Linux磁盘I/O子系统
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Linux磁盘I/O子系统相关的知识,希望对你有一定的参考价值。
参考技术A 上文学到 不管什么文件系统类型,都通过VFS(虚拟文件系统层)读和写等操作文件,写文件的元数据和文件的实际数据到磁盘 。但数据是怎么落地磁盘中的呢?落到磁盘中的都经过什么组件?以一个写数据到磁盘为例,给出Linux I/O子系统的体系结构。
当磁盘执行写入操作时发生的 基本操作 (假设磁盘上扇区中的文件数据已经被读取到分页缓存)。
1) 一个进程通过write()系统调用 VFS虚拟文件系统 请求写一个文件。
2) 内核更新已映射文件的分页缓存。
3) 内核线程 pdflush/Per-BDI flush将分页缓存刷新到磁盘。
4) 同时 VFS虚拟文件系统层 在一个bio(block input output)结构中放置每个块缓冲,并向块设备层提交写请求。
5) 块设备层 从上层得到请求,并执行一个 I/O电梯操作,将请求放置到I/O 请求队列。
6) 设备驱动器 (比如SCSI 或 其他设备特定的驱动器)将执行写操作。
7) 磁盘设备 固件执行硬件操作,如在盘片扇区上定位磁头,旋转,数据传输。
过去的20年中,处理器性能的改进要超过计算机系统中的其他组件,如处理器缓存、物理内存及磁盘等等。 访问内存和磁盘的速度较慢会限制整个系统的性能 ,怎么解决这个问题呢?引入 磁盘缓存机制 ,在较快的存储器中缓存频繁使用的数据,减少了访问较慢的存储器的次数。
磁盘缓存机制有以下3个地方解决:
引入存储层次结构 ,在CPU和磁盘之间放置L1缓存、L2缓存、物理内存和一些其他缓存减少这种不匹配,从而让进程减少访问较慢的内存和磁盘的次数,避免CPU花费更多的时间等待来自较慢磁盘驱动器的数据。
另外一种解决思路: 在更快的存储器上实现更高的缓存命中率,就可能更快地访问数据 。怎么提高缓存命中率呢?引入 参考局部性(locality of reference) 的技术。这项技术基于以下2个原则:
1) 大多数最近使用过的数据,在不久的将来有较高的几率被再次使用(时间局部性)。
2) 驻留在数据附近的数据有较高的几率被再次使用(空间局部性)。
Linux在许多组件中使用这些原则,比如分页缓存、文件对象缓存(索引节点缓存、目录条目缓存等等)、预读缓冲等。
以进程从磁盘读取数据并将数据复制到内存的过程为例。进程可以从缓存在内存中的数据副本中检索相同的数据,用于读和写。
1) 进程写入新数据
当一个进程试图改变数据时,进程首先在内存中改变数据。此时磁盘上的数据和内存中的数据是不相同的,并且内存中的数据被称为 脏页(dirty page) 。脏页中的数据应该尽快被同步到磁盘上,因为如果系统突然发生崩溃(电源故障)则内存中的数据会丢失。
2) 将内存中的数据刷新到磁盘
同步脏数据缓冲的过程被称为 刷新 。在Linux 2.6.32内核之前(Red Hat Enterprise Linux 5),通过内核线程pdflush将脏页数据刷新到磁盘。在Linux 2.6.32内核中(Red Hat Enterprise Linux 6.x)pdflush被Per-BDI flush线程(BDI=Backing Device Interface)取代,Per-BDI flush线程以flush-MAJOR:MINOR的形式出现在进程列表中。当内存中脏页比例超过阀值时,就会发生刷新(flush)。
块层处理所有与块设备操作相关的活动。块层中的关键数据结构是bio(block input output)结构,bio结构是在虚拟文件系统层和块层之间的一个接口。
当执行写的时候,虚拟文件系统层试图写入由块缓冲区构成的页缓存,将连续的块放置在一起构成bio结构,然后将其发送到块层。
块层处理bio请求,并链接这些请求进入一个被称为I/O请求的队列。这个链接的操作被称为 I/O电梯调度(I/O elevator)。问个问题:为啥叫电梯调度呢?
