某线上应用在进行查询结果导出Excel时,大概率出现持续的FullGC。解决这个问题时,记录了一下整个的流程,也可以作为一般性的FullGC问题排查指导。
后续review这篇文章的时候,发现排查过程还是不够详细,虽然最终解决了问题,但是仍缺少对根因对分析,并且遗漏了一些所需技能对整理。因此根据最近另一个系统类似的fullGC现象做了进一步的分析,对本文进行了一些完善。
1. GC现场查看
1.1 系统指标
需要关注GC发生时,系统的上下文环境,判断是否有关联,以及GC对于系统运行的影响情况。
- CPU占用率
- 磁盘利用率
- 系统load,主要有三种统计方式:load1、load5、load15,分别表示1、5、15分钟内系统的平均负载
1.2 GC日志
1.2.1 准备工作
能看到GC日志的前提是JVM开启了对应参数。
常用的参数如下(摘自https://www.jianshu.com/p/ba768d8e9fec):
-verbose:gc
在虚拟机发生内存回收时在输出设备显示信息,格式如下:[Full GC 268K->168K(1984K), 0.0187390 secs]该参数用来监视虚拟机内存回收的情况。
-XX:+PrintGC
发生垃圾收集时打印简单的内存回收日志
-XX:+PrintGCDetails
发生垃圾收集时打印详细的内存回收日志
-XX:+PrintGCTimeStamps
输出GC的时间戳(以基准时间的形式,如49.459,默认就是这个输出形式,可以不写)
-XX:+PrintGCDateStamps
输出GC的时间戳(以以日期的形式,如2019-03-01T12:57:54.486+0800)
-XX:+PrintHeapAtGC
在进行GC的前后打印出堆的信息,经过个人实验,这个参数开启后只会在Minor GC的前后打印堆信息,而老年代CMS的Major GC前后则不会打印,不知道是什么原因。
-Xloggc:../logs/gc.log
日志文件的输出路径
1.2.2 GC日志分析
本节同样参考了https://www.jianshu.com/p/ba768d8e9fec的分析。此处使用的是-XX:+PrintGCDetails详细回收日志。
1.2.2.1 MinorGC
先看几条发生FullGC前MinorGC的日志:
2020-04-10T11:45:44.392+0800: 4553306.501: [GC (Allocation Failure) 2020-04-10T11:45:44.393+0800: 4553306.501: [ParNew: 1775637K->28101K(1922432K), 0.0786478 secs] 1894669K
->147135K(5068160K), 0.0790883 secs] [Times: user=0.15 sys=0.00, real=0.07 secs]
2020-04-10T12:07:19.290+0800: 4554601.399: [GC (Allocation Failure) 2020-04-10T12:07:19.291+0800: 4554601.399: [ParNew: 1775578K->174671K(1922432K), 0.2182450 secs] 1894611
K->730454K(5068160K), 0.2186251 secs] [Times: user=0.36 sys=0.16, real=0.22 secs]
2020-04-10T12:07:21.664+0800: 4554603.773: [GC (Allocation Failure) 2020-04-10T12:07:21.664+0800: 4554603.773: [ParNew: 1921986K->174550K(1922432K), 0.5629082 secs] 2477769
K->2448678K(5068160K), 0.5632692 secs] [Times: user=1.38 sys=0.00, real=0.56 secs]
先取第一行来看,本行的构成逐项解释:
2020-04-10T11:45:44.392+0800: 4553306.501时间戳[GC (Allocation Failure)发生GC,原因是新对象分配失败。这里GC有可能是Full GC,并不能确定是MinorGC。2020-04-10T11:45:44.393+0800: 4553306.501又是一个时间戳。注意到和第一个时间戳是有略微差异的[ParNew:表示使用了ParNew回收器。由于其是用于新生代的,可见是minorGC921986K->174550K(1922432K), 0.5629082 secs表示gc前该区域已使用容量->gc后该区域已使用容量(总容量),以及总耗时。1894669K->147135K(5068160K), 0.0790883 secs]表示收集前后整个堆的使用情况及总耗时,包含了将对象从新生代转移到老年代的时间[Times: user=0.15 sys=0.00, real=0.07 secs]分别是用户态时间、系统态时间、从开始到结束的等待时间(不含内核态时间、多CPU的时间等,可能小于前两者)
1.2.2.2 CMS FullGC
本文不打算详细介绍CMS,而是放在后续文章中,这里仅仅阐述一下CMS基本的信息。
- 首先CMS适用于老年代,而老年代的GC,就是FullGC
- CMS GC分为四步:
- 初始标记 ,只标记GC Root能关联的对象,会Stop the world
- 并发标记,对GC Root进行tracing
- 重新标记,修正并发标记期间因用户继续运作而变动的对象,会Stop the world
- 并发清除
以下是CMS FullGC的日志。在20分钟内,发生了多次,只截取一段。
