dentry与inode有啥联系和区别
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了dentry与inode有啥联系和区别相关的知识,希望对你有一定的参考价值。
参考技术A我们在进程中要怎样去描述一个文件呢?我们用目录项(dentry)和索引节点(inode)。它们的定义如下:
struct dentry
struct inode *d_inode; /* Where the name belongs to - NULL is
struct dentry *d_parent; /* parent directory */
struct list_head d_child; /* child of parent list */
struct dentry_operations *d_op;
struct super_block *d_sb; /* The root of the dentry tree */
void *d_fsdata; /* fs-specific data */
unsigned char d_iname[DNAME_INLINE_LEN_MIN]; /* small names */
......
;
struct inode
unsigned long i_ino;
atomic_t i_count;
umode_t i_mode;
unsigned int i_nlink;
uid_t i_uid;
gid_t i_gid;
dev_t i_rdev;
loff_t i_size;
struct timespec i_atime;
unsigned long i_blocks;
unsigned short i_bytes;
unsigned char _sock;
12
struct inode_operations *i_op;
struct file_operations *i_fop; /* former ->i_op->default_file_ops */
struct super_block *i_sb;
......
;
所谓"文件", 就是按一定的形式存储在介质上的信息,所以一个文件其实包含了两方面的信息,一是存储的数据本身,二是有关该文件的组织和管理的信息。在内存中, 每个文件都有一个dentry(目录项)和inode(索引节点)结构,dentry记录着文件名,上级目录等信息,正是它形成了我们所看到的树状结构;而有关该文件的组织和管理的信息主要存放inode里面,它记录着文件在存储介质上的位置与分布。同时dentry->d_inode指向相应的inode结构。dentry与inode是多对一的关系,因为有可能一个文件有好几个文件名(硬链接, hard link, 可以参考这个网页http://www.ugrad.cs.ubc.ca/~cs219/CourseNotes/Unix/commands-links.html)。
所有的dentry用d_parent和d_child连接起来,就形成了我们熟悉的树状结构。
inode代表的是物理意义上的文件,通过inode可以得到一个数组,这个数组记录了文件内容的位置,如该文件位于硬盘的第3,8,10块,那么这个数组的内容就是3,8,10。其索引节点号inode->i_ino,在同一个文件系统中是唯一的,内核只要根据i_ino,就可以计算出它对应的inode在介质上的位置。就硬盘来说,根据i_ino就可以计算出它对应的inode属于哪个块(block),从而找到相应的inode结构。但仅仅用inode还是无法描述出所有的文件系统,对于某一种特定的文件系统而言,比如ext3,在内存中用ext3_inode_info描述。他是一个包含inode的"容器"。
struct ext3_inode_info
__le32 i_data[15];
......
struct inode vfs_inode;
;
le32 i data[15]这个数组就是上一段中所提到的那个数组。
注意,在遥远的2.4的古代,不同文件系统索引节点的内存映像(ext3_inode_info,reiserfs_inode_info,msdos_inode_info ...)都是用一个union内嵌在inode数据结构中的. 但inode作为一种非常基本的数据结构而言,这样搞太大了,不利于快速的分配和回收。但是后来发明了container_of(...)这种方法后,就把union移到了外部,我们可以用类似container of(inode, struct ext3_inode_info, vfs_inode),从inode出发,得到其的"容器"。
dentry和inode终究都是在内存中的,它们的原始信息必须要有一个载体。否则断电之后岂不是玩完了?且听我慢慢道来。
文件可以分为磁盘文件,设备文件,和特殊文件三种。设备文件暂且不表。
磁盘文件
就磁盘文件而言,dentry和inode的载体在存储介质(磁盘)上。对于像ext3这样的磁盘文件来说,存储介质中的目录项和索引节点载体如下,
struct ext3_inode
__le16 i_mode; /* File mode */
__le16 i_uid; /* Low 16 bits of Owner Uid */
__le32 i_size; /* Size in bytes */
__le32 i_atime; /* Access time */
__le32 i_ctime; /* Creation time */
__le32 i_mtime; /* Modification time */
__le32 i_dtime; /* Deletion Time */
__le16 i_gid; /* Low 16 bits of Group Id */
__le16 i_links_count; /* Links count */
......
