系统学习NLP(三十二)--BERTXLNetRoBERTaALBERT及知识蒸馏
Posted Eason.wxd
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了系统学习NLP(三十二)--BERTXLNetRoBERTaALBERT及知识蒸馏相关的知识,希望对你有一定的参考价值。
参考:https://zhuanlan.zhihu.com/p/84559048
一.BERT
BERT是一种基于Transformer Encoder来构建的一种模型,它整个的架构其实是基于DAE(Denoising Autoencoder)的,这部分在BERT文章里叫作Masked Lanauge Model(MLM)。MLM并不是严格意义上的语言模型,因为整个训练过程并不是利用语言模型方式来训练的。BERT随机把一些单词通过MASK标签来代替,并接着去预测被MASK的这个单词,过程其实就是DAE的过程。BERT有两种主要训练好的模型,分别是BERT-Small和BERT-Large, 其中BERT-Large使用了12层的Encoder结构。 整个的模型具有非常多的参数。
BERT在2018年提出,当时引起了爆炸式的反应,因为从效果上来讲刷新了非常多的记录,之后基本上开启了这个领域的飞速的发展。
二.XLNet
BERT之后的一个爆发节点发生在XLNet发布的时候,因为它刷新了BERT保留的很多记录。除了效果之外,那为什么要提出XLNet呢?这就需要从BERT的缺点说起。
虽然BERT有很好的表现,但本身也有一些问题。总结起来有以下几点:
1.训练数据和测试数据之间的不一致性,这也叫作Discrephancy。当我们训练BERT的时候,会随机的Mask掉一些单词的,但实际上在使用的过程当中,我们却没有MASK这类的标签,所以这个问题就导致训练的过程和使用(测试)的过程其实不太一样,这是一个主要的问题。
2. 并不能用来生成数据。由于BERT本身是依赖于DAE的结构来训练的,所以不像那些基于语言模型训练出来的模型具备很好地生成能力。之前的方法比如NNLM[12],ELMo是基于语言模型生成的,所以用训练好的模型可以生成出一些句子、文本等。但基于这类生成模型的方法论本身也存在一些问题,因为理解一个单词在上下文里的意思的时候,语言模型只考虑了它的上文,而没有考虑下文!
基于这些BERT的缺点,学者们提出了XLNet, 而且也借鉴了语言模型,还有BERT的优缺点。最后设计出来的模型既可以很好地用来执行生成工作,也可以学习出上下文的向量表示。那如何做的呢?
首先,生成模型是单向的,即便我们使用Bidirectional LSTM类模型,其实本质是使用了两套单向的模型。那又如何去解决呢?答案是他们使用了permutation language model, 也就是把所有可能的permutation全部考虑进来。这个想法源自于hugo之前的工作叫作NADE,感兴趣的读者可以去看一下。
另外,为了迎合这种改变,他们在原来的Transformer Encoder架构上做了改进,这部分叫作Two-stream attention, 而且为了更好地处理较长的文本,进而使用的是Transformer-XL。 这就是XLNet的几大核心!关于Transformer-XL 看这里 https://zhuanlan.zhihu.com/p/70745925
核心:
Transformer编码固定长度的上下文,即将一个长的文本序列截断为几百个字符的固定长度片段(segment),然后分别编码每个片段[1],片段之间没有任何的信息交互。比如BERT,序列长度的极限一般在512。动机总结如下:
- Transformer无法建模超过固定长度的依赖关系,对长文本编码效果差。
- Transformer把要处理的文本分割成等长的片段,通常不考虑句子(语义)边界,导致上下文碎片化(context fragmentation)。通俗来讲,一个完整的句子在分割后,一半在前面的片段,一半在后面的片段。