2020-04-10T12:18:20.049+0800: 4555262.158: [GC (CMS Initial Mark) [1 CMS-initial-mark: 2274128K(3145728K)] 3153915K(5068160K), 0.2236736 secs] [Times: user=0.79 sys=0.04, r
eal=0.23 secs]
2020-04-10T12:18:20.273+0800: 4555262.382: [CMS-concurrent-mark-start]
2020-04-10T12:18:20.600+0800: 4555262.709: [CMS-concurrent-mark: 0.327/0.327 secs] [Times: user=0.24 sys=0.10, real=0.32 secs]
2020-04-10T12:18:20.600+0800: 4555262.709: [CMS-concurrent-preclean-start]
2020-04-10T12:18:20.619+0800: 4555262.728: [CMS-concurrent-preclean: 0.018/0.019 secs] [Times: user=0.01 sys=0.00, real=0.02 secs]
2020-04-10T12:18:20.619+0800: 4555262.728: [CMS-concurrent-abortable-preclean-start]
2020-04-10T12:18:20.619+0800: 4555262.728: [CMS-concurrent-abortable-preclean: 0.000/0.000 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
2020-04-10T12:18:20.621+0800: 4555262.730: [GC (CMS Final Remark) [YG occupancy: 880462 K (1922432 K)]2020-04-10T12:18:20.621+0800: 4555262.730: [Rescan (parallel) , 0.4159
862 secs]2020-04-10T12:18:21.037+0800: 4555263.146: [weak refs processing, 0.0000913 secs]2020-04-10T12:18:21.037+0800: 4555263.146: [class unloading, 0.2851138 secs]2020-0
4-10T12:18:21.322+0800: 4555263.431: [scrub symbol table, 0.0624047 secs]2020-04-10T12:18:21.385+0800: 4555263.493: [scrub string table, 0.0060674 secs][1 CMS-remark: 22741
28K(3145728K)] 3154591K(5068160K), 0.7700397 secs] [Times: user=1.10 sys=0.44, real=0.77 secs]
2020-04-10T12:18:21.391+0800: 4555263.500: [CMS-concurrent-sweep-start]
2020-04-10T12:18:21.488+0800: 4555263.597: [CMS-concurrent-sweep: 0.097/0.097 secs] [Times: user=0.07 sys=0.04, real=0.10 secs]
2020-04-10T12:18:21.489+0800: 4555263.597: [CMS-concurrent-reset-start]
2020-04-10T12:18:21.495+0800: 4555263.604: [CMS-concurrent-reset: 0.007/0.007 secs] [Times: user=0.00 sys=0.01, real=0.01 secs]
结合CMS的特性,分段来看。和MinorGC中重复的部分不再解释,如时间戳、消耗时间。
初始标记
2020-04-10T12:18:20.049+0800: 4555262.158: [GC (CMS Initial Mark) [1 CMS-initial-mark: 2274128K(3145728K)] 3153915K(5068160K), 0.2236736 secs] [Times: user=0.79 sys=0.04, r
eal=0.23 secs]
[GC (CMS Initial Mark) [1 CMS-initial-mark:表示CMS初始标记阶段2274128K(3145728K)老年代容量3145728K,在使用2274128K后触发GC。这个比例约为72%,是可以通过CMSInitiatingOccupancyFraction参数调节的。本例中实际设置是80%。3153915K(5068160K)当前堆的整体使用情况0.2236736 secs当前这一步耗时
并发标记
2020-04-10T12:18:20.273+0800: 4555262.382: [CMS-concurrent-mark-start]
2020-04-10T12:18:20.600+0800: 4555262.709: [CMS-concurrent-mark: 0.327/0.327 secs] [Times: user=0.24 sys=0.10, real=0.32 secs]
2020-04-10T12:18:20.600+0800: 4555262.709: [CMS-concurrent-preclean-start]
