hive的Hive 体系结构
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hive的Hive 体系结构相关的知识,希望对你有一定的参考价值。
参考技术A主要分为以下几个部分:
用户接口
用户接口主要有三个:CLI,Client 和 WUI。其中最常用的是 CLI,Cli 启动的时候,会同时启动一个 Hive 副本。Client 是 Hive 的客户端,用户连接至 Hive Server。在启动 Client 模式的时候,需要指出 Hive Server 所在节点,并且在该节点启动 Hive Server。 WUI 是通过浏览器访问 Hive。
元数据存储
Hive 将元数据存储在数据库中,如 mysql、derby。Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
解释器、编译器、优化器、执行器
解释器、编译器、优化器完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在 HDFS 中,并在随后由 MapReduce 调用执行。
Hadoop
Hive 的数据存储在 HDFS 中,大部分的查询由 MapReduce 完成(包含 * 的查询,比如 select * from tbl 不会生成 MapReduce 任务)。
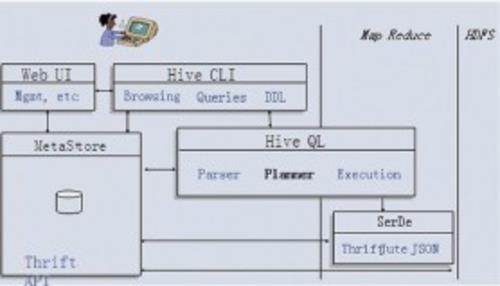
Hive体系
1、Hive体系
1.1、Hive是什么?
由Facebook开源用于解决海量结构化日志的数据统计,后成为Apache Hive作为一个开源项目。
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射成一张表,并提供类SQL查询功能;
使用HDFS存储;本质是将HQL转化成MapReduce程序,Hive的表其实就是HDFS上的目录和文件。
1.2、Hive的架构
1)用户接口:Client
CLI(hive shell)、JDFB/ODBC(java访问hive)、WEBUI(浏览器访问hive)
2)Metastore
Hive的metastore就是元数据信息,通常我们会把元数据存储在MySQL数据库中,MySQL数据库本身有一套非常完善的保证数据安全性的机制,元数据信息主要包括库名、表名、表字段、以及表文件位置等信息。建议采用MySQL主从机制,对元数据库实时备份,另外,也可以结合一些冷备手段对hive的metastore元数据定期备份。
3)驱动器:Driver
解析器:将SQL字符串转换成抽象语法树AST,这一步一般都是第三方工具完成。
编译器:将AST编译成逻辑执行计划。
优化器:对逻辑执行计划进行优化。
执行器:把逻辑执行计划转换成可以运行的物理计划。对与hive来说就是MR、Spark。
4)Hive数据仓库和MySQL数据库的异同
MySQL数据库可以用在 Online 的应用中,Hive 主要进行离线的大数据分析
查询语句 HQL 和 SQL
存储位置 HDFS 和 LocalFS
索引 hive 没有
Hive 执行 MapReduce,mysql 执行 Executor
延迟性 hive 高
可扩展性 hive 高
数据规模 hive 大
5)hive优点与使用场景
操作接口采用类SQL语法,提供快速开发的能力(简单、容易上手)。
避免了去写MR,减少开发人员的学习成本。
统一的元数据管理,可以与impala/spark等共享元数据。
易扩展(HDFS+MapReduce:可以扩展集群规模;支持自定义函数)。
数据的离线处理;比如:日志分析、海量结构化数据离线分析。
Hive的执行延迟比较高,因此hive常用于离线数据分析的,对于实时性要求不高的场合。
Hive优势在于处理大数据,对于处理小数据没有优势,因为Hive的执行延迟比较高。
以上是关于hive的Hive 体系结构的主要内容,如果未能解决你的问题,请参考以下文章