windows10怎么接受虚拟机中的广播?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了windows10怎么接受虚拟机中的广播?相关的知识,希望对你有一定的参考价值。
参考技术A 是不是把vmnet1 禁止了?启用vmnet1即可。OneFlow源码解析:算子指令在虚拟机中的执行

撰文|郑建华、赵露阳
1
Op在虚拟机里的执行
1.1 PhysicalRun和InstructionsBuilder
上一篇文章《OneFlow源码解析:Op、Kernel与解释器》中提到:
PhysicalRun接受一个lambda函数作为参数,这里即InstructionsBuilder->Call方法,该方法接受kernel、input/output的eager blob object、kernel执行的上下文作为参数。Call方法实际会完成OpCall指令的构建,并最终将其派发至vm指令列表中,等待VM实际调度执行。
这个PhysicalRun函数里包裹着一个lambda函数:
JUST(PhysicalRun([&](InstructionsBuilder* builder) -> Maybe<void>
return builder->Call(xxx);
));其中,lambda函数接受一个InstructionsBuilder指针(builder),并调用builder->Call方法,用于实际完成Op指令在VM中的构建。而PhysicalRun(https://github.com/Oneflow-Inc/oneflow/blob/88f147d50e75d1644e552ed445dd58f9b5121ea5/oneflow/core/framework/instructions_builder.h#L160)在 oneflow/core/framework/instructions_builder.h中定义,其接受lambda函数作为模版参数(CallbackT):
// Make VM instructions with instruction builder and run instructions with physical/local view.
template<typename CallbackT>
Maybe<void> PhysicalRun(const CallbackT& Build)
vm::InstructionList instruction_list;
InstructionsBuilder instructions_builder(&instruction_list);
JUST(Build(&instructions_builder));
JUST(vm::Run(instructions_builder.mut_instruction_list()));
return Maybe<void>::Ok();
可见,PhysicalRun函数中,首先初始化一个InstructionsBuilder,然后将InstructionsBuilder指针作为参数传给lambda函数,完成实际指令的构建;最后通过vm::Run()方法将该指令发送至VM,等候VM实际调度和执行。Run方法如下:
Maybe<void> Run(vm::InstructionList* instruction_list)
auto* virtual_machine = JUST(SingletonMaybe<VirtualMachine>());
JUST(virtual_machine->Receive(instruction_list));
return Maybe<void>::Ok();
可以看见,Run()方法获取了全局单例的VM对象指针,然后通过vm的Receive()方法,将该条指令发送给虚拟机(所以这里Run其实有点歧义,更贴切的意思,其实是指令发送或传送)。
这个VirtualMachine->Receive方法很重要,会在后面的第2.章节中详细展开。
1.2 InstructionsBuilder
上面PhysicalRun函数中的InstructionsBuilder,类似一个指令构建的helper,InstructionsBuilder的系列方法配合指令策略(InstructionPolicy),可以帮助构建不同类型的vm指令。
从InstructionsBuilder
(https://github.com/Oneflow-Inc/oneflow/blob/88f147d50e75d1644e552ed445dd58f9b5121ea5/oneflow/core/framework/instructions_builder.h#L47)的定义中,我们可以看到指令的构建方法,其中常用方法如下:
// 用于lazy mode(nn.Graph)
// Build VM execution instructions with NNGraph's inputs/outputs/parameters for NNGraph execution.
