Linux 磁盘
Posted 交流分享技术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Linux 磁盘相关的知识,希望对你有一定的参考价值。
磁盘
磁盘为系统提供了最基本的持久化存储。
文件系统
文件系统则在磁盘的基础上,提供了一个用来管理文件的树状结构
组织方式不同,就会形成不同的文件系统。
为了方便管理,Linux 文件系统为每个文件都分配两个数据结构,索引节点(index node)和目录项(directory entry)。它们主要用来记录文件的元信息和目录结构。
-
索引节点,简称为 inode,用来记录文件的元数据,比如 inode 编号、文件大小、访问权限、修改日期、数据的位置等。索引节点和文件一一对应,它跟文件内容一样,都会被持久化存储到磁盘中。所以记住,索引节点同样占用磁盘空间。
-
目录项,简称为 dentry,用来记录文件的名字、索引节点指针以及与其他目录项的关联关系。多个关联的目录项,就构成了文件系统的目录结构。不过,不同于索引节点,目录项是由内核维护的一个内存数据结构,所以通常也被叫做目录项缓存。
引节点是每个文件的唯一标志,而目录项维护的正是文件系统的树状结构。目录项和索引节点的关系是多对一,你可以简单理解为,一个文件可以有多个别名。
举个例子,通过硬链接为文件创建的别名,就会对应不同的目录项,不过这些目录项本质上还是链接同一个文件,所以,它们的索引节点相同
磁盘读写的最小单位是扇区,然而扇区只有 512B 大小,如果每次都读写这么小的单位,效率一定很低。所以,文件系统又把连续的扇区组成了逻辑块,然后每次都以逻辑块为最小单元,来管理数据。常见的逻辑块大小为 4KB,也就是由连续的 8 个扇区组成。
不过,这里有两点需要你注意。
第一,目录项dentry本身就是一个内存缓存,而超级块、索引节点和逻辑块,都是存储在磁盘中的持久化数据为了协调慢速磁盘与快速 CPU 的性能差异,文件内容会缓存到page Cache 中。索引节点inode也会缓存到内存中,加速文件的访问。
第二,磁盘在执行文件系统格式化时,会被分成三个存储区域,超级块、索引节点区和数据块区。
-
超级块,存储整个文件系统的状态。
-
索引节点区,用来存储索引节点。
-
索引节点的容量,(也就是 Inode 个数)是在格式化磁盘时设定好的,一般由格式化工具自动生成。当你发现索引节点空间不足,但磁盘空间充足时,很可能就是过多小文件导致的。
-
-
数据块区,则用来存储文件数据。
虚拟文件系统 VFS(Virtual File System)
Linux 文件系统的四大基本要素
-
目录项,记录了文件的名字,以及文件与其他目录项之间的目录关系。
-
索引节点,记录了文件的元数据。inode编号,
-
逻辑块,是由连续磁盘扇区构成的最小读写单元,用来存储文件数据。
-
超级块,用来记录文件系统整体的状态,如索引节点和逻辑块的使用情况等。
为了支持各种不同的文件系统,Linux 内核在用户进程和文件系统的中间又引入了一个抽象层,也就是虚拟文件系统 VFS(Virtual File System)。
VFS 定义了一组所有文件系统都支持的数据结构和标准接口

三类文件系统
按照存储位置的不同,这些文件系统可以分为三类。
第一类是基于磁盘的文件系统,也就是把数据直接存储在计算机本地挂载的磁盘中。常见的 Ext4、XFS、OverlayFS 等,都是这类文件系统。
