rancher2.4平台导入的k8s集群无法监控etcd解决办法
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了rancher2.4平台导入的k8s集群无法监控etcd解决办法相关的知识,希望对你有一定的参考价值。
今天搭建了一个新的k8s集群,然后通过rancher平台纳管。rancher平台是一个比较好用的web页面,里面可以一键安装监控配置告警等用起来还是比较方便的。但是其它数据都可以正常收到promethues里面,唯独就没有etcd集群的数据。使用grafana打开发现etcd的监控是空的。
本来想通过修改promethues的配置来收集etcd的监控数据,但是这个promethues是通过operator安装的。前面修改完后面就被还原了。琢磨了很久发现rancher的这个可以通过ui界面选择自定义监控指标的方式来添加。从k8s的yaml文件的角度来看就是添加一个注释field.cattle.io/workloadMetrics: ‘[{"path":"/metrics","port":2379,"schema":"HTTP"}]‘。但是etcd无法添加注释让promethues来获取监控数据。
etcd中默认是开启了监控的,通过客户端监听端口加上/metrics就能获取到数据。这个协议是https的,不过需要使用ssl认证才能正常访问。既然是网页那就可以使用nginx代理,整个思路是使用nginx代理etcd的这个监控页面。利用注释的方式让rancher的promethues可以通过自定义监控方式获取到etcd的监控数据。
首先添加配置文件:
把证书数据通过配置文件保存到configmap中。
里面会有三个键分别是etcd.ca、etcd.crt、etcd.key,分别对应k8s的master主机上/etc/kubernetes/pki/etcd/目录中的ca.crt、healthcheck-client.crt、healthcheck-client.key三个文件的内容。
然后为每个deployment配置不同的nginx配置文件。
三个配置:
映射键的名字为nginx.conf内容如下:
user root;
worker_processes auto;
worker_cpu_affinity auto;
worker_rlimit_nofile 65535;
error_log logs/error.log warn;
pid logs/nginx.pid;
events {
use epoll;
multi_accept on;
worker_connections 65535;
}
http {
include mime.types;
default_type application/octet-stream;
server_names_hash_bucket_size 128;
client_header_buffer_size 128k;
large_client_header_buffers 4 128k;
client_max_body_size 600m;
client_body_buffer_size 2m;
#charset utf-8;
sendfile on;
tcp_nopush on;
keepalive_timeout 60 50;
send_timeout 10s;
check_shm_size 6m;
tcp_nodelay on;
server_tokens off;
add_header X-Frame-Options SAMEORIGIN;
gzip on;
gzip_min_length 1k;
gzip_buffers 4 16k;
gzip_http_version 1.1;
gzip_comp_level 2;
gzip_types text/css;