__le32 i_block[EXT2_N_BLOCKS];/* Pointers to blocks */
......
struct ext3_dir_entry_2
__u32 inode; /* Inode number */
__u16 rec_len; /* Directory entry length */
__u8 name_len; /* Name length */
__u8 file_type;
char name[EXT3_NAME_LEN]; /* File name */
;
le32 i block[EXT2 N BLOCKS];/* Pointers to blocks */
i_block数组指示了文件的内容所存放的地点(在硬盘上的位置)。
ext3_inode是放在索引节点区,而ext3_dir_entry_2是以文件内容的形式存放在数据区。我们只要知道了ino,由于ext3_inode大小已知,我们就可以计算出ext3_inode在索引节点区的位置( ino * sizeof(ext3_inode) ),而得到了ext3_inode,我们根据i_block就可以知道这个文件的数据存放的地点。将磁盘上ext3_inode的内容读入到ext3_inode_info中的函数是ext3_read_inode()。以一个有100 block的硬盘为例,一个文件系统的组织布局大致如下图。位图区中的每一位表示每一个相应的对象有没有被使用。

特殊文件
特殊文件在内存中有inode和dentry数据结构,但是不一定在存储介质上有"索引节点",它断电之后的确就玩完了,所以不需要什么载体。当从一个特殊文件读时,所读出的数据是由系统内部按一定的规则临时生成的,或从内存中收集,加工出来的。sysfs里面就是典型的特殊文件。它存储的信息都是由系统动态的生成的,它动态的包含了整个机器的硬件资源情况。从sysfs读写就相当于向kobject层次结构提取数据。
还请注意, 我们谈到目录项和索引节点时,有两种含义。一种是在存储介质(硬盘)中的(如ext3_inode),一种是在内存中的,后者是根据在前者生成的。内存中的表示就是dentry和inode,它是VFS中的一层,不管什么样的文件系统,最后在内存中描述它的都是dentry和inode结构。我们使用不同的文件系统,就是将它们各自的文件信息都抽象到dentry和inode中去。这样对于高层来说,我们就可以不关心底层的实现,我们使用的都是一系列标准的函数调用。这就是VFS的精髓,实际上就是面向对象。
我们在进程中打开一个文件F,实际上就是要在内存中建立F的dentry,和inode结构,并让它们与进程结构联系来,把VFS中定义的接口给接起来。我们来看一看这个经典的图。这张图之于文件系统,就像每天爱你多一些之于张学友,番茄炒蛋之于复旦南区食堂,刻骨铭心。
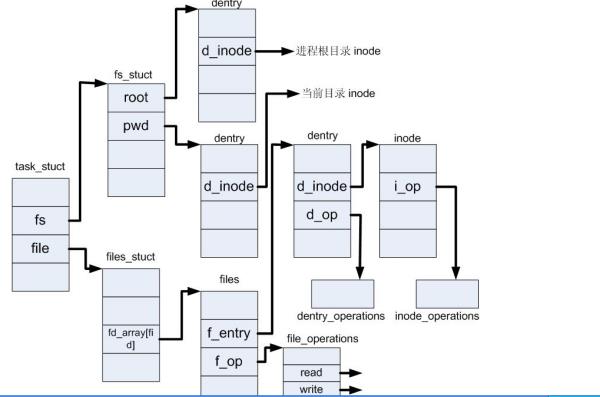
文件系统(ext2)及linux相关文件指令
首先了解两个文件相关的概念:inode和dentry,inode和dentry本质都是一个结构体。inode用来存储文件的属性信息,如:权限、类型、大小、时间、用户、盘块位置等。dentry的主要属性是名称数量、文件名和inode。从此我们可以看出一个文件必然对应一个inode,但是一个inode可以对应多个文件名称。
linux观察方法如下:
touch inodetest;
ln inodetest inodetest1;
stat inodetest;
stat inodetest1;
在linux下输入上面的命令可以看到两个stat输出的inode是一样的,其中stat中的Links表示当前inode对应的文件数量。
同样我们从inode和dentry的解释中可以看到,其实删除文件的本质只是释放了dentry对inode的绑定即inode对盘块位置的绑定,文件系统并不会去直接修改磁盘块的内容。这个和C语言中的malloc、free一样,malloc是绑定地址标识地址占用状态,free其实只是解除地址占用状态,在free之后,只要系统不对这个地址的内容进行写操作,那么只要原指针不重新指向,读出的此指针指向的内容与free前一致。这就说明在删除文件后,只要文件系统不对当前盘块进行写操作,那么文件是可以被恢复的。如果想要彻底删除一个文件,需要在删除文件后,再对当前磁盘进行一个覆盖写入,可以下载电影到磁盘中将磁盘占满即可。