第二类是基于内存的文件系统,也就是我们常说的虚拟文件系统。这类文件系统,不需要任何磁盘分配存储空间,但会占用内存。我们经常用到的 /proc 文件系统,其实就是一种最常见的虚拟文件系统。此外,/sys 文件系统也属于这一类,主要向用户空间导出层次化的内核对象。
第三类是网络文件系统,也就是用来访问其他计算机数据的文件系统,比如 NFS、SMB、iSCSI 等。
I/O
把文件系统挂载到挂载点后,你就能通过挂载点,再去访问它管理的文件了。VFS 提供了一组标准的文件访问接口。这些接口以系统调用的方式,提供给应用程序使用。就拿 cat 命令来说,它首先调用 open() ,打开一个文件;然后调用 read() ,读取文件的内容;最后再调用 write() ,把文件内容输出到控制台的标准输出中:
int open(const char *pathname, int flags, mode_t mode);
ssize_t read(int fd, void *buf, size_t count);
ssize_t write(int fd, const void *buf, size_t count);
缓冲与非缓冲 I/O、直接与非直接 I/O、阻塞与非阻塞 I/O、同步与异步 I/O
缓冲与非缓冲 I/O
根据是否利用标准库缓存,可以把文件 I/O 分为缓冲 I/O 与非缓冲 I/O。
-
缓冲 I/O,是指利用标准库缓存来加速文件的访问,而标准库内部再通过系统调度访问文件。
-
非缓冲 I/O,是指直接通过系统调用来访问文件,不再经过标准库缓存。
注意,这里所说的“缓冲”,是指标准库内部实现的缓存。比方说,你可能见到过,很多程序遇到换行时才真正输出,而换行前的内容,其实就是被标准库暂时缓存了起来。无论缓冲 I/O 还是非缓冲 I/O,它们最终还是要经过系统调用来访问文件。而根据上一节内容,我们知道,系统调用后,还会通过页缓存,来减少磁盘的 I/O 操作。
直接与非直接 I/O
根据是否利用操作系统的页缓存,可以把文件 I/O 分为直接 I/O 与非直接 I/O。
-
直接 I/O,是指跳过操作系统的页缓存,直接跟文件系统交互来访问文件。
-
非直接 I/O 正好相反,文件读写时,先要经过系统的页缓存,然后再由内核或额外的系统调用,真正写入磁盘。想要实现直接 I/O,需要你在系统调用中,指定 O_DIRECT 标志。如果没有设置过,默认的是非直接 I/O。
不过要注意,直接 I/O、非直接 I/O,本质上还是和文件系统交互。如果是在数据库等场景中,你还会看到,跳过文件系统读写磁盘的情况,也就是我们通常所说的裸 I/O。
阻塞与非阻塞 I/O
根据应用程序是否阻塞自身运行,可以把文件 I/O 分为阻塞 I/O 和非阻塞 I/O:
-
所谓阻塞 I/O,是指应用程序执行 I/O 操作后,如果没有获得响应,就会阻塞当前线程,自然就不能执行其他任务。
-
所谓非阻塞 I/O,是指应用程序执行 I/O 操作后,不会阻塞当前的线程,可以继续执行其他的任务,随后再通过轮询或者事件通知的形式,获取调用的结果。
比方说,访问管道或者网络套接字时,设置 O_NONBLOCK 标志,就表示用非阻塞方式访问;而如果不做任何设置,默认的就是阻塞访问。
同步和异步 I/O
根据是否等待响应结果,可以把文件 I/O 分为同步和异步 I/O:
-
所谓同步 I/O,是指应用程序执行 I/O 操作后,要一直等到整个 I/O 完成后,才能获得 I/O 响应。
-
所谓异步 I/O,是指应用程序执行 I/O 操作后,不用等待完成和完成后的响应,而是继续执行就可以。等到这次 I/O 完成后,响应会用事件通知的方式,告诉应用程序。
