Python 如果两个字典key值相同,如何提取对应values组成新的字典
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python 如果两个字典key值相同,如何提取对应values组成新的字典相关的知识,希望对你有一定的参考价值。
图一和图二是两个字典,Key值存在相同的值,当两个字典的key值相同的时候,如何将dic1对应的values取出来作为新的字典values,dic2对应的values取出来作为新字典的key

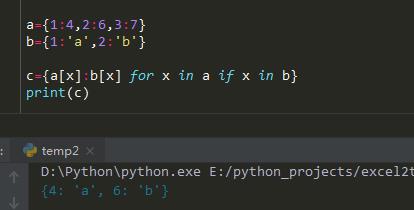
是这样吗?
参考技术A 按照你的要求编写的程序如下(见图) 参考技术B 按照你的要求编写的程序如下(见图) 参考技术C 按照你的要求编写的程序如下(见图)读取csv字典变成str了怎么办
读取csv字典变成str了怎么办:python中有一个读写csv文件的包,直接import csv即可。csv文件的性质:
值没有类型,所有值都是字符串
不能指定字体颜色等样式
不能指定单元格的宽高,不能合并单元格
没有多个工作表
不能嵌入图像图表
在CSV文件中,以,作为分隔符,分隔两个单元格。像这样a,,c表示单元格a和单元格c之间有个空白的单元格。依此类推。 参考技术A 在将一些数据从一个平台,换到另一个平台去处理时,使用了常用的csv文件去存储数据。
最开始时,直接将narry格式数据,用dic字典处理,暴力存储过程,产生了错误。
d = 'feature':test_fea, 'label':y_test
import pandas as pd
df = pd.DataFrame(d, index=[0])
df.to_csv('ayi.csv')
# test_fea.shape() (1084,10)
# y_test.shape (1084,)
上端代码会直接报错,按照错误指示,参考一些教程,将两个数据粗暴转换成单列表元素,代码修改如下,即可正常转换为csv文件。
d = 'feature':[test_fea], 'label':[y_test]
import pandas as pd
df = pd.DataFrame(d, index=[0])
df.to_csv('ayi.csv')
然而,用另一个平台读取该数据时,该dataframe仅有一个元素。
import pandas as pd
df = pd.read_csv('ayi.csv')
df.head()
fea = df.iloc[0,1]
此时的输出结果,是一个str格式,大致类似于‘[[1,2,3]\n[3,4,5].....[2,4,6]]'。
为了得到列表,考虑过用正特表达式的方法,有一篇博文也是这么用的。但是在我的环境下,代码比较繁琐。借助自己可以修改cdv的优势,重新生层一组csv文件并读取。
2.解决方法
关键在于对csv的生成和处理方法,将直接pd.DataFrame(dic),df.to_csv()换成以下方法。
with open('ayi.csv','w', newline='') as csvfile:
writer = csv.writer(csvfile)
for row in list(y_test):
writer.writerow(row)
写入之后的文件,打开就变得更人性化了。
随后正常读取:
label = pd.read_csv('ayi.csv')
label.head()
可以正常显示所有的数组数据,解决读取后是str的问题。
3. 总结
写入csv文件时候,按行写入每一个维度数据,可避免读取后数组变为str的尴尬。
文章知识点与官方知识档案匹配
Python入门技能树结构化数据分析工具PandasPandas概览
221089 人正在系统学习中 参考技术B 读取csv字典变成str了怎么办:做法是使用您想要的特定编码打开文件,因为默认编码因操作系统配置而异。这被称为“Unicode 三明治”。写入/读取文件时编码/解码,并且仅在 Python 脚本中使用 Unicode。
以上是关于Python 如果两个字典key值相同,如何提取对应values组成新的字典的主要内容,如果未能解决你的问题,请参考以下文章