Linux 2.4内核使用的是一种单一的通用I/O电梯调度方法,2.6内核提供4种电梯调度算法供用户自己选择。因为Linux操作系统适用的场合很广泛,所以I/O设备和工作负载特性都会有明显的变化。
1)CFQ(Complete Fair Queuing,完全公平队列)
CFQ电梯调度为每个进程维护一个I/O队列,从而 对进程实现一个QoS(服务质量)策略 。CFQ电梯调度能够很好地适应存在很多竞争进程的大型多用户系统。它积极地避免进程饿死并具有低延迟特征。从2.6.18内核发行版开始,CFQ电梯调度成为默认I/O调度器。
CFQ为每个进程/线程单独创建一个队列来管理产生的请求,各队列之间用时间片来调度,以保证每个进程都能分配到合适的I/O带宽。I/O调度器每次执行一个进程的4个请求。
2)Deadline
Deadline是一种循环的电梯调度(round robin)方法,Deadline 算法实现了一个近似于实时的I/O子系统。在保持良好的磁盘吞吐量的同时,Deadline电梯调度既提供了出色的块设备扇区的顺序访问,又确保一个进程不会在队列中等待太久导致饿死。
Deadline调度器为了兼顾这两个方面,引入了4个队列,这4个队列可分为两类,每一类都由读和写两种队列组成。一类队列用来对 请求 按 起始扇区序号 进行排序(通过红黑树来组织),称为sort_list;另一类对 请求 按 生成时间进行排序 (由链表来组织),称为fifo_list。每当确定了一个传输方向(读或写),系统都将会从相应的sort_list中将一批连续请求调度到请求队列里,具体的数目由fifo_batch来确定。 只有遇到三种情况才会导致一次批量传输的结束 :1.对应的sort_list中已经没有请求了;2.下一个请求的扇区不满足递增的要求;3.上一个请求已经是批量传输的最后一个请求了。
所有的请求在生成时都会被赋上一个期限值,并且按期限值将它们排序在fifo_list中, 读请求的期限时长默认为500ms,写请求的期限时长默认为5s。 在Deadline调度器定义了一个writes_starved默认值为2,写请求的饥饿线。 内核总是优先处理读请求,当饿死进程的次数超过了writes_starved后,才会去考虑写请求 。 为什么内核会偏袒读请求呢? 这是从整体性能上进行考虑的。读请求和应用程序的关系是同步的,因为应用程序要等待读取完毕,方能进行下一步工作所以读请求会阻塞进程,而写请求则不一样。应用程序发出写请求后,内存的内容何时被写入块设备对程序的影响并不大,所以调度器会优先处理读请求。
3) NOOP
一个简单的FIFO 队列,不执行任何数据排序。NOOP 算法简单地合并相邻的数据请求,所以增加了少量的到磁盘I/O的处理器开销。NOOP电梯调度假设一个块设备拥有它自己的电梯算法。当后台存储设备能重新排序和合并请求,并能更好地了解真实的磁盘布局时,通常选择NOOP调度,
4)Anticipatory
Anticipatory本质上与Deadline一样,但Anticipatory电梯调度在处理最后一个请求之后会等待一段很短的时间,约6ms(可调整antic_expire改变该值),如果在此期间产生了新的I/O请求,它会在每个6ms中插入新的I/O操作,这样可以将一些小的I/O请求合并成一个大的I/O请求,从而用I/O延时换取最大的I/O吞吐量。
Linux内核使用设备驱动程序得到设备的控制权。 设备驱动程序 通常是一个独立的内核模块,通常针对每个设备(或是设备组)而提供,以便这些设备在Linux操作系统上可用。一旦加载了设备驱动程序,将被当作Linux内核的一部分运行,并能控制设备的运行。
SCSI (Small Computer System Interface,小型计算机系统接口)是最常使用的I/O设备技术,尤其在企业级服务器环境中。SCSI在 Linux 内核中实现,可通过设备驱动模块来控制SCSI设备。 SCSI包括以下模块类型 :
1) Upper IeveI drivers(上层驱动程序)。 sd_mod、sr_mod(SCSI-CDROM)、st(SCSI Tape)和sq(SCSI通用设备)等。