Maybe<void> LaunchLazyJob(const vm::EagerBlobObjectListPtr& inputs,
const vm::EagerBlobObjectListPtr& outputs,
const vm::EagerBlobObjectListPtr& parameters,
const std::shared_ptr<NNGraphIf>& nn_graph);
// 用于全局同步,同步等待所有指令调用完成
Maybe<void> GlobalSync();
// 用于Tensor内存释放(归还allocator)
Maybe<void> ReleaseTensor(const std::shared_ptr<vm::EagerBlobObject>& eager_blob_object);
// 操作Tensor实际内存(blob)
template<typename T>
Maybe<void> AccessBlobByCallback(
const T tensor,
const std::function<void(ep::Stream*, const std::shared_ptr<vm::EagerBlobObject>&)>& callback,
const std::string& modifier);
// 最常用的指令构建方法,用于构造op执行所需的OpCall指令
Maybe<void> Call(const std::shared_ptr<one::StatefulOpKernel>& opkernel,
vm::EagerBlobObjectList&& input_eager_blob_objects,
vm::EagerBlobObjectList&& output_eager_blob_objects,
const one::OpExprInterpContext& ctx, Symbol<Stream> stream);1.3 InstructionPolicy
InstructionPolicy
(https://github.com/Oneflow-Inc/oneflow/blob/88f147d50e75d1644e552ed445dd58f9b5121ea5/oneflow/core/vm/instruction_policy.h#L34)——指令策略,通常用于配合InstructionsBuilder实际构建出不同的vm指令。InstructionPolicy的子类实现如下:

这些子类的InstructionPolicy可近似认为是指令类型。如,用于Op执行的OpCallInstructionPolicy、用于Tensor内存释放的ReleaseTensorInstructionPolicy、用于屏障阻塞的BarrierInstructionPolicy等。
以Op执行为例:
JUST(PhysicalRun([&](InstructionsBuilder* builder) -> Maybe<void>
return builder->Call(xxx);
));实际上是通过InstructionsBuilder的Call方法
(https://github.com/Oneflow-Inc/oneflow/blob/88f147d50e75d1644e552ed445dd58f9b5121ea5/oneflow/core/framework/instructions_builder.cpp#L355),配合OpCall的指令策略(OpCallInstructionPolicy),构造了OpCall指令:
Maybe<void> InstructionsBuilder::Call(
const std::shared_ptr<one::StatefulOpKernel>& opkernel,
vm::EagerBlobObjectList&& input_eager_blob_objects,
vm::EagerBlobObjectList&& output_eager_blob_objects,
const std::shared_ptr<const one::GlobalTensorInferResult>& global_tensor_infer_result,
const one::OpExprInterpContext& ctx, Symbol<Stream> stream)
...
...
// 获取当前vm stream
auto* vm_stream = JUST(Singleton<VirtualMachine>::Get()->GetVmStream(stream));
// 通过OpCallInstructionPolicy初始化OpCall指令
auto instruction = intrusive::make_shared<vm::Instruction>(
vm_stream, std::make_shared<vm::OpCallInstructionPolicy>(
vm_stream, opkernel, std::move(input_eager_blob_objects),
std::move(output_eager_blob_objects), global_tensor_infer_result, ctx,
*one::CurrentDevVmDepObjectConsumeMode()));
// 指令入列表
instruction_list_->EmplaceBack(std::move(instruction));
return Maybe<void>::Ok();
并将构建好的指令塞入指令列表,待后续VM调度并实际执行。
2
虚拟机的运行原理
2.1 VM初始化
OneFlow环境初始化时,会触发VirtualMachineScope
(https://github.com/Oneflow-Inc/oneflow/blob/88f147d50e75d1644e552ed445dd58f9b5121ea5/oneflow/core/vm/virtual_machine_scope.cpp#L24)的初始化:
VirtualMachineScope::VirtualMachineScope(const Resource& resource)
Singleton<VirtualMachine>::New();
进而触发VM对象——VirtualMachine
(https://github.com/Oneflow-Inc/oneflow/blob/88f147d50e75d1644e552ed445dd58f9b5121ea5/oneflow/core/vm/virtual_machine.cpp#L81)的初始化。VM作为一个Singleton对象,全局唯一。
VirtualMachine::VirtualMachine() : disable_vm_threads_(false), scheduler_stopped_(false)
// Class VirtualMachineEngine only cares the basic logical of vm, while class VirtualMachine
// manages threads and condition variables.
// In order to notify threads in VirtualMachineEngine, a notify callback lambda should be take as
// an argument for VirtualMachineEngine's constructor.