2020-04-10T12:18:20.619+0800: 4555262.728: [CMS-concurrent-preclean: 0.018/0.019 secs] [Times: user=0.01 sys=0.00, real=0.02 secs]
2020-04-10T12:18:20.619+0800: 4555262.728: [CMS-concurrent-abortable-preclean-start]
2020-04-10T12:18:20.619+0800: 4555262.728: [CMS-concurrent-abortable-preclean: 0.000/0.000 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[CMS-concurrent-mark-start]并发标记开始0.327/0.327 sec持续时间和时钟时间。该阶段内被用户线程改动的对象会标记为dirty card[CMS-concurrent-preclean-start]把被标记为Dirty Card的对象以及可达的对象重新遍历标记,完成后清除Dirty Card标记。另外做一些必要的清扫工作,及final remark阶段需要的准备工作[CMS-concurrent-abortable-preclean-start]并发预清理,这个阶段尝试着去承担接下来STW的Final Remark阶段足够多的工作,由于这个阶段是重复的做相同的事情直到发生aboart的条件(比如:重复的次数、多少量的工作、持续的时间等等)之一才会停止。这个阶段很大程度的影响着即将来临的Final Remark的停顿。
重新标记
这部分原始日志是折叠成一行的,为了便于分析,按时间戳排成了多行。
2020-04-10T12:18:20.621+0800: 4555262.730: [GC (CMS Final Remark) [YG occupancy: 880462 K (1922432 K)]
2020-04-10T12:18:20.621+0800: 4555262.730: [Rescan (parallel) , 0.4159862 secs]
2020-04-10T12:18:21.037+0800: 4555263.146: [weak refs processing, 0.0000913 secs]
2020-04-10T12:18:21.037+0800: 4555263.146: [class unloading, 0.2851138 secs]
2020-04-10T12:18:21.322+0800: 4555263.431: [scrub symbol table, 0.0624047 secs]
2020-04-10T12:18:21.385+0800: 4555263.493: [scrub string table, 0.0060674 secs][1 CMS-remark: 2274128K(3145728K)] 3154591K(5068160K), 0.7700397 secs] [Times: user=1.10 sys=0.44, real=0.77 secs]
[GC (CMS Final Remark)重新标记阶段,会STW[YG occupancy: 880462 K (1922432 K)]新生代占用情况[Rescan (parallel) , 0.4159862 secs]该阶段阶段扫描对象总用时,从GC Root开始处理剩余对象[weak refs processing, 0.0000913 secs]第一个子阶段,对弱引用处理耗时[class unloading, 0.2851138 secs]第二个子阶段,卸载无用类耗时[scrub symbol table, 0.0624047 secs]第三个子阶段,清理符号表耗时[scrub string table, 0.0060674 secs]第四个子阶段,清理字符串表耗时[1 CMS-remark: 2274128K(3145728K)] 3154591K(5068160K), 0.7700397 secs]处理完成后,老年代内存使用情况以及整个堆的使用情况。注意到初始标记时,这两组大小分别为2274128K(3145728K)]和3153915K(5068160K),在本例中没有任何变化。
并发清除
2020-04-10T12:18:21.391+0800: 4555263.500: [CMS-concurrent-sweep-start]
2020-04-10T12:18:21.488+0800: 4555263.597: [CMS-concurrent-sweep: 0.097/0.097 secs] [Times: user=0.07 sys=0.04, real=0.10 secs]
2020-04-10T12:18:21.489+0800: 4555263.597: [CMS-concurrent-reset-start]
2020-04-10T12:18:21.495+0800: 4555263.604: [CMS-concurrent-reset: 0.007/0.007 secs] [Times: user=0.00 sys=0.01, real=0.01 secs]
[CMS-concurrent-sweep-start]并发清除第一阶段,清除没有标记的无用对象并回收内存,以及耗时[CMS-concurrent-reset-start]并发清除第二阶段,重新设置CMS算法内部的数据结构,准备下一个CMS生命周期的使用。
例子:20分钟的连续GC
可以看出,CMS完成时,并不能直接知道此时的内存运行情况,那么将这波FullGC日志中每次CMS发生时的内存情况列表,会发现什么呢?
