mongodb多个collection及shard的问题
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了mongodb多个collection及shard的问题相关的知识,希望对你有一定的参考价值。
背景:
1、我理解的shard是对于一个collection而言
2、现有个一个mongodb cluster,多个分片
3、通过mongos往一个database中插入一个新的collection
疑问:
这个新插入的collection存在哪个分片上?是如何选择的?一个shard满了,是否会自动在另一个shard上插入?
最好能帮忙找到相关文章,谢谢!
collection其实就是关系型数据库中的table一样。通常说的“一张表”,在mongodb中就是一个collection.
而shard是集群中的概念。
mongodb集群分两种:一种是Replica set,即副本集,由多个mongod组成,mongod之间存在主副关系,数据是同一份;另一种就是你说的分片,分三个角色,mongos,configserver,以及mongod,configserver存储的是元数据,通常是三个保存同一份数据,mongod实例则可以是单台mongod,也可以是一个副本集。几个mongod共同组成一大份数据。
shard其实通常是指第二种中的mongod。
实际上由于mongodb中分片是以collection为单位,因此一个shard上可以保存不同的数据。
接下来回答你的问题:
1中的理解是错的,一个shard是指一个单台mongod,或者多台mongod组成的副本集
通常是一个服务器或者服务器集群
新插入的collection?这个说话有点不对。
在建立了一个collection后,通常是要给它分片或者不分片的。
如果不分片,所有的数据,都会保存在一个shard上。
如果分片,在数据量未达到chunksize的情况下,还是会在一个shard上,当一个chunk已经饱和,则会生成新的chunk,至于新的chunk在哪个shard上,则是随机的,通常是会选择chunk最小的shard。
至于我刚才提的chunk,这个才是分片中的数据迁移基本单位。
相关文章么,楼主可以自己搜一下,mongodb官方的就很不错,不过是全英文的。 参考技术A sharded cluster都有一个primary shard,没有sharded的collection都是只存在这个shard里的,所以你要建一个新的collection,在你使用sh.shardCollection()之前,它是只存在这个primary shard里面的。primary shard是你在设定这个cluster的时候第一个添加的shard,或者是你设定好cluster之后用movePrimary重新指定的shard。
如果你不对这个collection执行sh.shardCollection(),那它就不是sharded collection,所以也就不会往其他shard上面写。
这些mongodb的文档上都写了的,你在它网站上检索就行。追问
感谢你的回答,我就是在网上看到同一种数据有两种存放方案,一种是一个大的collecion分片;另一种是同样结构的多个collection,于是我就好奇,多个collection的话,那如何均分的把多个collection分配到不同机器上,请问你了解这块吗?有没有简单的方法均匀的分配许多小的collection?谢谢!
追答手动弄好几个collection在不同的mongodb里不就等于手动干mongos自动来干的事情么?应该没必要这么干吧。用mongodb自己的sharding还有一个好处就是它自动有一个balancer,把数据尽量平均的分配到每一个shard里面,而且是随时跟据情况调节的,比如balancer会自动把一些已经存在你的cluster里的数据从一个shard移动到另一个shard来保持平衡,你自己基本上什么都不用管。你看到的那个手动分成多个collection的方案有没有写他为什么要这么干?
追问没有,谢谢
本回答被提问者采纳MongoDB 数据分发
在MongoDB(版本 3.2.9)中,数据的分发是指将collection的数据拆分成块(chunk),分布到不同的分片(shard)上,数据分发主要有2种方式:基于数据块(chunk)数量的均衡分发和基于片键范围(range)的定向分发。MongoDB内置均衡器(balancer),用于拆分块和移动块,自动实现数据块在不同shard上的均匀分布。balancer只保证每个shard上的chunk数量大致相同,不保证每个shard上的doc数量大致相同。
一,数据按照chunk数量进行均衡分发
均衡分发是MongoDB自动实现的,使数据库架构对Application透明,简化系统的管理,使得向分片集群中增减分片变得容易。均衡分发是由MongoDB内置均衡器(balancer)来实现的,Balancer按照collection的索引字段来进行数据分发,该字段叫做片键(sharded key)。片键一般有三种类型:升序片键,随机片键和基于分组的片键。
块(chunk)是由多个doc组成的一个分组,在某个索引字段(片键)上是连续的,每个chunk的片键是有一定范围的。块的默认大小是64MB。有些chunk会非常大,包含的doc数量非常多,但是,在MongoDB看来,仍然是一个chunk,和没有任何doc的空chunk没有区别。均衡分发保证每个shard的chunk数量是大致相同的。因此,片键的选择直接影响分片的好坏。