2) MiddIe IeveI driver(中层驱动程序) 。如scsi_mod实现了 SCSI 协议和通用SCSI功能。
3) Low IeveI drivers(底层驱动程序) 。提供对每个设备的较低级别访问。底层驱动程序基本上是特定于某一个硬件设备的,可提供给某个设备。
4) Pseudo drive(伪驱动程序) 。如ide-scsi,用于 IDE-SCSI仿真。
通常一个较大的性能影响是文件系统元数据怎样在磁盘上存放 。引入 磁盘条带阵列 (RAID 0、RAID 5和RAID 6)解决这个问题。在一个条带阵列上,磁头在移动到阵列中下一个磁盘之前,单个磁盘上写入的数据称为 CHUNKSIZE ,所有磁盘使用一次它后返回到第一个磁盘。 如果文件系统的布局没有匹配RAID的设计,则有可能会发生一个文件系统元数据块被分散到2个磁盘上,导致对2个磁盘发起请求 。或者 将所有的元数据在一个单独的磁盘上存储,如果该磁盘发生故障则可能导致该磁盘变成热点 。
设计RAID阵列需要考虑以下内容:
1) 文件系统使用的块大小。
2) RAID 阵列使用的CHUNK大小。
3) RAID 阵列中同等磁盘的数量。
块大小 指可以读取/写入到驱动器的最小数据量,对服务器的性能有直接的影响。块的大小由文件系统决定,在联机状态下不能更改,只有重新格式化才能修改。可以使用的块大小有1024B、2048B、4096B,默认为 4096 B。
stride条带 是在一个chunk中文件系统块的数量。如果文件系统块大小为4KB,则chunk大小为64KB,那么stride是64KB/4KB=16块。
stripe-width 是RAID阵列上一个条带中文件系统块的数量。比如 一个3块磁盘的RAID5阵列 。按照定义,在RAID5阵列每个条带中有1个磁盘包含奇偶校验内容。想要得到stripe-width,首先需要知道每个条带中有多少磁盘实际携带了数据块,即3磁盘-1校验磁盘=2数据磁盘。2个磁盘中的stride是chunk中文件系统块的数量。因此能计算 2(磁盘)*16(stride)=32(stripe)。
创建文件系统时可以使用mkfs给定数量:mk2fs -t ext4 -b 4096 -E stripe=16,stripe_width=64 /dev/vda
Linux - 磁盘I/O性能评估
文章目录

概述
RAID
可以根据应用的不同,选择不同的RAID方式
- 如果一个应用经常有大量的读操作,可以选择以RAID5方式构建磁盘阵列存储数据;
- 如果应用有大量频繁的写操作,可以选择RAID0存取方式;
- 如果应用对数据安全要求很高,同时对读写也有要求,可以考虑RAID01存取方式;
Linux-Raid0、Raid1、Raid5、Raid10初探
- 尽可能用内存的读写代替直接磁盘I/O,使频繁访问的文件或数据放入内存中进行操作处理,因为内存读写操作比直接磁盘读写的效率要高千倍。
- 将经常进行读写的文件与长期不变的文件独立出来,分别放置到不同的磁盘设备上。
- 对于写操作频繁的数据,可以考虑使用裸设备代替文件系统。
文件系统与裸设备的对比
使用裸设备的优点:
- 数据可以直接读写,不需要经过操作系统级的缓存,节省了内存资源,避免了内存资源争用。
- 避免了文件系统级的维护开销,比如文件系统需要维护超级块、inode等。
- 避免了操作系统的缓存预读功能,减少了I/O请求。
使用裸设备的缺点:
- 数据管理、空间管理不灵活,需要很专业的人来操作。
其实裸设备的优点就是文件系统的缺点,反之也是如此。合理的规划和衡量,根据应用的需求,做出对应的策略。
磁盘I/O性能评判标准
正常情况下,svctm应该是小于await值的,而svctm的大小和磁盘性能有关,CPU、内存的负荷也会对svctm值造成影响,过多的请求也会间接导致svctm值的增加。
await值的大小一般取决于svctm的值和I/O队列长度以及I/O请求模式。如果svctm的值与await很接近,表示几乎没有I/O等待,磁盘性能很好。如果await的值远高于svctm的值,则表示I/O队列等待太长,系统上运行的应用程序将变慢,此时可以通过更换更快的硬盘来解决问题。