engine_ = intrusive::make_shared<vm::VirtualMachineEngine>();
OF_PROFILER_NAME_THIS_HOST_THREAD("_Main");
std::function<void()> SchedulerInitializer;
GetSchedulerThreadInitializer(&SchedulerInitializer);
schedule_thread_ = std::thread(&VirtualMachine::ScheduleLoop, this, SchedulerInitializer);
transport_local_dep_object_.Reset();
VM初始化中最重要的内容,便是:
1.初始化了一个VM的执行引擎——VirtualMachineEngine
2.通过VirtualMachine::ScheduleLoop启动了VM的调度线程
VirtualMachine::ScheduleLoop
VM对象只负责条件变量和线程管理;而主要业务逻辑处理(包括指令构建、调度、派发和执行等),则由VirtualMachineEngine
(https://github.com/Oneflow-Inc/oneflow/blob/88f147d50e75d1644e552ed445dd58f9b5121ea5/oneflow/core/vm/virtual_machine_engine.h#L47)对象负责;VM初始化时还开辟了单独的schedule线程用于VM引擎处理调度逻辑,在VirtualMachine::ScheduleLoop
(https://github.com/Oneflow-Inc/oneflow/blob/88f147d50e75d1644e552ed445dd58f9b5121ea5/oneflow/core/vm/virtual_machine.cpp#L292)中:
void VirtualMachine::ScheduleLoop(const std::function<void()>& Initializer)
SyncVmModeGuard guard(SyncVmMode::kEnable);
Initializer();
MultiThreadScheduleCtx schedule_ctx;
while (pending_notifier_.WaitAndClearNotifiedCnt() == kNotifierStatusSuccess)
OF_PROFILER_RANGE_GUARD("VirtualMachine::ScheduleLoop");
auto start = std::chrono::steady_clock::now();
static constexpr int kWorkingMicroseconds = 1000;
// Every time this thread wakes up, engine_ is scheduled for about `kWorkingMicroseconds`.
// The cost of os thread switching is about 5-10 microseconds. Doing more scheduling in
// a single waiting up can reach higher performance.
do
do
const size_t total_inserted = engine_->total_inserted_instruction_cnt();
const size_t total_erased = engine_->total_erased_instruction_cnt();
engine_->Schedule(schedule_ctx);
if (ThreadLocalEnvBool<ONEFLOW_VM_ENABLE_SCHEDULE_YIELD>()
&& total_inserted == engine_->total_inserted_instruction_cnt()
&& total_erased == engine_->total_erased_instruction_cnt()) // nothing handled.
std::this_thread::yield();
while (!engine_->SchedulerThreadUnsafeEmpty());
while (MicrosecondsFrom(start) < kWorkingMicroseconds);
ScheduleUntilVMEmpty(engine_.Mutable(), schedule_ctx);
CHECK_JUST(ForEachThreadCtx(engine_.Mutable(), [&](vm::ThreadCtx* thread_ctx) -> Maybe<void>
thread_ctx->mut_notifier()->Close();
return Maybe<void>::Ok();
));
std::unique_lock<std::mutex> lock(worker_threads_mutex_);
for (const auto& worker_thread : worker_threads_) worker_thread->join();
scheduler_stopped_ = true;
ScheduleLoop是一个近似于busy loop的while循环,pending_notifier_是VM内部维护的成员,实际上是ScheduleLoop线程的通知/唤醒者,其定义位于oneflow/oneflow/core/common/notifier.h:
class Notifier final
public:
OF_DISALLOW_COPY_AND_MOVE(Notifier);
Notifier() : notified_cnt_(0), is_closed_(false)
~Notifier() = default;
NotifierStatus Notify();
NotifierStatus WaitAndClearNotifiedCnt();
void Close();
private:
size_t notified_cnt_;
std::mutex mutex_;
bool is_closed_;
std::condition_variable cond_;
;其主要维护了互斥锁mutex_、线程是否关闭的flag is_closed_、条件变量cond_。忽略线程唤醒、超时相关逻辑,ScheduleLoop中最重要的事情是engine_->Schedule(schedule_ctx);
while (pending_notifier_.WaitAndClearNotifiedCnt() == kNotifierStatusSuccess)
auto start = std::chrono::steady_clock::now();
...
do
do
...
engine_->Schedule(schedule_ctx);
...
while (!engine_->SchedulerThreadUnsafeEmpty());
while (MicrosecondsFrom(start) < kWorkingMicroseconds);
当VM维护的指令队列不为空时,便不断唤醒VM引擎执行指令调度逻辑——engine->Schedule()
2.2 VM指令调度
void VirtualMachineEngine::Schedule(const ScheduleCtx& schedule_ctx)
// Release finished instructions and try to schedule out instructions in DAG onto ready list.
if (unlikely(mut_active_stream_list()->size())) ReleaseFinishedInstructions(schedule_ctx);
// Try run the first barrier instruction.
if (unlikely(mut_barrier_instruction_list()->size())) TryRunBarrierInstruction(schedule_ctx);
// Handle pending instructions, and try schedule them to ready list.
// Use thread_unsafe_size to avoid acquiring mutex lock.