这里只摘了最开始、最后、以及中间的几次,并且简化了时间戳的数据。
| 开始时间戳 | 老年代已使用容量(K) | 老年代总容量(K) | 堆已使用容量(K) | 堆总容量(K) |
|---|---|---|---|---|
| 2020-04-10T12:18:20.273 | 2274128 | 3145728 | 3153915 | 5068160 |
| 2020-04-10T12:18:39.494 | 2255208 | 3145728 | 3145788 | 5068160 |
| 2020-04-10T12:18:43.091 | 2254908 | 3145728 | 3146625 | 5068160 |
| .... | .... | .... | .... | .... |
| 2020-04-10T12:33:04.495 | 2251293 | 3145728 | 3926804 | 5068160 |
| 2020-04-10T12:33:07.772 | 2251293 | 3145728 | 3929256 | 5068160 |
| 2020-04-10T12:33:07.772 | 2251293 | 3145728 | 3931359 | 5068160 |
| .... | .... | .... | .... | .... |
| 2020-04-10T12:38:17.513 | 2251240 | 3145728 | 4171165 | 5068160 |
| 2020-04-10T12:38:17.513 | 2251240 | 3145728 | 4173301 | 5068160 |
可以看出,经过20分钟,老年代的容量仍然在CMS的阈值附近徘徊,并且不断增长。最后一次CMS触发了一条特殊的日志(之前居然看漏了):
2020-04-10T12:38:23.851+0800: 4556465.960: [GC (Allocation Failure) 2020-04-10T12:38:23.851+0800: 4556465.960: [ParNew: 1922192K->1922192K(1922432K), 0.0000324 secs]
2020-04-10T12:38:23.851+0800: 4556465.960: [CMS2020-04-10T12:38:23.914+0800: 4556466.023: [CMS-concurrent-sweep: 0.066/0.070 secs] [Times: user=0.08 sys=0.00, real=0.07 secs]
(concurrent mode failure): 2251240K->112349K(3145728K), 1.4269429 secs] 4173432K->112349K(5068160K), [Metaspace: 225876K->225876K(1253376K)], 1.4284556 secs] [Times: user=