文章围绕如何建模长距离依赖,提出Transformer-XL【XL是extra long的意思】:
- 提出片段级递归机制(segment-level recurrence mechanism),引入一个记忆(memory)模块(类似于cache或cell),循环用来建模片段之间的联系。
- 使得长距离依赖的建模成为可能;
- 使得片段之间产生交互,解决上下文碎片化问题。
- 提出相对位置编码机制(relative position embedding scheme),代替绝对位置编码。
- 在memory的循环计算过程中,避免时序混淆【见model部分】,位置编码可重用。
小结一下,片段级递归机制为了解决编码长距离依赖和上下文碎片化,相对位置编码机制为了实现片段级递归机制而提出,解决可能出现的时序混淆问题。
三.RoBERTa
RoBERTa 模型更多的是基于 BERT 的一种改进版本。是 BERT 在多个层面上的重大改进。
RoBERTa 在模型规模、算力和数据上,主要比 BERT 提升了以下几点:
-
更大的模型参数量(从 RoBERTa 论文提供的训练时间来看,模型使用 1024 块 V 100 GPU 训练了 1 天的时间)
-
更多的训练数据(包括:CC-NEWS 等在内的 160GB 纯文本)
此外如下所示,RoBERTa 还有很多训练方法上的改进。
1. 动态掩码
BERT 依赖随机掩码和预测 token。原版的 BERT 实现在数据预处理期间执行一次掩码,得到一个静态掩码。而 RoBERTa 使用了动态掩码:每次向模型输入一个序列时都会生成新的掩码模式。这样,在大量数据不断输入的过程中,模型会逐渐适应不同的掩码策略,学习不同的语言表征。
2. 更大批次
RoBERTa 在训练过程中使用了更大的批数量。研究人员尝试过从 256 到 8000 不等的批数量。
3. 文本编码
Byte-Pair Encoding(BPE)是字符级和词级别表征的混合,支持处理自然语言语料库中的众多常见词汇。
原版的 BERT 实现使用字符级别的 BPE 词汇,大小为 30K,是在利用启发式分词规则对输入进行预处理之后学得的。Facebook 研究者没有采用这种方式,而是考虑用更大的 byte 级别 BPE 词汇表来训练 BERT,这一词汇表包含 50K 的 subword 单元,且没有对输入作任何额外的预处理或分词。
四.ALBERT
ALBERT试图解决上述的问题: 1. 让模型的参数更少 2. 使用更少的内存 3. 提升模型的效果。注意:在速度上似乎没有那么明显。最大的问题就是这种方式其实并没有减少计算量,也就是受推理时间并没有减少,训练时间的减少也有待商榷
文章里提出一个有趣的现象:当我们让一个模型的参数变多的时候,一开始模型效果是提高的趋势,但一旦复杂到了一定的程度,接着再去增加参数反而会让效果降低,这个现象叫作“model degratation"。
基于上面所讲到的目的,ALBERT提出了三种优化策略,做到了比BERT模型小很多的模型,但效果反而超越了BERT, XLNet。
- Factorized Embedding Parameterization. 他们做的第一个改进是针对于Vocabulary Embedding。在BERT、XLNet中,词表的embedding size(E)和transformer层的hidden size(H)是等同的,所以E=H。但实际上词库的大小一般都很大,这就导致模型参数个数就会变得很大。为了解决这些问题他们提出了一个基于factorization的方法。
他们没有直接把one-hot映射到hidden layer, 而是先把one-hot映射到低维空间之后,再映射到hidden layer。这其实类似于做了矩阵的分解。
- Cross-layer parameter sharing. Zhenzhong博士提出每一层的layer可以共享参数,这样一来参数的个数不会以层数的增加而增加。所以最后得出来的模型相比BERT-large小18倍以上。