// The inconsistency between pending_instruction_list.list_head_.list_head_.container_ and
// pending_instruction_list.list_head_.list_head_.size_ is not a fatal error because
// VirtualMachineEngine::Schedule is always in a buzy loop. All instructions will get handled
// eventually.
// VirtualMachineEngine::Receive may be less effiencient if the thread safe version
// `pending_instruction_list().size()` used here, because VirtualMachineEngine::Schedule is more
// likely to get the mutex lock.
if (unlikely(local_pending_instruction_list().size()))
HandleLocalPending();
else if (unlikely(pending_instruction_list().thread_unsafe_size()))
// MoveTo is under a lock.
mut_pending_instruction_list()->MoveTo(mut_local_pending_instruction_list());
if (local_pending_instruction_list().size()) HandleLocalPending();
// dispatch ready instructions and try to schedule out instructions in DAG onto ready list.
if (unlikely(mut_ready_instruction_list()->size()))
DispatchAndPrescheduleInstructions(schedule_ctx);
// handle scheduler probes
if (unlikely(local_probe_list_.size()))
HandleLocalProbe();
else if (unlikely(probe_list_.thread_unsafe_size()))
probe_list_.MoveTo(&local_probe_list_);
if (local_probe_list_.size()) HandleLocalProbe();
VM引擎维护了一系列指令列表的成员:
InstructionMutexedList pending_instruction_list_;
// local_pending_instruction_list_ should be consider as the cache of pending_instruction_list_.
InstructionList local_pending_instruction_list_;
ReadyInstructionList ready_instruction_list_;
LivelyInstructionList lively_instruction_list_;
BarrierInstructionList barrier_instruction_list_;-
pending相关的instruction_list是悬挂/待处理的指令列表;
-
lively相关的instruction_list是活跃的正在执行中的指令列表;
-
ready相关的instruction_list则是已完成准备工作(指令融合、指令DAG构建等)待执行的指令列表;
VM引擎Schedule时,会对指令队列做相应处理,包括:
-
将已完成准备工作的指令放入ready_instruction_list_中维护;
-
尝试运行barrier指令列表(barrier_instruction_list_)中的第一条指令;
-
如果本地pending指令列表(local_pending_instruction_list_)非空,则通过HandleLocalPending方法处理这些悬挂指令(指令融合、指令执行DAG图构建、插入ready列表)
-
如果ready指令列表非空,则通过DispatchAndPrescheduleInstructions方法进行指令派发和预调度处理。
这里重点介绍指令派发相关的DispatchAndPrescheduleInstructions方法,其中DispatchAndPrescheduleInstructions中最主要的是就是DispatchInstruction指令派发方法,这里的指令派发可以认为实际上就是指令执行。
2.3 VM指令派发
VirtualMachineEngine::DispatchInstruction
(https://github.com/Oneflow-Inc/oneflow/blob/88f147d50e75d1644e552ed445dd58f9b5121ea5/oneflow/core/vm/virtual_machine_engine.cpp#L372)方法是vm引擎中的核心,其实际完成了指令的派发和实际执行,代码如下:
template<void (VirtualMachineEngine::*OOMHandler)(vm::Stream*, const ScheduleCtx&)>
void VirtualMachineEngine::DispatchInstruction(Instruction* instruction,
const ScheduleCtx& schedule_ctx)
auto* stream = instruction->mut_stream();
// Prepare
// 指令的Prepare
const auto& ret = TRY(instruction->Prepare());
if (unlikely(!ret.IsOk()))
// 处理指令Prepare过程中的OOM的逻辑
if (ret.error()->has_out_of_memory_error())
// 让allocator释放不必要的cacahe,再重新执行指令的Prepare
(this->*OOMHandler)(stream, schedule_ctx);
...
