve()中的关键是最后执行一个search_binary_handler()函数,找到对应的执行文件格式,并返回一个值,这样程序就可以执行了。
do_execve 定义在 <fs/exec.c> 中,关键代码解析如下。
int do_execve(char * filename, char __user *__user *argv, char __user *__user *envp, struct pt_regs * regs) { struct linux_binprm *bprm; //保存要执行的文件相关的数据 struct file *file; int retval; int i; retval = -ENOMEM; bprm = kzalloc(sizeof(*bprm), GFP_KERNEL); if (!bprm) goto out_ret; //打开要执行的文件,并检查其有效性(这里的检查并不完备) file = open_exec(filename); retval = PTR_ERR(file); if (IS_ERR(file)) goto out_kfree; //在多处理器系统中才执行,用以分配负载最低的CPU来执行新程序 //该函数在include/linux/sched.h文件中被定义如下: // #ifdef CONFIG_SMP // extern void sched_exec(void); // #else // #define sched_exec() {} // #endif sched_exec(); //填充linux_binprm结构 bprm->p = PAGE_SIZE*MAX_ARG_PAGES-sizeof(void *); bprm->file = file; bprm->filename = filename; bprm->interp = filename; bprm->mm = mm_alloc(); retval = -ENOMEM; if (!bprm->mm) goto out_file; //检查当前进程是否在使用LDT,如果是则给新进程分配一个LDT retval = init_new_context(current, bprm->mm); if (retval 0) goto out_mm; //继续填充linux_binprm结构 bprm->argc = count(argv, bprm->p / sizeof(void *)); if ((retval = bprm->argc) 0) goto out_mm; bprm->envc = count(envp, bprm->p / sizeof(void *)); if ((retval = bprm->envc) 0) goto out_mm; retval = security_bprm_alloc(bprm); if (retval) goto out; //检查文件是否可以被执行,填充linux_binprm结构中的e_uid和e_gid项 //使用可执行文件的前128个字节来填充linux_binprm结构中的buf项 retval = prepare_binprm(bprm); if (retval 0) goto out; //将文件名、环境变量和命令行参数拷贝到新分配的页面中 retval = copy_strings_kernel(1, &bprm->filename, bprm); if (retval 0) goto out; bprm->exec = bprm->p; retval = copy_strings(bprm->envc, envp, bprm); if (retval 0) goto out; retval = copy_strings(bprm->argc, argv, bprm); if (retval 0) goto out; //查询能够处理该可执行文件格式的处理函数,并调用相应的load_library方法进行处理 retval = search_binary_handler(bprm,regs); if (retval >= 0) { free_arg_pages(bprm); //执行成功 security_bprm_free(bprm); acct_update_integrals(current); kfree(bprm); return retval; } out: //发生错误,返回inode,并释放资源 for (i = 0 ; i MAX_ARG_PAGES ; i++) { struct page * page = bprm->page; if (page) __free_page(page); } if (bprm->security) security_bprm_free(bprm); out_mm: if (bprm->mm) mmdrop(bprm->mm); out_file: if (bprm->file) { allow_write_access(bprm->file); fput(bprm->file); } out_kfree: kfree(bprm); out_ret: return retval; }
在该函数的最后,又调用了fs/exec.c文件中定义的search_binary_handler函数来查询能够处理相应可执行文件格式的处理器,并调用相应的load_library方法以启动进程。
execve调用总结如下:
-
execve系统调用陷入内核,并传入命令行参数和shell上下文环境
-
execve陷入内核的第一个函数:do_execve,该函数封装命令行参数和shell上下文
-
do_execve调用do_execveat_common,后者进一步调用__do_execve_file,打开ELF文件并把所有的信息一股脑的装入linux_binprm结构体
-
__do_execve_file中调用search_binary_handler,寻找解析ELF文件的函数
-
search_binary_handler找到ELF文件解析函数load_elf_binary
-
load_elf_binary解析ELF文件,把ELF文件装入内存,修改进程的用户态堆栈(主要是把命令行参数和shell上下文加入到用户态堆栈),修改进程的数据段代码段
-
load_elf_binary调用start_thread修改进程内核堆栈(特别是内核堆栈的ip指针)
-
进程从execve返回到用户态后ip指向ELF文件的main函数地址,用户态堆栈中包含了命令行参数和shell上下文环境
结合中断上下文切换和进程上下文切换分析Linux系统的一般执行过程:
中断上下文:
为了快速响应硬件的事件,中断处理会打断进程的正常调度和执行,转而调用中断处理程序,响应设备事件。而在打断其他进程时,就需要将进程当前的状态保存下来,这样在中断结束后,进程仍然可以从原来的状态恢复运行