举个例子,在操作文件时,如果你设置了 O_SYNC 或者 O_DSYNC 标志,就代表同步 I/O。
如果设置了 O_DSYNC,就要等文件数据写入磁盘后,才能返回;而 O_SYNC,则是在 O_DSYNC 基础上,要求文件元数据也要写入磁盘后,才能返回。
再比如,在访问管道或者网络套接字时,设置了 O_ASYNC 选项后,相应的 I/O 就是异步 I/O。这样,内核会再通过 SIGIO 或者 SIGPOLL,来通知进程文件是否可读写。
你可能发现了,这里的好多概念也经常出现在网络编程中。比如非阻塞 I/O,通常会跟 select/poll 配合,用在网络套接字的 I/O 中。
阻塞 / 非阻塞和同步 / 异步,其实就是两个不同角度的 I/O 划分方式。它们描述的对象也不同,阻塞 / 非阻塞针对的是 I/O 调用者(即应用程序),而同步 / 异步针对的是 I/O 执行者(即系统)。
通用块层
在 Linux 中,磁盘实际上是作为一个块设备来管理的,也就是以块为单位读写数据,并且支持随机读写。每个块设备都会被赋予两个设备号,分别是主、次设备号。主设备号用在驱动程序中,用来区分设备类型;而次设备号则是用来给多个同类设备编号。
通用块层: 处在文件系统和磁盘驱动中间的一个块设备抽象层。
-
第一个功能跟虚拟文件系统的功能类似。向上,为文件系统和应用程序,提供访问块设备的标准接口;向下,把各种异构的磁盘设备抽象为统一的块设备,并提供统一框架来管理这些设备的驱动程序。
-
第二个功能,通用块层还会给文件系统和应用程序发来的 I/O 请求排队,并通过重新排序、请求合并等方式,提高磁盘读写的效率。
Linux 内核支持四种 I/O 调度算法,分别是 NONE、NOOP、CFQ 以及 DeadLine。
-
NONE ,更确切来说,并不能算 I/O 调度算法。因为它完全不使用任何 I/O 调度器,对文件系统和应用程序的 I/O 其实不做任何处理,常用在虚拟机中(此时磁盘 I/O 调度完全由物理机负责)。
-
NOOP ,是最简单的一种 I/O 调度算法。它实际上是一个先入先出的队列,只做一些最基本的请求合并,常用于 SSD 磁盘。
-
CFQ(Completely Fair Scheduler),也被称为完全公平调度器,是现在很多发行版的默认 I/O 调度器,它为每个进程维护了一个 I/O 调度队列,并按照时间片来均匀分布每个进程的 I/O 请求。类似于进程 CPU 调度,CFQ 还支持进程 I/O 的优先级调度,所以它适用于运行大量进程的系统,像是桌面环境、多媒体应用等。
-
DeadLine 调度算法,分别为读、写请求创建了不同的 I/O 队列,可以提高机械磁盘的吞吐量,并确保达到最终期限(deadline)的请求被优先处理。DeadLine 调度算法,多用在 I/O 压力比较重的场景,比如数据库等。
I/O栈
由上到下分为三个层次,分别是文件系统层、通用块层和设备层。这三个 I/O 层的关系如下图所示,这其实也是 Linux 存储系统的 I/O 栈全景图。
-
文件系统层,包括虚拟文件系统和其他各种文件系统的具体实现。它为上层的应用程序,提供标准的文件访问接口;对下会通过通用块层,来存储和管理磁盘数据。
-
通用块层,包括块设备 I/O 队列和 I/O 调度器。它会对文件系统的 I/O 请求进行排队,再通过重新排序和请求合并,然后才要发送给下一级的设备层。
-
设备层,包括存储设备和相应的驱动程序,负责最终物理设备的 I/O 操作。