%util项的值也是衡量磁盘I/O的一个重要指标。如果%util接近100%,表示磁盘产生的I/O请求太多,I/O系统已经满负荷地在工作,该磁盘可能存在瓶颈。长期下去,势必影响系统的性能,可以通过优化程序或者通过更换更高、更快的磁盘来解决此问题。
常用命令
“sar –d”命令组合
通过“sar –d”命令组合,可以对系统的磁盘I/O做一个基本的统计
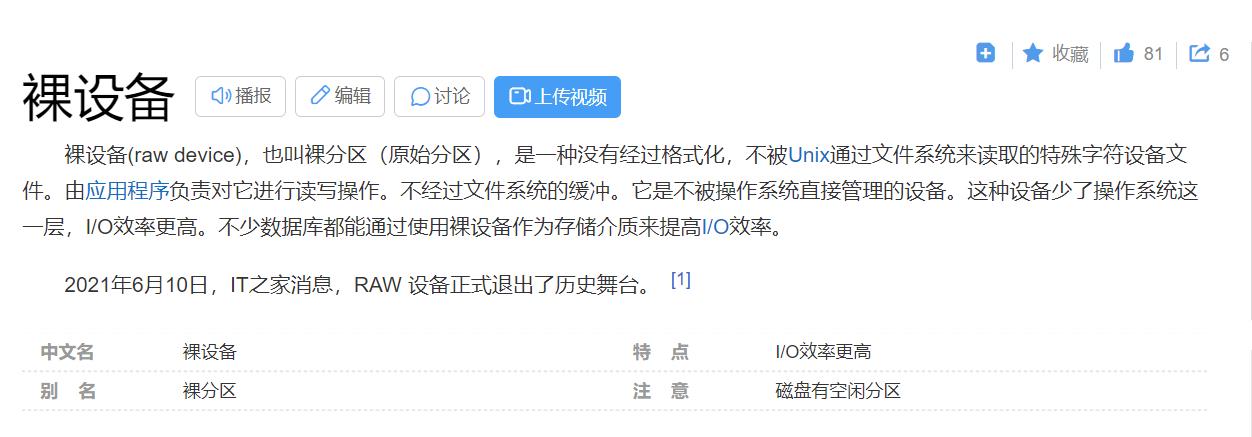
[root@VM-24-3-centos ~]# sar -d 2 3
Linux 3.10.0-1160.11.1.el7.x86_64 (VM-24-3-centos) 03/06/2023 _x86_64_ (2 CPU)
08:56:57 AM DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util
08:56:59 AM dev253-0 1.50 0.00 12.00 8.00 0.00 1.00 0.33 0.05
08:56:59 AM dev11-0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
08:56:59 AM DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util
08:57:01 AM dev253-0 54.00 0.00 640.00 11.85 0.20 3.84 0.18 0.95
08:57:01 AM dev11-0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
08:57:01 AM DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util
08:57:03 AM dev253-0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
08:57:03 AM dev11-0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Average: DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util
Average: dev253-0 18.50 0.00 217.33 11.75 0.07 3.77 0.18 0.33
Average: dev11-0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
[root@VM-24-3-centos ~]#
- DEV表示磁盘设备名称。
- tps表示每秒到物理磁盘的传送数,也就是每秒的I/O流量。一个传送就是一个I/O请求,多个逻辑请求可以合并为一个物理I/O请求。
- rd_sec/s表示每秒从设备读取的扇区数(1扇区=512字节)。
- wr_sec/s表示每秒写入设备的扇区数目。
- avgrq-sz表示平均每次设备I/O操作的数据大小(以扇区为单位)。
- avgqu-sz表示平均I/O队列长度。
- await表示平均每次设备I/O操作的等待时间(以毫秒为单位)。
- svctm表示平均每次设备I/O操作的服务时间(以毫秒为单位)。
- %util表示一秒中有百分之几的时间用于I/O操作。
Linux中I/O请求系统与现实生活中超市购物排队系统有很多类似的地方,通过对超市购物排队系统的理解,可以很快掌握Linux中I/O运行机制。比如:
- avgrq-sz类似于超市排队中每人所买东西的多少。
- avgqu-sz类似于超市排队中单位时间内平均排队的人数。
- await类似于超市排队中每人的等待时间。
- svctm类似于超市排队中收银员的收款速度。
- %util类似于超市收银台前有人排队的时间比例。

“iostat –d”命令组合
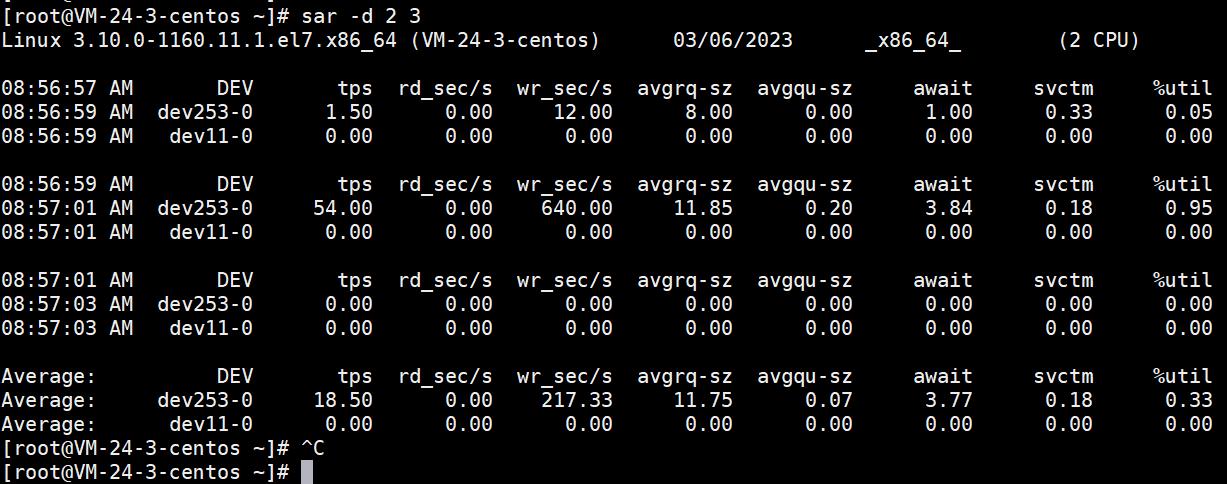