一个磁盘可以划分成多个分区,每个分区必须先用格式化工具格式化成某种格式的文件系统,然后才能存储文件,格式化的过程会在磁盘上写一些管理存储布局的信息。下图是一个磁盘分区格式化成ext2文件系统后的存储布局:
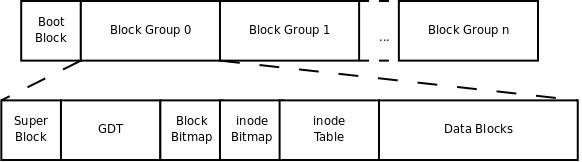
由此可以看出,一个分区是由一个BootBlock和多个BlockGroup组成的,其中BootBlock(BootSector)为启动扇区,用来存储分区信息和启动信息,所以这个地方可以用来安装启动引导程序,此扇区大小为1K。
每个块组(BlockGroup)由6部分组成,超级块(SuperBlock)、文件系统描述说明(GDT)、区块对照表(Block Bitmap)、inode对照表(inodeBitmap)、inode表(InodeTable)、数据块(DataBlocks)。
超级块SuperBlock是记录整个文件系统相关信息的地方,是文件系统的基础,其描述整个分区的文件系统信息,例如块大小、文件系统版本号、上次mount的时间等等,超级块在每个块组的开头都有一份拷贝,其大小一般为1204B,可以使用命令dumpe2fs查看其信息,主要信息如下:
数据块与Inode总数量
未使用与已使用的inode与数据块的数量
数据块与inode的大小(数据块:1K、2K、4K;inode:128B、256B)
文件系统挂载标识、挂载时间、最后一次写入数据时间、最近一次检验磁盘的时间等信息
文件系统描述说明GDT由很多块组描述符组成,整个分区分成多少个块组就对应有多少个块组描述符。每个块组描述符(Group Descriptor)存储一个块组的描述信息,例如在这个块组中从哪里开始是inode表,从哪里开始是数据块,空闲的inode和数据块还有多少个等等。和超级块类似,块组描述符表在每个块组的开头也都有一份拷贝,这些信息是非常重要的,一旦超级块意外损坏就会丢失整个分区的数据,一旦块组描述符意外损坏就会丢失整个块组的数据,因此它们都有多份拷贝。通常内核只用到第0个块组中的拷贝,当执行e2fsck检查文件系统一致性时,第0个块组中的超级块和块组描述符表就会拷贝到其它块组,这样当第0个块组的开头意外损坏时就可以用其它拷贝来恢复,从而减少损失。
区块对照表Block Bitmap 一个块组中的块是这样利用的:数据块存储所有文件的数据,比如某个分区的块大小是1024字节,某个文件是2049字节,那么就需要三个数据块来存,即使第三个块只存了一个字节也需要占用一个整块。那么如何知道哪些块已经用来存储文件数据或其它描述信息,哪些块仍然空闲可用呢?块位图就是用来描述整个块组中哪些块已用哪些块空闲的,它本身占一个块,其中的每个bit代表本块组中的一个块,这个bit为1表示该块已用,这个bit为0表示该块空闲可用。在格式化一个分区时究竟会划出多少个块组呢?主要的限制在于块位图本身必须只占一个块。用mke2fs格式化时默认块大小是1024字节,可以用-b参数指定块大小,现在设块大小指定为x字节,那么一个块可以有8x个bit,这样大小的一个块位图就可以表示8x个块的占用情况,因此一个块组最多可以有8x个块,如果整个分区有s个块,那么就可以有s/(8x)个块组。格式化时可以用-g参数指定一个块组有多少个块,但是通常不需要手动指定,mke2fs工具会计算出最优的数值。
inode对照表inode Bitmap 和区块对照表类似,本身占一个块,其中每个bit表示一个inode是否空闲可用。
inode表inode Table主要包括文件类型、权限、文件大小、创建/修改/访问时间、文件的特性标识、文件真正的内容指向。每个文件都只有一个inode,一个块组中的所有inode组成了inode表。inode表占多少个块在格式化时就要决定并写入块组描述符中,mke2fs格式化工具的默认策略是一个块组有多少个8KB就分配多少个inode。由于数据块占了整个块组的绝大部分,也可以近似认为数据块有多少个8KB就分配多少个inode,换句话说,如果平均每个文件的大小是8KB,当分区存满的时候inode表会得到比较充分的利用,数据块也不浪费。如果用户在格式化时能够对这个分区以后要存储的文件大小做一个预测,也可以用mke2fs的-i参数手动指定每多少个字节分配一个inode。inode表中每个inode的大小:ext2、ext3中128字节,ext4和xfs可以设置到256字节。