跟进程上下文不同,中断上下文切换并不涉及到进程的用户态。所以,即便中断过程打断了一个正处于用户态的进程,也不需要保存和恢复这个进程的虚拟内存、全局变量等用户态资源。中断上下文,其实只包括内核态中断服务程序执行所必需的状态,包括CPU寄存器、内核堆栈、硬件中断参数等。
对同一个CPU来说,中断处理比进程拥有更高的优先级,所以中断上下文切换并不会与进程上下文切换同时发生。同样道理,由于中断会打断正常进程的调度和执行,所以大部分中断处理程序都短小精悍,以便尽可能快的执行结束。
中断是由软硬件触发中断,查找IDT表内相应中断门,SAVE_ALL宏在栈中保存中断处理程序可能会使用的所有CPU寄存器(eflags、cs、eip、ss、esp已由硬件自动保存),并将栈顶地址保存到eax寄存器中来形成。然后中断处理程序调用do_IRQ(pt_regs*)函数,查找irq_desc数组来执行具体的中断逻辑。
进程上下文:
进程则是资源拥有的基本单位,进程切换是由内核实现的,所以进程上下⽂切换过程中最关键的栈顶寄存器sp切换是通过进程描述符的thread.sp实现的,指令指针寄存器ip的切换是在内核堆栈切换的基础上巧妙利⽤call/ret指令实现的。 切换进程需要在
不同的进程间切换。但⼀般进程上下⽂切换是嵌套到中断上下⽂切换中的,⽐如前述系统调⽤作为⼀种中断先陷⼊内核,即发⽣中断保存现场和系统调⽤处理过程。其中调⽤了schedule函数发⽣进程上下⽂切换,当系统调⽤返回到⽤户态时会恢复现场,⾄此完成了保存现场和恢复现场,即完成了中断上下⽂切换。
进程的上下文不仅包括了虚拟内存、栈、全局变量等用户空间的资源,还包括了内核堆栈、寄存器等内核空间的状态。因此进程的上下文切换就比系统调用时多了一步:在保存当前进程的内核状态和CPU寄存器之前,需要先把该进程的虚拟内存、栈等保存下来;而加载下一进程的内核态后,还需要刷新进程的虚拟内存和用户栈。
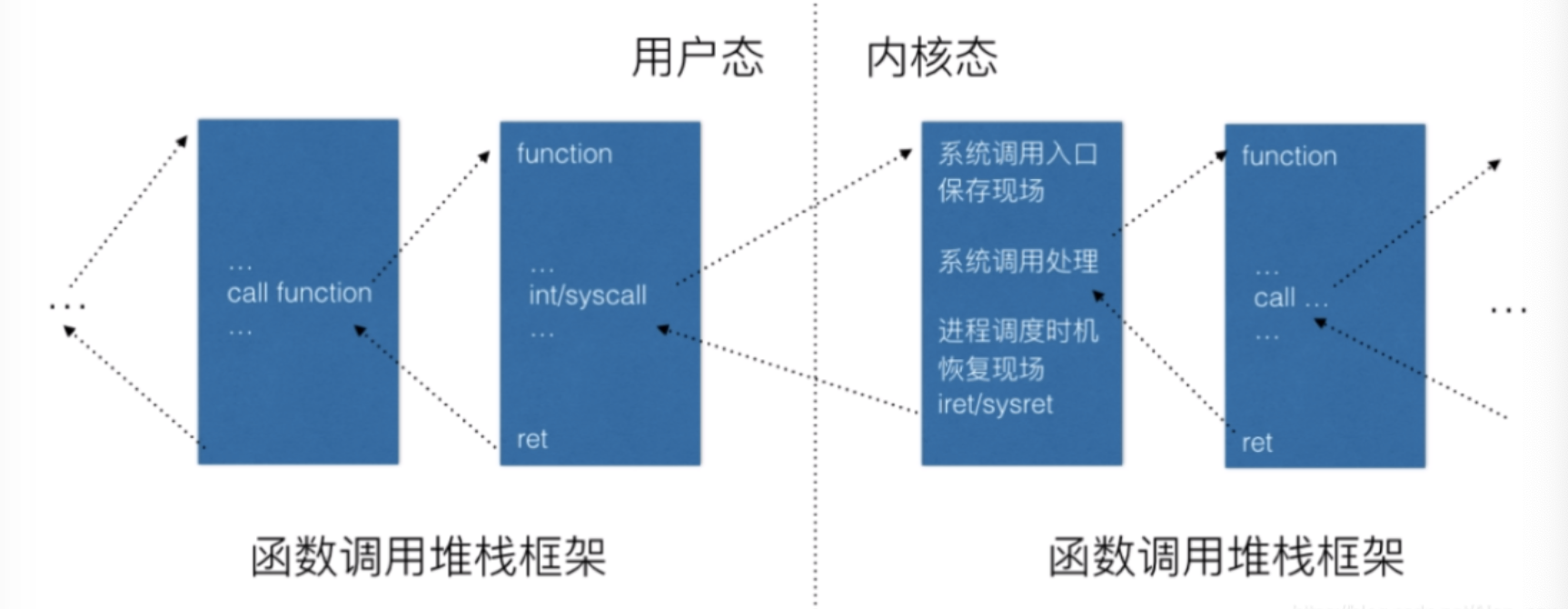
linux系统的一般执行过程:
首先是正在运行的用户态进程发生中断(包括异常、系统调用等),CPU完成load cs:rip(entry of a specific ISR),即跳转到中断处理程序入口。
中断上下文切换,具体包括如下几点:
1.swapgs指令保存现场即保存当前CPU寄存器状态。
2.rsp point to kernel stack,加载当前进程内核堆栈栈顶地址到RSP寄存器。
3.save cs:rip/ss:rsp/rflags:将当前CPU关键上下文压入中断进程的内核堆栈,快速系统调用是由系统调用入口处的汇编代码实现的。
此时完成了中断上下文切换,即从中断进程的用户态到内核态。
中断处理过程中或中断返回前调用了schedule函数,其中完成了进程调度算法选择next进程、进程地址空间切换、以及switch_to关键的进程上下文切换等。
switch_to调用了__switch_to_asm汇编代码做了关键的进程上下文切换。将当前进程的内核堆栈切换到进程调度算法选出来的next进程的内核堆栈,
并完成了进程上下文所需的指令指针寄存器状态切换。之后开始运行切换进程。中断上下文恢复,与中断上下文切换相对应。
以上是关于结合中断上下文切换和进程上下文切换分析Linux内核的一般执行过程的主要内容,如果未能解决你的问题,请参考以下文章
结合中断上下文切换和进程上下文切换分析Linux内核的一般执行过程
结合中断上下文切换和进程上下文切换分析Linux内核的一般执行过程
结合中断上下文切换和进程上下文切换分析Linux内核的一般执行过程
结合中断上下文切换和进程上下文切换分析Linux内核的一般执行过程