1.44 sys=0.00, real=1.43 secs]
新生代对象分配失败,ParNew也满了。concurrent mode failure出现时虚拟机会启动后备预案:临时使用一次SerialOld进行GC。这时,终于把维持在2251240K的老年代降到了112349K,并且把整个堆的4173302K降到了112349K。
注意到这两组数字,和最后一次CMS的数字是吻合的,同时,整个堆中只有老年代还有对象,占用了112349K。
由于Serial系列回收器是单个线程执行,会触发长时间的STW。这从时间上也能看出来,用了1.42秒。
1.2.3 concurrent mode failure的原因
直接原因是老年代不够用了。是什么导致老年代不够用?情况比较多:(无论是新生代发生晋升而导致)老年代容量不足、老年代容量够但是碎片过多(标记清除算法的原因)
2. dump文件分析
了解了GC期间的内存区域占用量变化情况还不够,还需要知道是哪些对象导致了这个问题。
通过生成的heap dump文件,看下发生FullGC时堆内存的分配情况,定位可能出现问题的地方。
2.1 生成dump文件
2.1.1 通过JVM参数自动生成
可以在JVM参数中设置-XX:+ HeapDumpBeforeFullGC参数。
建议动态增加这个参数,直接在线上镜像中增加一方面是要重新打包发布,另一方面风险比较高
sudo -u admin /opt/taobao/java/bin/jinfo -flag +HeapDumpBeforeFullGC pid
sudo -u admin /opt/taobao/java/bin/jinfo -flag +HeapDumpAfterFullGC pid
也可以用HeapDumpOnOutOfMemoryError这个参数,只在outOfMemoryError发生时才dump。实测只有在fullgc完成时才会产生该文件,fullgc期间看不到。
此外还需要-XX:HeapDumpPath=/home/admin/logs/java.hprof这个参数来指定dump文件存放路径。
注意:即使开启该选项,也有可能生成不了dump文件,一个常见原因是堆外内存不足。更多的原因:https://coderbee.net/index.php/jvm/20190905/1919
2.1.2 通过JDK工具生成
2.1.2.1 jmap
先获取java进程ID,再使用jmap进行dump。
注意,虚拟机上的jmap可能没有做路径映射,需要手动选择jdk路径下来执行
ps -aux | grep java
jmap -dump:file=test.hprof,format=b XXXX
也可以用jps直接获取java进程ID。
2.1.2.2 通过jcmd
JDK7后新增的多功能命令,其中jcmd pid GC.heap_dump FILE_NAME的效果和jmap -dump:file=test.hprof,format=b pid一样。
2.1.2.3 JConsole
