mysql innodb建立普通索引怎么写
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了mysql innodb建立普通索引怎么写相关的知识,希望对你有一定的参考价值。
从 mysql 5.7 开始,开发人员改变了 InnoDB 构建二级索引的方式,采用自下而上的方法,而不是早期版本中自上而下的方法了。在这篇文章中,我们将通过一个示例来说明如何构建 InnoDB 索引。最后,我将解释如何通过为 innodb_fill_factor 设置更合适的值。
索引构建过程
在有数据的表上构建索引,InnoDB 中有以下几个阶段:1.读取阶段(从聚簇索引读取并构建二级索引条目)2.合并排序阶段3.插入阶段(将排序记录插入二级索引)在 5.6 版本之前,MySQL 通过一次插入一条记录来构建二级索引。这是一种“自上而下”的方法。搜索插入位置从树的根部(顶部)开始并达到叶页(底部)。该记录插入光标指向的叶页上。在查找插入位置和进行业面拆分和合并方面开销很大。从MySQL 5.7开始,添加索引期间的插入阶段使用“排序索引构建”,也称为“批量索引加载”。在这种方法中,索引是“自下而上”构建的。即叶页(底部)首先构建,然后非叶级别直到根(顶部)。
示例
在这些情况下使用排序的索引构建:
- ALTER TABLE t1 ADD INDEX(or CREATE INDEX)ALTER TABLE t1 ADD FULLTEXT INDEXALTER TABLE t1 ADD COLUMN, ALGORITHM = INPLACEOPIMIZE t1对于最后两个用例,ALTER 会创建一个中间表。中间表索引(主要和次要)使用“排序索引构建”构建。
算法
在 0 级别创建页,还要为此页创建一个游标使用 0 级别处的游标插入页面,直到填满页面填满后,创建一个兄弟页(不要插入到兄弟页)为当前的整页创建节点指针(子页中的最小键,子页码),并将节点指针插入上一级(父页)在较高级别,检查游标是否已定位。如果没有,请为该级别创建父页和游标在父页插入节点指针如果父页已填满,请重复步骤 3, 4, 5, 6现在插入兄弟页并使游标指向兄弟页在所有插入的末尾,每个级别的游标指向最右边的页。提交所有游标(意味着提交修改页面的迷你事务,释放所有锁存器)为简单起见,上述算法跳过了有关压缩页和 BLOB(外部存储的 BLOB)处理的细节。通过自下而上的方式构建索引
为简单起见,假设子页和非子页中允许的 最大记录数为 3
CREATE TABLE t1 (a INT PRIMARY KEY, b INT, c BLOB);
INSERT INTO t1 VALUES (1, 11, 'hello111');
INSERT INTO t1 VALUES (2, 22, 'hello222');
INSERT INTO t1 VALUES (3, 33, 'hello333');
INSERT INTO t1 VALUES (4, 44, 'hello444');
INSERT INTO t1 VALUES (5, 55, 'hello555');
INSERT INTO t1 VALUES (6, 66, 'hello666');
INSERT INTO t1 VALUES (7, 77, 'hello777');
INSERT INTO t1 VALUES (8, 88, 'hello888');
INSERT INTO t1 VALUES (9, 99, 'hello999');
INSERT INTO t1 VALUES (10, 1010, 'hello101010');
ALTER TABLE t1 ADD INDEX k1(b);
InnoDB 将主键字段追加到二级索引。二级索引 k1 的记录格式为(b, a)。在排序阶段完成后,记录为:
(11,1), (22,2), (33,3), (44,4), (55,5), (66,6), (77,7), (88,8), (99,9), (1010, 10)初始插入阶段
让我们从记录 (11,1) 开始。在 0 级别(叶级别)创建页创建一个到页的游标所有插入都将转到此页面,直到它填满了箭头显示游标当前指向的位置。它目前位于第 5 页,下一个插入将转到此页面。还有两个空闲插槽,因此插入记录 (22,2) 和 (33,3) 非常简单
对于下一条记录 (44,4),页码 5 已满(前面提到的假设最大记录数为 3)。这就是步骤。
页填充时的索引构建
创建一个兄弟页,页码 6不要插入兄弟页在游标处提交页面,即迷你事务提交,释放锁存器等作为提交的一部分,创建节点指针并将其插入到 【当前级别 + 1】 的父页面中(即在 1 级别)节点指针的格式 (子页面中的最小键,子页码) 。第 5 页的最小键是 (11,1) 。在父级别插入记录 ((11,1),5)。1 级别的父页尚不存在,MySQL 创建页码 7 和指向页码 7 的游标。将 ((11,1),5) 插入第 7 页现在,返回到 0 级并创建从第 5 页到第 6 页的链接,反之亦然0 级别的游标现在指向兄弟页,页码为 6将 (44,4) 插入第 6 页