[root@VM-24-3-centos ~]# iostat -d 2 3
Linux 3.10.0-1160.11.1.el7.x86_64 (VM-24-3-centos) 03/06/2023 _x86_64_ (2 CPU)
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
vda 3.91 1.06 29.56 21828907 611223560
scd0 0.00 0.00 0.00 316 0
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
vda 0.00 0.00 0.00 0 0
scd0 0.00 0.00 0.00 0 0
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
vda 0.50 0.00 4.00 0 8
scd0 0.00 0.00 0.00 0 0
[root@VM-24-3-centos ~]#
- tps:该设备每秒的传输次数(Indicate the number of transfers per second that were issued to the device.)。“一次传输"意思是"一次I/O请求”。多个逻辑请求可能会被合并为"一次I/O请求"。"一次传输"请求的大小是未知的。
- kB_read/s:每秒从设备(drive expressed)读取的数据量;
- kB_wrtn/s:每秒向设备(drive expressed)写入的数据量;
- kB_read:读取的总数据量;
- kB_wrtn:写入的总数量数据量;这些单位都为Kilobytes。
这里需要注意的一点是,上面输出上的第一项是系统从启动以来到统计时的所有传输信息,第二次输出的数据才代表在检测的时间段内系统的传输值。
“iostat –x”单独统计某个磁盘的I/O
“iostat –x”命令组合还提供了对每个磁盘的单独统计,如果不指定磁盘,默认对所有磁盘进行统计

- rrqm/s表示每秒进行合并的读操作数目。
- wrqm/s表示每秒进行合并的写操作数目。
- r/s表示每秒完成读I/O设备的次数。
- w/s表示每秒完成写I/O设备的次数。
- rsec/s表示每秒读取的扇区数。
- wsec/s表示每秒写入的扇区数。
“vmstat –d”命令组合
通过“vmstat –d”命令组合也可以查看磁盘的统计数据。
[root@VM-24-3-centos ~]# vmstat -d 3 2
disk- ------------reads------------ ------------writes----------- -----IO------
total merged sectors ms total merged sectors ms cur sec
vda 591170 3530 43657830 4460432 80215339 54988709 1222778513 249512681 0 25485
sr0 89 0 632 22 0 0 0 0 0 0
vda 591170 3530 43657830 4460432 80215379 54988754 1222779225 249512735 0 25485
sr0 89 0 632 22 0 0 0 0 0 0
[root@VM-24-3-centos ~]#
显示了磁盘的reads、writes和IO的使用状况。
小结
衡量磁盘I/O好坏是多方面的,有应用程序本身的,也有硬件设计上的,还有系统自身配置的问题等。要解决I/O的瓶颈,关键是要提高I/O子系统的执行效率。
- 首要,要从应用程序上对磁盘读写进行优化,能够放到内存中执行的操作,尽量不要放到磁盘上。
- 其次,对磁盘存储方式进行合理规划,选择适合自己的RAID存取方式。
- 最后,在系统级别上,可以选择适合自身应用的文件系统,必要时使用裸设备提高读写性能。

以上是关于Linux磁盘I/O子系统的主要内容,如果未能解决你的问题,请参考以下文章