可以生成本机或远程JVM的dump。还有一些其他工具就不详细介绍了。
2.2 下载dump文件
由于使用的是阿里云的服务器,可以直接将dump文件上传到OSS上通过公司内部工具来分析,或通过OSS再下载到本地。可能需要确认bucket是公有读写权限。
设置OSSCMD:
操作命令 osscmd config --host=oss-cn-hangzhou-am101.aliyuncs.com --id=** --key=**
创建bucke:osscmd cb 000001
上传文件:osscmd put 1.txt oss://000001/
下载文件:osscmd get oss://000001/1.txt 1.txt
其他类型的Linux主机可以使用SCP命令,参考:Linux scp命令
2.3 分析工具
通过dump文件来分析fullGC的原因,需要关注哪些类占用内存空间较多、不可到达类等。
由于使用的是公司内部工具Zprofiler和grace,详细的使用过程这里就不截图了。一些其他可用的工具和命令(参考Java内存泄漏分析系列之六:JVM Heap Dump(堆转储文件)的生成和MAT的使用):
- jhat, JDK自带,使用
jhat <heap-dump-file>生成网页,通过浏览器访问http://localhost:7000查看 - jvisualvm
- Eclipse Memory Analyzer(MAT)
- IBM Heap Analyzer
需要注意的是,只看dump文件有时还不能得到结论,因为占用空间大头的有可能是String、ArrayBlockingList这样的对象,而且内容可能是null或null对象的集合,无从排查。此时还要结合发生fullgc前后业务系统发生了什么动作来确定。如果有条件的话可以在日常环境或预发环境重现一下。
当然,如果内存中的空间消耗对象是特殊的类,就比较好排查了。
2.4 进一步排查
有时虽然对于是哪个对象触发fullGC有了一定的猜测,但是对于这个对象是怎么产生的,从dump上不一定能看到,如本例中的大数组。
对于这种情况,可以使用-XX:ArrayAllocationWarningSize=xxx参数(部分jdk支持,可以使用jinfo动态加载)进一步排查,观察它的产生原因。
3. 分析和改进
具体情况具体分析。
3.1 本次排查的场景
查询DB中数据->在异步线程中通过poi转换成Excel->上传到OSS。
示例代码:
// 导出代码中将变量直接作为lambda表达式的值传入
List<XXData> data = queryData(request);
SheetDownloadProperty property = sheetDownloadProperties.get(0);
property.setTotalCount(request.getQueryRequest().getPageSize());
property.setPageSize(request.getQueryRequest().getPageSize());