// 将当前指令放入running_instruction_list
stream->mut_running_instruction_list()->PushBack(instruction);
if (stream->active_stream_hook().empty()) mut_active_stream_list()->PushBack(stream);
// Compute
if (OnSchedulerThread(*stream))
// StreamPolicy的Run方法触发指令的实际执行——Compute
stream->stream_policy().Run(instruction);
else
stream->mut_thread_ctx()->mut_worker_pending_instruction_list()->PushBack(instruction);
schedule_ctx.OnWorkerLoadPending(stream->mut_thread_ctx());
DispatchInstruction的核心主要有2块:
-
执行指令的Prepare
-
执行指令的Compute
Prepare负责一些指令执行前的准备;Compute则是实际的指令执行,指令执行并不是直接通过instruction->Run而是在StreamPolicy的Run方法中完成的,这里又涉及到一个StreamPolicy对象。
StreamPolicy::Run
StreamPolicy
(https://github.com/Oneflow-Inc/oneflow/blob/88f147d50e75d1644e552ed445dd58f9b5121ea5/oneflow/core/vm/stream_policy.h#L46)是个虚基类:
class StreamPolicy
public:
virtual ~StreamPolicy() = default;
virtual ep::Stream* stream() = 0;
virtual vm::Allocator* mut_allocator() = 0;
virtual DeviceType device_type() const = 0;
virtual void InitInstructionStatus(const Stream& stream,
InstructionStatusBuffer* status_buffer) const = 0;
virtual void DeleteInstructionStatus(const Stream& stream,
InstructionStatusBuffer* status_buffer) const = 0;
virtual bool QueryInstructionStatusDone(const Stream& stream,
const InstructionStatusBuffer& status_buffer) const = 0;
virtual void Run(Instruction* instruction) const = 0;
virtual bool OnSchedulerThread(StreamType stream_type) const;
virtual bool SupportingTransportInstructions() const = 0;
protected:
StreamPolicy() = default;
;-
stream()方法返回ep::Stream指针,指向的是针对不同平台的ep::stream对象。
-
mut_allocator()方法返回一个vm的Allocator指针,用于内存分配/释放。
-
InitInstructionStatus/QueryInstructionStatusDone/DeleteInstructionStatus用于创建/查询/销毁指令执行状态
-
Run方法则是核心,定义了该Stream具体运行时的逻辑。
这里的ep在oneflow中是execution provider的缩写,ep从本质上来讲就是一个针对不同硬件平台的executor抽象。
StreamPolicy相关的继承和子类如下:

看一下EpStreamPolicyBase的Run方法(https://github.com/Oneflow-Inc/oneflow/blob/88f147d50e75d1644e552ed445dd58f9b5121ea5/oneflow/core/vm/ep_stream_policy_base.cpp#L41):
void EpStreamPolicyBase::Run(Instruction* instruction) const
...
auto* stream = instruction->mut_stream();
EpStreamPolicyBase* ep_stream_policy_base =
dynamic_cast<EpStreamPolicyBase*>(stream->mut_stream_policy());
...
auto* ep_device = ep_stream_policy_base->GetOrCreateEpDevice();
ep_device->SetAsActiveDevice();
instruction->Compute();
...
首先获取了该stream对应的ep device,然后执行了instruction的Compute方法,即指令的实际执行。
2.4 VM执行执行
以OpCall指令为例,看一下op指令的Compute
(https://github.com/Oneflow-Inc/oneflow/blob/88f147d50e75d1644e552ed445dd58f9b5121ea5/oneflow/core/vm/op_call_instruction_policy.cpp#L201):
void OpCallInstructionPolicy::Compute(vm::Instruction* instruction)
OpCallInstructionUtil::Compute(this, instruction);
OpCallInstructionPolicy方法调用了OpCallInstructionUtil的Compute方法:
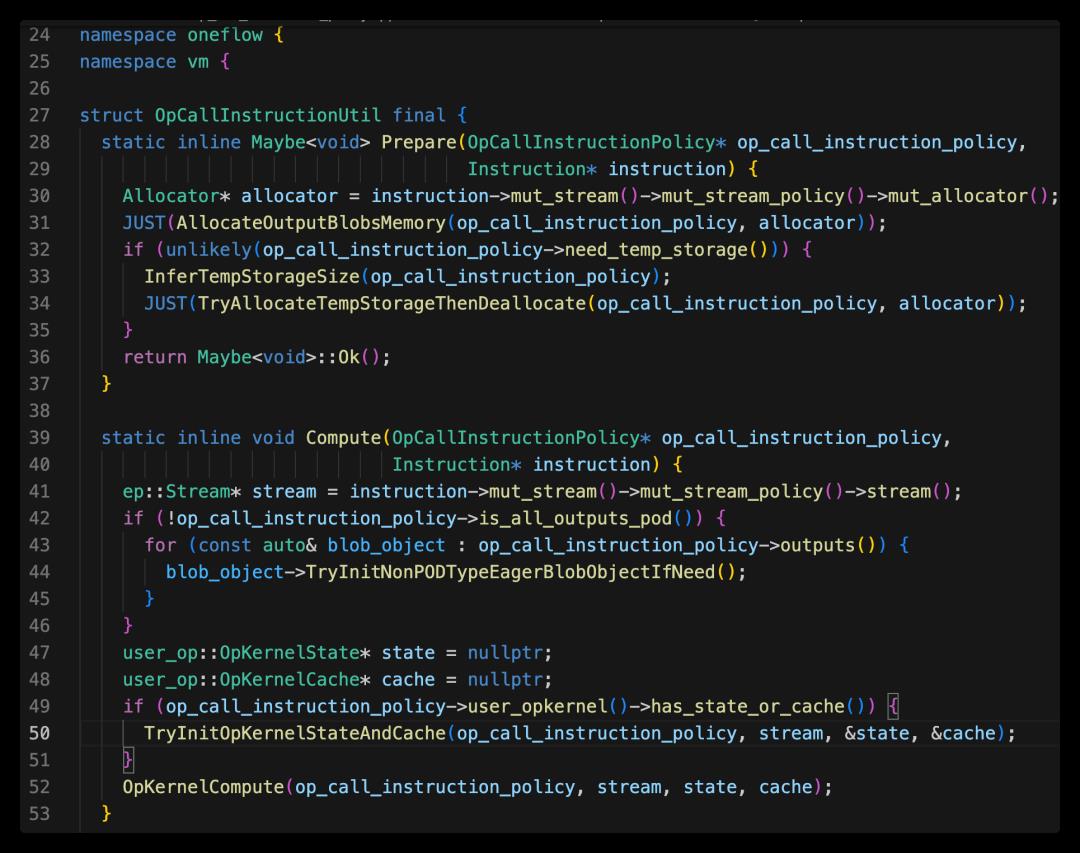
上面我们可以看到,在指令Prepare时,做了output tensor内存分配;而指令Compute中最重要的方法是:
-
TryInitOpKernelStateAndCache——初始化一些kernel计算需要的状态或缓存
-
OpKernelCompute——执行该op对应的kernel,kernel内主要是实际的op计算逻辑
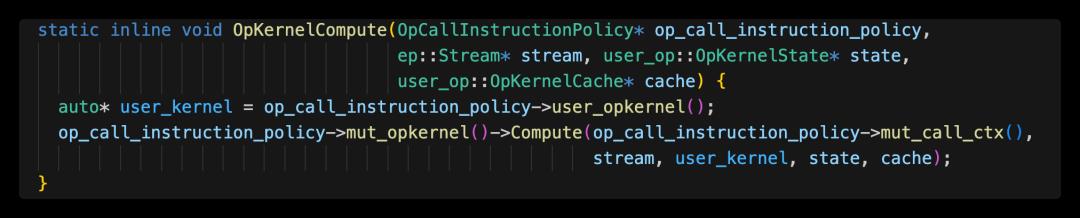
user kernel统一位于:oneflow/user/kernels目录下,.cpp通常对应cpu kernel逻辑;.cu为cuda kernel逻辑。到这里,就会触发user_kernel的Compute方法,不同op的kernel计算逻辑不同,以rele op为例,实际Compute过程可参考文章《算子在深度学习框架中的执行及interpreter》的第5小节。
2.5 VM指令发送
这里的VM指令发送,指的是VM外部的指令发送过程(不是VM内部的指令派发)。上面2.1~2.3小节介绍了VM以及VM引擎的初始化、VM内部指令的调度、派发和实际执行的过程,那么这些指令是如何发送到VM的呢?答案是:在1.1小节中提到的PhysicalRun
PhysicalRun最终会触发VirtualMachine->Receive方法,并通过VirtualMachineEngine的Receive方法完成外部指令 -> VM内部的发送。
VirtualMachineEngine的Receive方法(https://github.com/Oneflow-Inc/oneflow/blob/88f147d50e75d1644e552ed445dd58f9b5121ea5/oneflow/core/vm/virtual_machine_engine.cpp#L400)主要将该指令通过MoveFrom方法push back到指令悬挂列表(pending_instruction_list_)的末尾,从而完成指令的发送。
// Returns true if old scheduler_pending_instruction_list is empty