gzip_vary on;
proxy_connect_timeout 600;
proxy_read_timeout 600;
proxy_send_timeout 600;
proxy_buffer_size 512k;
proxy_buffers 4 512k;
proxy_busy_buffers_size 512k;
proxy_temp_file_write_size 1024k;
server {
listen 2379;
large_client_header_buffers 4 16k;
client_max_body_size 300m;
client_body_buffer_size 512k;
proxy_connect_timeout 900s;
proxy_read_timeout 900s;
proxy_send_timeout 900s;
proxy_buffer_size 128k;
proxy_buffers 4 64k;
proxy_busy_buffers_size 128k;
proxy_temp_file_write_size 512k;
location / {
add_header Access-Control-Allow-Origin *;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header Host $http_host;
proxy_set_header X-Forwarded-Proto https;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-Port $server_port;
proxy_redirect off;
proxy_http_version 1.1;
proxy_ssl_certificate /etc/etcd/etcd.crt; #这个目录是上面的证书配置文件映射的位置
proxy_ssl_certificate_key /etc/etcd/etcd.key;
proxy_ssl_trusted_certificate /etc/etcd/etcd.ca;
proxy_ssl_protocols TLSv1 TLSv1.1 TLSv1.2;
proxy_ssl_ciphers HIGH:!aNULL:!MD5;
proxy_ssl_verify off;
proxy_ssl_verify_depth 2;
proxy_ssl_session_reuse on;
proxy_pass https://192.168.0.1:2379; #这个是真实的etcd地址,三个节点三个地址,分别配置。
}
}
log_format json ‘{"@timestamp":"$time_iso8601",‘
# ‘"host":"$server_addr",‘
‘"clientip":"$remote_addr",‘
‘"size":$body_bytes_sent,‘
# ‘"con_length":"$content_length",‘
# ‘"cookie":"$http_cookie",‘
‘"responsetime":$request_time,‘
‘"upstreamtime":"$upstream_response_time",‘
‘"upstreamhost":"$upstream_addr",‘
‘"http_host":"$host",‘
‘"url":"$uri",‘
‘"xff":"$http_x_forwarded_for",‘
‘"referer":"$http_referer",‘
‘"agent":"$http_user_agent",‘
‘"status":"$status"}‘;
access_log logs/access.log json;
}然后部署三个deployment:
apiVersion: apps/v1
kind: Deployment
metadata:
name: etcd-master01
namespace: cattle-prometheus
spec:
selector:
matchLabels:
app: etcd-metrics01
template:
metadata:
annotations:
field.cattle.io/workloadMetrics: ‘[{"path":"/metrics","port":2379,"schema":"HTTP"}]‘
labels:
app: etcd-metrics01
spec:
containers:
- image: images.example.com/images:nginx #替换成自己的nginx镜像,或者公共nginx镜像
imagePullPolicy: IfNotPresent
livenessProbe:
failureThreshold: 3
httpGet:
path: /metrics
port: 2379
scheme: HTTP
initialDelaySeconds: 10
periodSeconds: 2
successThreshold: 1
timeoutSeconds: 2
name: etcd-master01
readinessProbe:
failureThreshold: 3
httpGet:
path: /metrics
port: 2379
scheme: HTTP
initialDelaySeconds: 10
periodSeconds: 2
successThreshold: 2
timeoutSeconds: 2
volumeMounts:
- mountPath: /etc/etcd/ #挂载的证书目录,需要和nginx配置中一样
name: etcd-ssl
readOnly: true
- mountPath: /usr/local/nginx/conf/nginx.conf #nginx配置目录,需要和镜像中nginx的一直。比如yum安装就是在/etc/nginx/nginx.conf中。
name: nginx
subPath: nginx.conf
imagePullSecrets:
- name: docker
volumes:
- configMap:
defaultMode: 256
name: etcd-ssl
optional: false
name: etcd-ssl
- configMap:
defaultMode: 256
name: nginx-etcd01
optional: false
name: nginxpod启动好以后等几分钟再打开grafana就会发现全部有数据了。
ingress配置
prometheus数据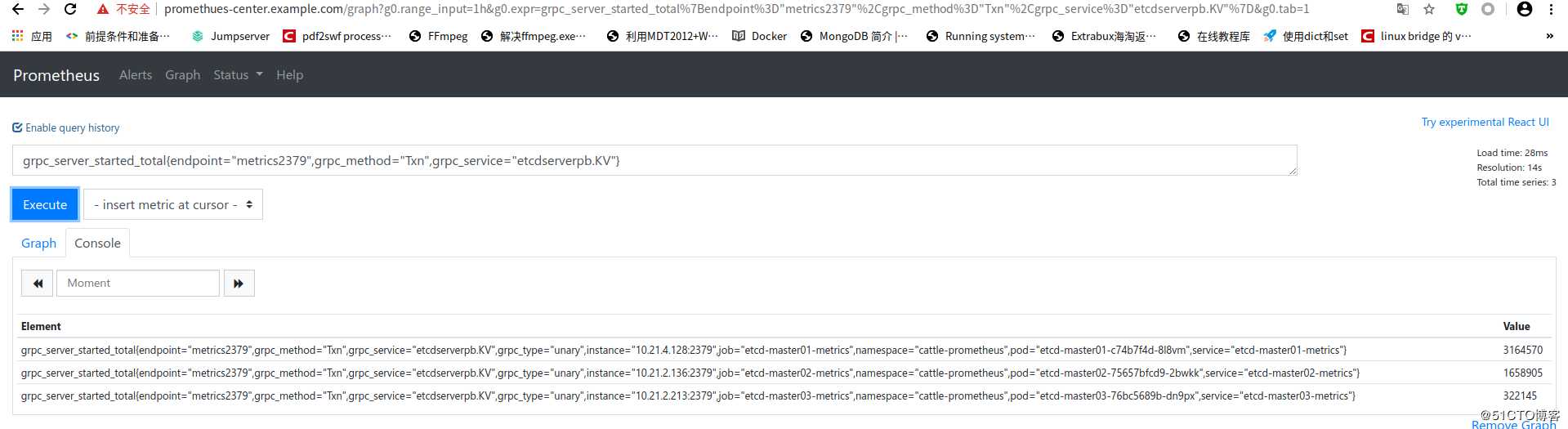
grafana展示: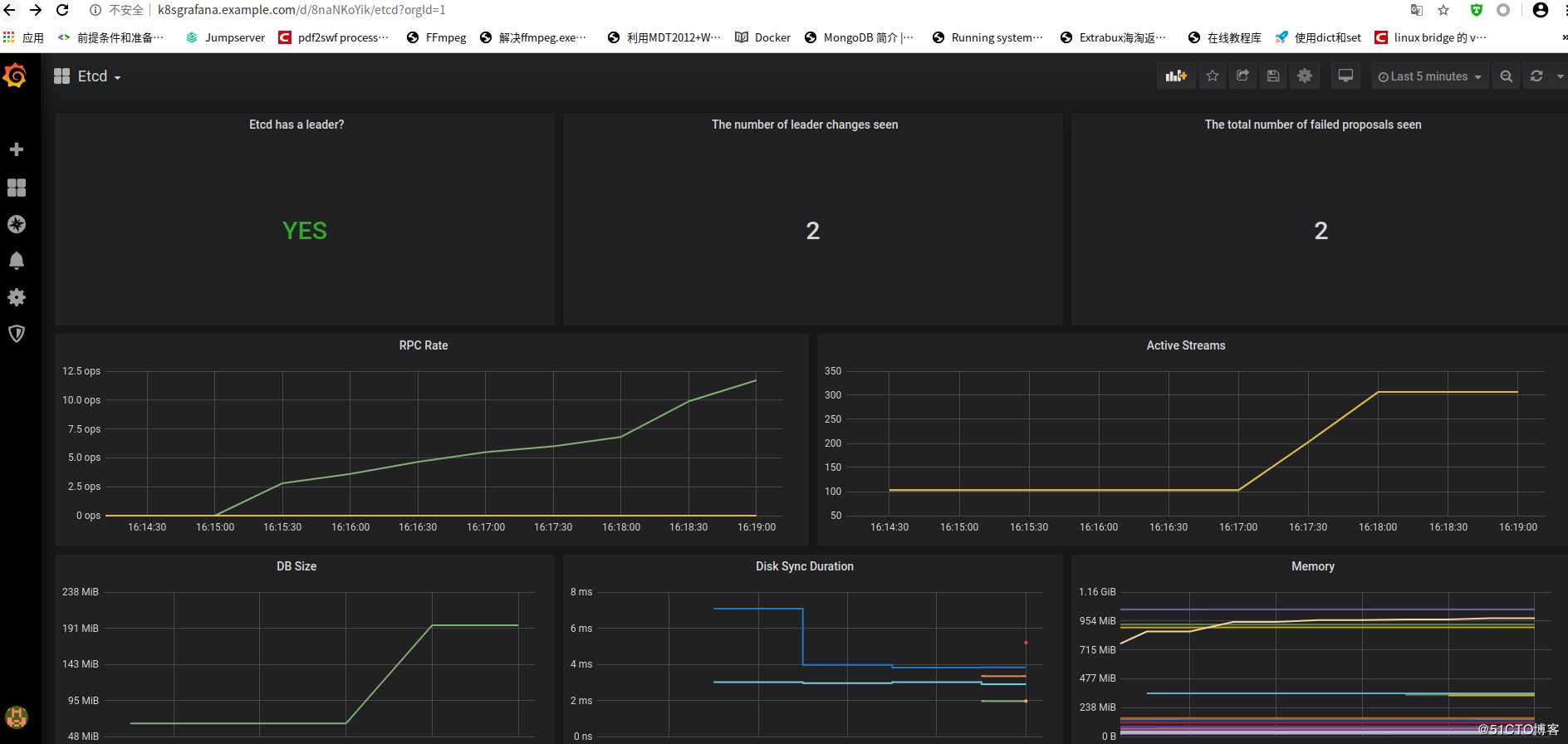
这里需要注意的是使用不同的nginx镜像,配置的目录可能会不一样。请注意配置文件的位置,修改成对应的目录。
以上是关于rancher2.4平台导入的k8s集群无法监控etcd解决办法的主要内容,如果未能解决你的问题,请参考以下文章
云原生之kubernetes实战在k8s集群下部署Weave Scope监控平台
(十九)从零开始搭建k8s集群——使用KubeSphere管理平台搭建一套微服务的压力测试性能监控平台(Grafana8.5.2+influxdb2.2.0+Jmeter5.4.1)
(十九)从零开始搭建k8s集群——使用KubeSphere管理平台搭建一套微服务的压力测试性能监控平台(Grafana8.5.2+influxdb2.2.0+Jmeter5.4.1)