property.setQueryFunction((currentPage, pageSize) -> data);
// 该组件会在线程池异步调用poi组件转换为excel、上传OSS、下载
asyncDownloadService.downloadFile(downloadTask);
private List<XXData> queryData(ExportRequest request) {
//查询DB,略
}
// 查询方法
@FunctionalInterface
public interface PageFunction<T> {
/**
* 方法执行
*/
List<T> apply(Integer currentPage,Integer pageSize);
}
3.2 dump文件分析
通过内部工具可见,fullGC前有三个占据内存较高的ArrayBlockingList,里面有大量的内容为null的Object。
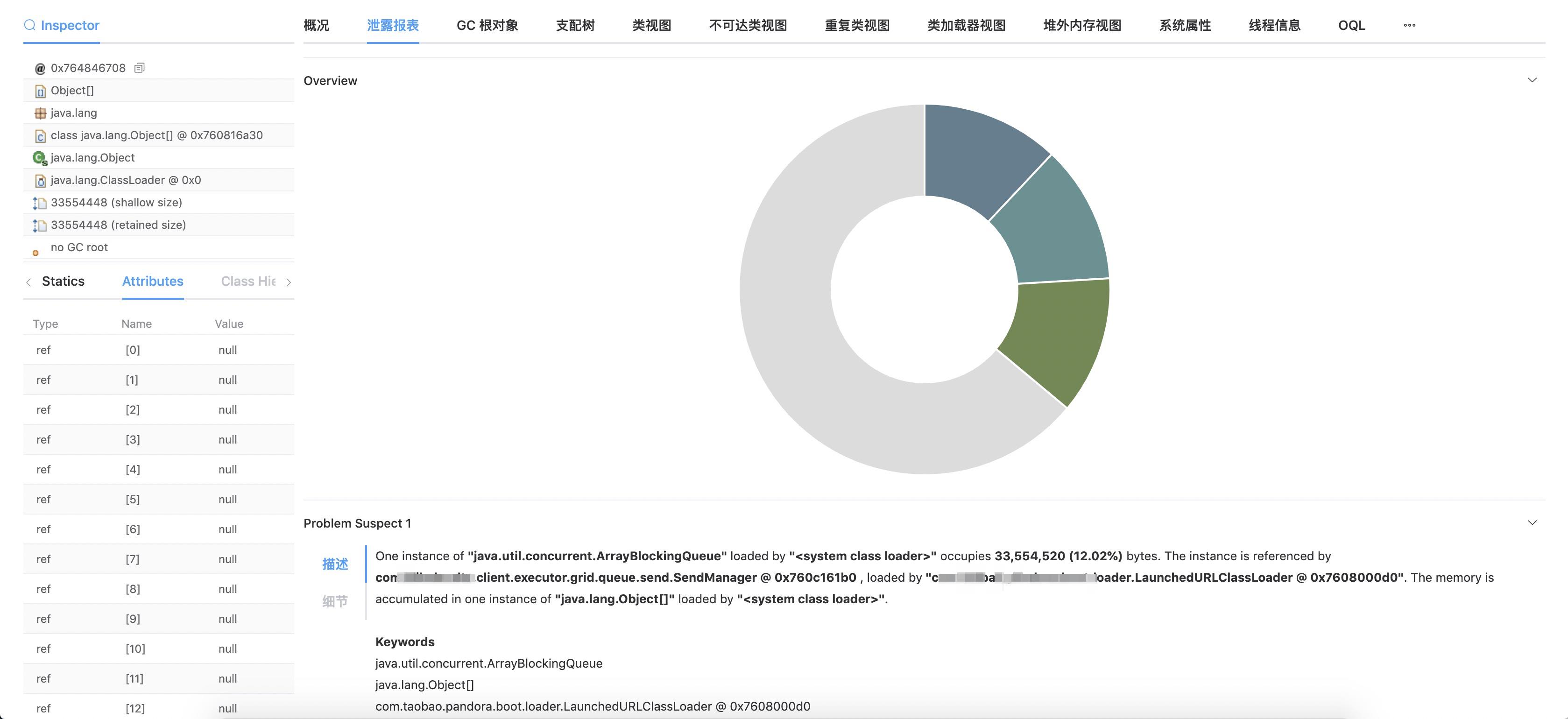
这三个ArrayBlockingList所属的中间件,虽然本身和业务流程没有关系,但是仍不能排除嫌疑。
3.3 真实原因
实际上,从dump文件上是无法看出来问题源头的,真实的原因是poi组件在关闭workbook时,内存无法释放而产生的fullgc,而不是常见的因为堆空间不足而发生的fullgc。
3.4 尝试解决
方案1:poi相关解决方案
由于依赖了二方库poi,这个库的usermodel模式很容易引起fullGC,同时也怀疑是因为lambda表达式直接传了变量。
把poi的usermodel改为事件模式(https://my.oschina.net/OutOfMemory/blog/1068972)可以避免这个问题。
但是该功能是一个二次封装的三方包中的,同时其他引用该组件的应用fullgc频率并不高,没有采用这个方案。
方案2:中间件升级
持有大量null对象的中间件版本较低,且新版目前已不再维护,老版本的releas note虽然没有提到这条bug fix,有一定嫌疑。
该中间件初始化时会创建三个容量为810241024的ArrayBlockingList,和dump文件相符合。
同样是因为这个中间件是在三方包中封装,不方便直接该版本,同样没有采用这个方案。
方案3:增大堆大小
可以调整metaspace参数来实现,本次想找到代码中相关的线索来解决,未采用该方案。
方案4:业务代码修改
仔细观察了这段代码在其他系统的的实现,发现其他系统的lambda表达式是匿名方法,而不是直接传值,即:
property.setQueryFunction((currentPage, pageSize) -> {
// 查询逻辑, 略
);
怀疑是直接传变量进去导致的垃圾回收问题。更改到这种模式后,触发下载功能时,连续长时间的fullGC仍然时有发生,没有解决问题。
方案5:替换垃圾回收器