Maybe<bool> VirtualMachineEngine::Receive(InstructionList* compute_instruction_list)
OF_PROFILER_RANGE_GUARD("vm:Receive");
#ifdef OF_ENABLE_PROFILER
INTRUSIVE_UNSAFE_FOR_EACH_PTR(compute_instruction, compute_instruction_list)
OF_PROFILER_RANGE_GUARD(compute_instruction->DebugName());
#endif
bool old_list_empty = mut_pending_instruction_list()->MoveFrom(compute_instruction_list);
return old_list_empty;
3
小结
至此,Op执行相关的流程算是大体串了一遍。一句flow.relu()后面会涉及这么多内容。但这里其实也只关注了主干逻辑,忽略了中间大量的细节。
流程的梳理只是第一步,还需要从中归纳总结一些概念和概念之间的关系,再结合公开资料反推印证设计理念的落地实现。
不过目前对代码和设计的了解还很肤浅,下面的内容纯属大胆猜测。
3.1 UserOpExpr
UserOpExpr表示UserOp执行时所需的上下文,其实UserOp只是Op中的一种。下图展示了不同Op的继承关系。可以看到tensor从local/global之间的转换等也都涉及不同的OpExpr。
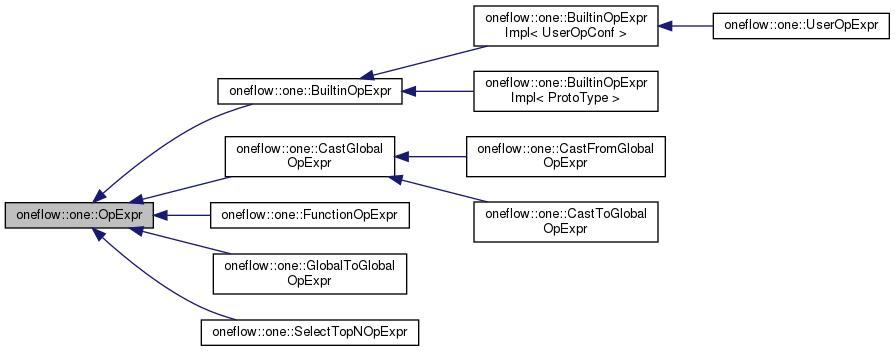
3.2 Op执行的宏观脉络
从上面的类关系图出发,以核心类为节点,也能看出Op执行流程的宏观脉络。整个流程大体在下面这些角色之间流转:
-
ReluFunctor
-
UserOpExpr
-
Interpreter
-
PhysicalRun
-
VirtualMachine->Receive
-
VirtualMachine->ScheduleLoop ...
3.3 虚拟机运行和调度总结
VM -> ScheduleLoop
VM引擎Schedule
处理悬挂指令(HandleLocalPending)
指令派发(DispatchInstruction)
准备(instruction->Prepare)
执行(StreamPolicy.Run -> instruction->Compute)
指令预调度
VM -> Receive
VM引擎 -> Receive
指令入悬挂列表
通常,我们习惯在动态图模式下训练深度学习网络,使用Python搭建网络,并通过各种op进行前向、反向、loss计算、调试debug等过程,这些Python代码可以看作是动态的op的执行序列。
OneFlow虚拟机将op执行序列抽象成了各种VM指令序列。OneFlow的虚拟机会对这些op执行序列进行动态翻译并生成VM指令序列,通过PhysicalRun构造完毕后,动态地将指令发送至VM的悬挂列表中维护。这些指令或在时间上存在先后顺序,或在数据上存在依赖关系,所以悬挂列表中的指令后续会被虚拟机进行一些指令融合、指令连边、动态构建指令DAG图的过程,然后移入就绪列表中维护,等待虚拟机调度并实际执行。虚拟机负责维护若干个指令队列,以及指令在这些队列之间的状态转换。
OneFlow虚拟机还统一了动态图模式(Eager Mode)和静态图模式(Lazy Mode)。静态图模式下,通过nn.Graph编译出深度学习网络的Job,这个Job同样被虚拟机抽象成了VM指令并接受虚拟机的调度和执行。大胆猜测一下,这也为日后动静转换、更极致的性能优化埋下了伏笔。
参考资料
-
OneFlow源码:
https://github.com/Oneflow-Inc/oneflow/tree/88f147d50e75d1644e552ed445dd58f9b5121ea5
其他人都在看
 https://github.com/Oneflow-Inc/oneflow/
https://github.com/Oneflow-Inc/oneflow/
以上是关于windows10怎么接受虚拟机中的广播?的主要内容,如果未能解决你的问题,请参考以下文章