例如:一个MongoDB分片集群有3个shard,分别是shard1,shar2,shard3。片键的最小值是:$MinKey,最大值是:$MaxKey。包含端值$MinKey的chunk是最小块,包含端值$MaxKey的chunk是最大块。
1,升序片键
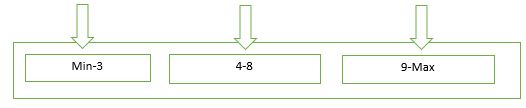
升序片键类似date字段或者_id字段,是一种随着时间稳定增长的字段。假如分片的字段是_id字段,集合foo中存在10个doc,每个shard中存在一个数据块,分别是:chunk1:$MinKey-3,chunk2:4-8,chunk3:9-$MaxKey。
使用升序片键的劣势是:每次插入一个新的doc,都会插入到最大块中,这会导致所有的写请求都会被路由到同一个分片,导致最大块不断增长,不断被拆分,然后不断被移动到其他分片中,导致数据的写入不均衡,块移动会额外增加Disk的写数量。使用升序片键的优势是:按照片键进行范围读时,性能高。

2,随机片键
随机片键是指片键的值不是固定增长,而是一些没有规律的键值。由于写入数据是随机分发的,各分片增长的速度大致相同,减少了chunk 迁移的次数。使用随机分片的弊端是:写入的位置是随机的,如果使用Hash Index来产生随机值,那么范围查询的速度会很慢。
3,基于分组的片键
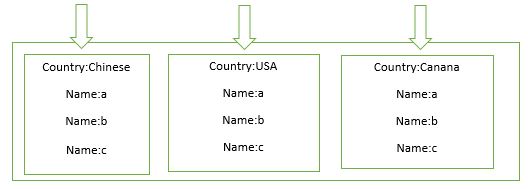
基于分组的片键是两字段的复合片键,第一个字段用于分组,该字段的势最好是比较低的,势是在同一字段中不同值(distinct value)的数量或所占的比例;第二个字段用于自增,该字段最好是自增字段。这种片键策略是最好的,能够实现多热点数据的读写。
单个mongod 在处理升序写请求时是最有效的,数据只需要写入到集合的末尾。基于分组的片键,将数量不多的分组分布在分片集群中,每个shard只有少量的chunk,这样能够将数据的写操作分布在分片集群中的每个shard上,在单个shard上,以升序方式读写数据。一个shard上的分组太多,写请求就相当于随机写了,反而不好。
二,按照片键范围进行定向分发
如果希望特定范围的chunk被分发到特定的分片中,可以为分片添加tag,然后为tag指定相应的片键范围,这样,如果一个doc属于tag的片键范围,就会被定向到特定的shard中。
1,为shard指定tag
sh.addShardTag("shar1","shard_tag1");
sh.addShardTag("shar2","shard_tag2");
sh.addShardTag("shar3","shard_tag2");
2,为tag指定片键范围

sh.addTagRange(
"db_name.collection_name",
{field:"min_value"},
{field:"max_value"},
"shard_tag"
)
每个shard的tag可以使用任意数量的tag,MongoDB的均衡器在移动块时,会将特定片键范围的chunk移动到特定的shard上。
三,手动进行数据的分发
MongoDB内置均衡器(balancer),自动实现数据块的拆分和移动,有时,可以关闭balancer,使用moveChunk命令手动移动数据块。
1,关闭balancer
连接到一个mongos,更新config.setting命名空间
use config
db.setting.update({"_id":"balancer"},{"enabled":false},true)
--or
sh.setBalancerState(false);
2,拆分块
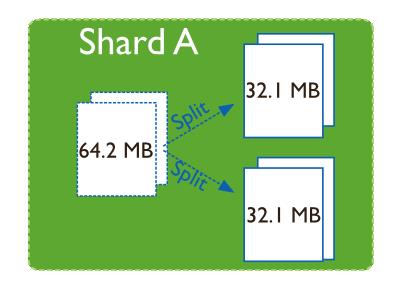
拆分块是指新增一个边界点,将一个chunk在边界点处拆分成两个chunk。在MongoDB中,将片键从小到大排序,边界值属于右边的chunk。
sh.splitAt("db_name.collection_name",{sharded_filed:"new_boundary_value"})
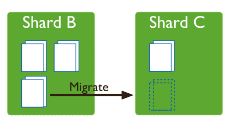
3,移动块
MongoDB将包含指定文档的chunk移动到指定的shard上,必须使用片键来查找所要一定的chunk。
sh.moveChunk("db_name.collection_name",{sharded_filed:"value_in_chunk"},"new_shard_name")
4,启用balancer
sh.setBalancerState(true)
5,刷新mongos的缓存
在Application layer 和数据存储之间,存在一个Query Router,即mongos,mongos会在第一次启动或分片的元数据被更新之后,从config server 同步配置数据,并缓存在mongos中。有时,mongos无法从config server上及时同步最新的配置信息,导致无法路由到相应的chunk,不能返回正确的数据,可以使用flushRouterConfig 命令手动刷新mongos的缓存
db.adminCommand({"flushRouterConfig":1})
参考文档:
以上是关于mongodb多个collection及shard的问题的主要内容,如果未能解决你的问题,请参考以下文章