- Inter-sentence coherence loss. 在BERT的训练中提出了next sentence prediction loss, 也就是给定两个sentence segments, 然后让BERT去预测它俩之间的先后顺序,但在ALBERT文章里提出这种是有问题的,其实也说明这种训练方式用处不是很大。 所以他们做出了改进,他们使用的是setence-order prediction loss (SOP),其实是基于主题的关联去预测是否两个句子调换了顺序。
五、Distilling the Knowledge in a Neural Network
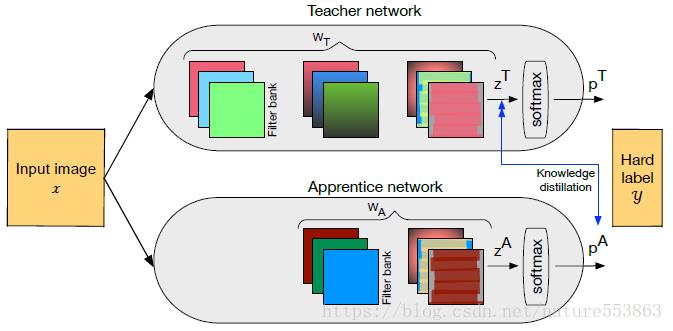
Hinton的文章"Distilling the Knowledge in a Neural Network"首次提出了知识蒸馏(暗知识提取)的概念,通过引入与教师网络(teacher network:复杂、但推理性能优越)相关的软目标(soft-target)作为total loss的一部分,以诱导学生网络(student network:精简、低复杂度)的训练,实现知识迁移(knowledge transfer)。

如上图所示,教师网络(左侧)的预测输出除以温度参数(Temperature)之后、再做softmax变换,可以获得软化的概率分布(软目标),数值介于0~1之间,取值分布较为缓和。Temperature数值越大,分布越缓和;而Temperature数值减小,容易放大错误分类的概率,引入不必要的噪声。针对较困难的分类或检测任务,Temperature通常取1,确保教师网络中正确预测的贡献。硬目标则是样本的真实标注,可以用one-hot矢量表示。total loss设计为软目标与硬目标所对应的交叉熵的加权平均(表示为KD loss与CE loss),其中软目标交叉熵的加权系数越大,表明迁移诱导越依赖教师网络的贡献,这对训练初期阶段是很有必要的,有助于让学生网络更轻松的鉴别简单样本,但训练后期需要适当减小软目标的比重,让真实标注帮助鉴别困难样本。另外,教师网络的推理性能通常要优于学生网络,而模型容量则无具体限制,且教师网络推理精度越高,越有利于学生网络的学习。
教师网络与学生网络也可以联合训练,此时教师网络的暗知识及学习方式都会影响学生网络的学习,具体如下(式中三项分别为教师网络softmax输出的交叉熵loss、学生网络softmax输出的交叉熵loss、以及教师网络数值输出与学生网络softmax输出的交叉熵loss):
联合训练的Paper地址:https://arxiv.org/abs/1711.05852
为了能够诱导训练更深、更纤细的学生网络(deeper and thinner FitNet),需要考虑教师网络中间层的Feature Maps(作为Hint),用来指导学生网络中相应的Guided layer。此时需要引入L2 loss指导训练过程,该loss计算为教师网络Hint layer与学生网络Guided layer输出Feature Maps之间的差别,若二者输出的Feature Maps形状不一致,Guided layer需要通过一个额外的回归层,具体如下:
具体训练过程分两个阶段完成:第一个阶段利用Hint-based loss诱导学生网络达到一个合适的初始化状态(只更新W_Guided与W_r);第二个阶段利用教师网络的soft label指导整个学生网络的训练(即知识蒸馏),且total loss中soft target相关部分所占比重逐渐降低,从而让学生网络能够全面辨别简单样本与困难样本(教师网络能够有效辨别简单样本,而困难样本则需要借助真实标注,即hard target)
比 Bert 体积更小速度更快的 TinyBERT
https://zhuanlan.zhihu.com/p/94359189
以上是关于系统学习NLP(三十二)--BERTXLNetRoBERTaALBERT及知识蒸馏的主要内容,如果未能解决你的问题,请参考以下文章