暂时能确定的原因是,公司中间件本身占用堆内存较多,运行poi增加了GC的频率。但是由于它们都在二方库的原因,不方便修改。
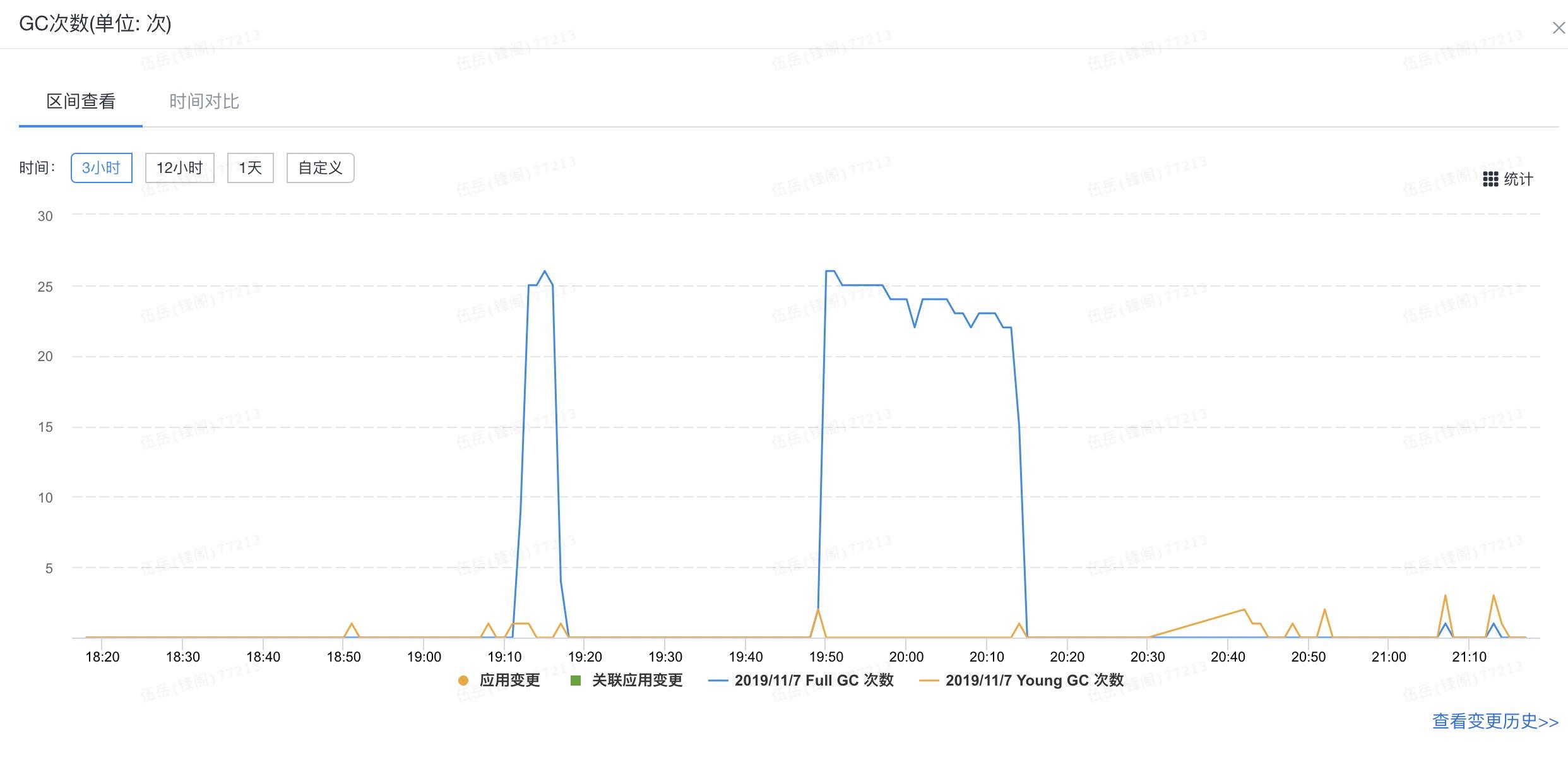
此时搜索到stackoverflow有关于poi反复GC的一个问题,和我的情况类似,也是反复GC但是仍然不能释放内存。有回复建议将GC回收器替换为G1GC,将默认的UseConcMarkSweepGC替换后效果明显,一次FullGC就可以完成回收释放,不会反复FullGC,如下图,20:30前的fullGC是CMS,持续时间长且反复进行;20:30后是替换后第一次触发excel转换下载,进行了多次下载,即使发生FullGC也只有1次,大大缓解了之前的问题:
本次暂定只采用方案5。
G1GC在JDK9已替代CMS成为了正式的垃圾回收器,低版本JDK需要手动设置。具体需要设置的JVM参数:
-Xms32m
-Xmx1g
-XX:+UnlockExperimentalVMOptions
-XX:+UseG1GC
-XX:MaxHeapFreeRatio=15
-XX:MinHeapFreeRatio=5
注意前两行一般应用都会设置,不要覆盖掉。最后两行需要视情况调整。另外,默认的-XX:+UseConcMarkSweepGC需要去掉。
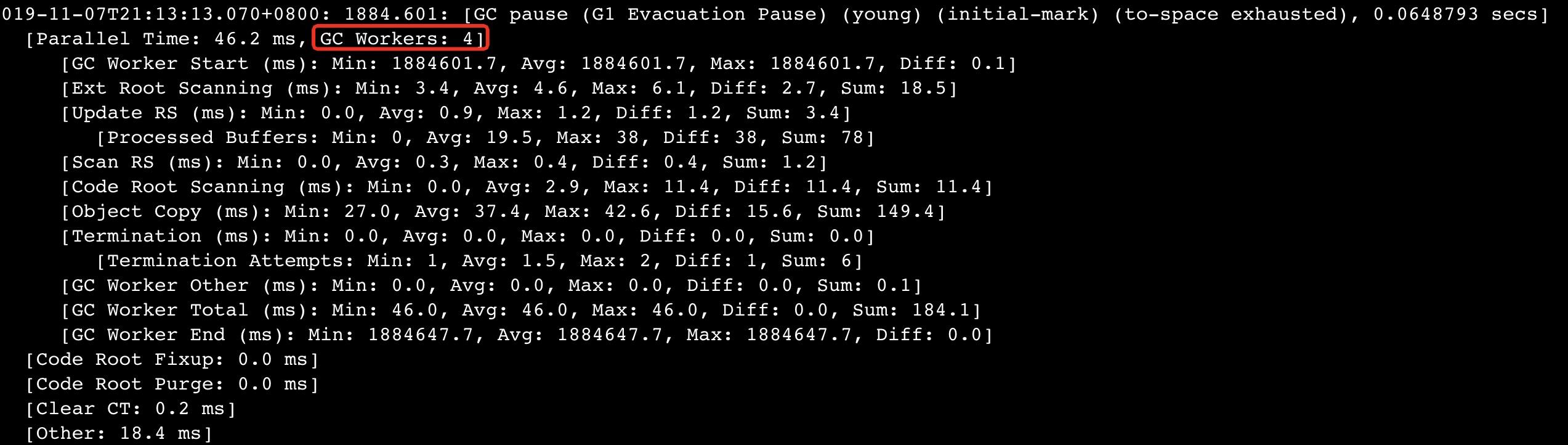
使用G1GC时需要确认工作线程数是否和预期一致,不要太多,一般来说和CPU核数一致即可。出现非预期数目的原因可能是,镜像脚本指定核数时,直接按照物理机而不是虚拟机核数来生成。
查看方式是看gc日志:
虚拟机设置核数的dokcker脚本示例:
export CPU_COUNT="$(grep -c \'cpu[0-9][0-9]*\' /proc/stat)"
4. 其他
4.1 典型fullGC场景举例
- 外部资源未释放,如将利用tair实现的分布式锁放在Map中,未做解锁
- fastjson的反序列化异常抛出后没有处理
- 框架固有缺陷,如本例apache的poi组件,使用usermodel模式做excel导出时,当操作比较频繁或有其他内存泄漏有可能造成
- JVM的metaspace设置过小
4.2 core dump和heap dump
core dump是针对线程某一时刻的运行情况的,可以看到执行到哪个类哪个方法哪一行以及执行栈的;heap dump是针对内存某一时刻的分配情况的。
4.3 stackoverflow上关于poi内存占用问题的讨论:
简单摘译了一些,可以直接看原文。
- Java对堆内存分配是懒回收的,如果JVM不想这么做,即使运行Runtime.gc(),也可能什么也不做。sapiensl和Amongalen的回答
- 触发FullGC,并不是因为内存泄漏,仅仅是因为poi占用了太多的内存。Michael的回答
关于G1GC,会在后续文章中研究。
相似的一例:https://blog.csdn.net/CaptainLYF/article/details/86238148