inode扩展:
三级寻址:inode里面有12个直接寻址地址、1个一级间接寻址地址、1个两级间接寻址地址、1个三级间接寻址,每个寻址地址大小为4B,如果每个区块大小为1K,那么直接寻址记录的最大地址是121K,一级间接寻址记录的最大存储是(11K/4B)1K,二级间接寻址记录的最大存储是(11K/4B)1K/4B1K,三级间接寻址记录的最大存储是(11K/4B)1K/4B1K/4B1K,即1个inode能够指向的最大地址空间为12K+256K+256256K+256256256K=16.06,向下取整等于16GB。如果区块大小为2K那么一个inode记录的最大大小为122K+(12K/4B)2K+(12K/4B)2K/4B2K+(12K/4B)2K/4B2K/4B2K=24K+1024K+256K2K+1024K*256K(数据太大不进行下一步计算),同理可以计算出4K区块inode最大的指向空间。
小文件对文件系统的影响:一个小文件占用的内存最小是一个区块的大小,即如果区块大小是4K,那么即使一个文件只有2B,其占用的实际空间也是4K,会造成磁盘空间的浪费,而且由于inode数量是有限的,如果存储的小文件过多就会导致inode被占满,然后无法存储文件。
数据块Data Block 根据不同的文件类型有以下几种情况:
对于常规文件,文件的数据存储在数据块中;
对于目录,该目录下的所有文件名和目录名存储在数据块中,注意文件名保存在它所在目录的数据块中,除文件名之外,ls -l命令看到的其它信息都保存在该文件的inode中。注意这个概念:目录也是一种文件,是一种特殊类型的文件;
对于符号链接,如果目标路径名较短则直接保存在inode中以便更快地查找,如果目标路径名较长则分配一个数据块来保存;
设备文件、FIFO和socket等特殊文件没有数据块,设备文件的主设备号和次设备号保存在inode中。
对于文件信息来说最重要的一个函数就是statle,其原型int stat(const char *path, struct stat *buf)。
struct stat 结构体详解:
struct stat
{
dev_t st_dev; /* ID of device containing file */文件使用的设备号
ino_t st_ino; /* inode number */ 索引节点号
mode_t st_mode; /* protection */ 文件对应的模式,文件,目录等
nlink_t st_nlink; /* number of hard links */ 文件的硬连接数
uid_t st_uid; /* user ID of owner */ 所有者用户识别号
gid_t st_gid; /* group ID of owner */ 组识别号
dev_t st_rdev; /* device ID (if special file) */ 设备文件的设备号
off_t st_size; /* total size, in bytes */ 以字节为单位的文件容量
blksize_t st_blksize; /* blocksize for file system I/O */ 包含该文件的磁盘块的大小
blkcnt_t st_blocks; /* number of 512B blocks allocated */ 该文件所占的磁盘块
time_t st_atime; /* time of last access */ 最后一次访问该文件的时间
time_t st_mtime; /* time of last modification */ /最后一次修改该文件的时间
time_t st_ctime; /* time of last status change */ 最后一次改变该文件状态的时间
};
此函数可以满足几乎所有文件信息的获取,如文件修改时间、文件类型、文件大小、文件所有者等内容。
以上是关于dentry与inode有啥联系和区别的主要内容,如果未能解决你的问题,请参考以下文章