(图片来自 Linux Storage Stack Diagram )
磁盘性能指标
五个常见指标,使用率、饱和度、IOPS、吞吐量以及响应时间
-
使用率,是指磁盘处理 I/O 的时间百分比。过高的使用率(比如超过 80%),通常意味着磁盘 I/O 存在性能瓶颈。
-
饱和度,是指磁盘处理 I/O 的繁忙程度。过高的饱和度,意味着磁盘存在严重的性能瓶颈。当饱和度为 100% 时,磁盘无法接受新的 I/O 请求。
-
IOPS(Input/Output Per Second),是指每秒的 I/O 请求数。
-
吞吐量,是指每秒的 I/O 请求大小。
-
响应时间,是指 I/O 请求从发出到收到响应的间隔时间。
磁盘 I/O 观测
iostat 是最常用的磁盘 I/O 性能观测工具,它提供了每个磁盘的使用率、IOPS、吞吐量等各种常见的性能指标,当然,这些指标实际上来自 /proc/diskstats。
# -d -x表示显示所有磁盘I/O的指标
$ iostat -d -x 1
Device r/s w/s rkB/s wkB/s rrqm/s wrqm/s %rrqm %wrqm r_await w_await aqu-sz rareq-sz wareq-sz svctm %util
loop0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
loop1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
sda 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
sdb 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 1234567
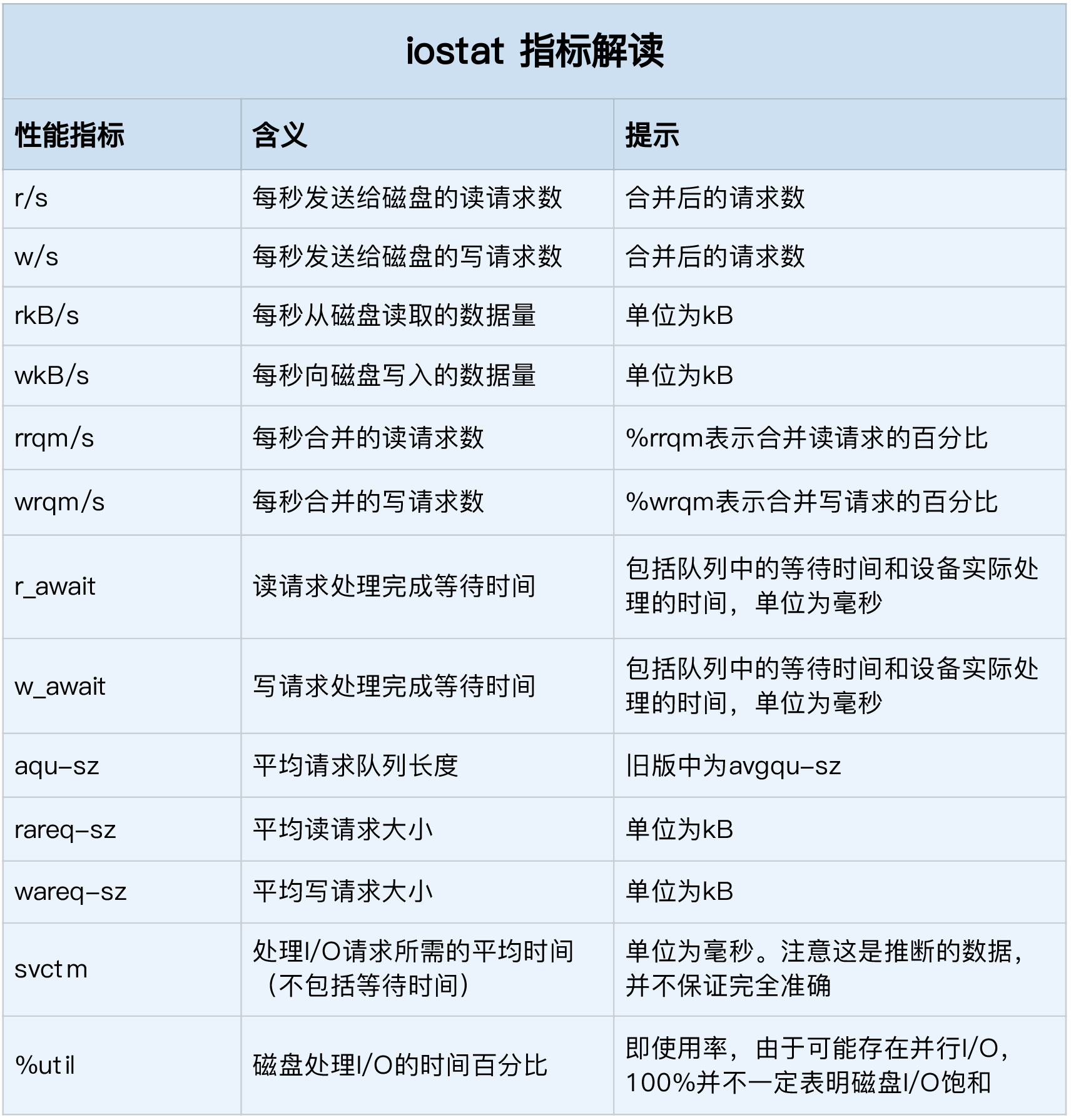
-
%util ,就是我们前面提到的磁盘 I/O 使用率;
-
r/s+ w/s ,就是 IOPS;
-
rkB/s+wkB/s ,就是吞吐量;
-
r_await+w_await ,就是响应时间
进程 I/O 观测
pidstat 加上 -d 参数,就可以看到进程的 I/O 情况
$ pidstat -d 1
13:39:51 UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command
13:39:52 102 916 0.00 4.00 0.00 0 rsyslogd123
-
用户 ID(UID)和进程 ID(PID) 。
-
每秒读取的数据大小(kB_rd/s) ,单位是 KB。
-
每秒发出的写请求数据大小(kB_wr/s) ,单位是 KB。
-
每秒取消的写请求数据大小(kB_ccwr/s) ,单位是 KB。
-
块 I/O 延迟(iodelay),包括等待同步块 I/O 和换入块 I/O 结束的时间,单位是时钟周期。
以上是关于Linux 磁盘的主要内容,如果未能解决你的问题,请参考以下文章
Swift新async/await并发中利用Task防止指定代码片段执行的数据竞争(Data Race)问题
linux打开终端如何启动scala,如何在终端下运行Scala代码片段?
Android 逆向Linux 文件权限 ( Linux 权限简介 | 系统权限 | 用户权限 | 匿名用户权限 | 读 | 写 | 执行 | 更改组 | 更改用户 | 粘滞 )(代码片段