下一个插入 - (55,5) 和 (66,6) - 很简单,它们转到第 6 页。插入记录 (77,7) 类似于 (44,4),除了父页面 (页面编号 7) 已经存在并且它有两个以上记录的空间。首先将节点指针 ((44,4),8) 插入第 7 页,然后将 (77,7) 记录到同级 8 页中。插入记录 (88,8) 和 (99,9) 很简单,因为第 8 页有两个空闲插槽。下一个插入 (1010,10) 。将节点指针 ((77,7),8) 插入 1级别的父页(页码 7)。
MySQL 在 0 级创建同级页码 9。将记录 (1010,10) 插入第 9 页并将光标更改为此页面。
以此类推。在上面的示例中,数据库在 0 级别提交到第 9 页,在 1 级别提交到第 7 页。
我们现在有了一个完整的 B+-tree 索引,它是自下至上构建的!索引填充因子
全局变量 innodb_fill_factor 用于设置插入 B-tree 页中的空间量。默认值为 100,表示使用整个业面(不包括页眉)。聚簇索引具有 innodb_fill_factor=100 的免除项。 在这种情况下,聚簇索引也空间的 1 /16 保持空闲。即 6.25% 的空间用于未来的 DML。
值 80 意味着 MySQL 使用了 80% 的页空间填充,预留 20% 于未来的更新。如果 innodb_fill_factor=100 则没有剩余空间供未来插入二级索引。如果在添加索引后,期望表上有更多的 DML,则可能导致业面拆分并再次合并。在这种情况下,建议使用 80-90 之间的值。此变量还会影响使用 OPTIMIZE TABLE 和 ALTER TABLE DROP COLUMN, ALGOITHM=INPLACE 重新创建的索引。也不应该设置太低的值,例如低于 50。因为索引会占用浪费更多的磁盘空间,值较低时,索引中的页数较多,索引统计信息的采样可能不是最佳的。优化器可以选择具有次优统计信息的错误查询计划。排序索引构建的优点
没有页面拆分(不包括压缩表)和合并没有重复搜索插入位置插入不会被重做记录(页分配除外),因此重做日志子系统的压力较小缺点
ALTER 正在进行时,插入性能降低 Bug#82940,但在后续版本中计划修复。
题主应该知道B-树和B+树最重要的一个区别就是B+树只有叶节点存放数据,其余节点用来索引,而B-树是每个索引节点都会有Data域。
这就决定了B+树更适合用来存储外部数据,也就是所谓的磁盘数据。
从Mysql(Inoodb)的角度来看,B+树是用来充当索引的,一般来说索引非常大,尤其是关系性数据库这种数据量大的索引能达到亿级别,所以为了减少内存的占用,索引也会被存储在磁盘上。
那么Mysql如何衡量查询效率呢?磁盘IO次数,B-树(B类树)的特定就是每层节点数目非常多,层数很少,目的就是为了就少磁盘IO次数,当查询数据的时候,最好的情况就是很快找到目标索引,然后读取数据,使用B+树就能很好的完成这个目的,但是B-树的每个节点都有data域(指针),这无疑增大了节点大小,说白了增加了磁盘IO次数(磁盘IO一次读出的数据量大小是固定的,单个数据变大,每次读出的就少,IO次数增多,一次IO多耗时啊!),而B+树除了叶子节点其它节点并不存储数据,节点小,磁盘IO次数就少。这是优点之一。
另一个优点是什么,B+树所有的Data域在叶子节点,一般来说都会进行一个优化,就是将所有的叶子节点用指针串起来。这样遍历叶子节点就能获得全部数据,这样就能进行区间访问啦。
至于MongoDB为什么使用B-树而不是B+树,可以从它的设计角度来考虑,它并不是传统的关系性数据库,而是以Json格式作为存储的nosql,目的就是高性能,高可用,易扩展。首先它摆脱了关系模型,上面所述的优点2需求就没那么强烈了,其次Mysql由于使用B+树,数据都在叶节点上,每次查询都需要访问到叶节点,而MongoDB使用B-树,所有节点都有Data域,只要找到指定索引就可以进行访问,无疑单次查询平均快于Mysql(但侧面来看Mysql至少平均查询耗时差不多)。
总体来说,Mysql选用B+树和MongoDB选用B-树还是以自己的需求来选择的。本回答被提问者采纳
(MYSQL)回表查询原理,利用联合索引实现索引覆盖
一、什么是回表查询?
这先要从InnoDB的索引实现说起,InnoDB有两大类索引:
- 聚集索引(clustered index)
- 普通索引(secondary index)
InnoDB聚集索引和普通索引有什么差异?
InnoDB聚集索引的叶子节点存储行记录,因此, InnoDB必须要有,且只有一个聚集索引:
(1)如果表定义了PK,则PK就是聚集索引;
(2)如果表没有定义PK,则第一个not NULL unique列是聚集索引;
(3)否则,InnoDB会创建一个隐藏的row-id作为聚集索引;
所以PK查询非常快,直接定位行记录。
InnoDB普通索引的叶子节点存储主键值。
注意,不是存储行记录头指针,MyISAM的索引叶子节点存储记录指针。
举个栗子,不妨设有表:
t(id PK, name KEY, sex, flag);
id是聚集索引,name是普通索引。
表中有四条记录:
1, shenjian, m, A 3, zhangsan, m, A 5, lisi, m, A 9, wangwu, f, B
该聚集索引和普通索引如图:
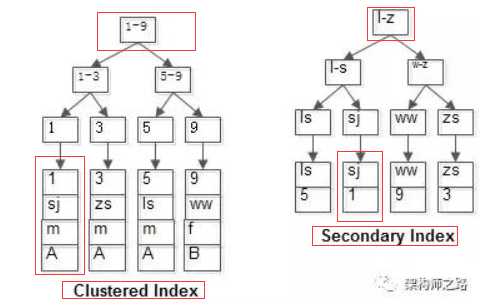
(1)id为PK,聚集索引,叶子节点存储行记录;
(2)name为KEY,普通索引,叶子节点存储PK值,即id;
既然从普通索引无法直接定位行记录,那普通索引的查询过程是怎么样的呢?
(重点)通常情况下,需要先遍历普通索引的B+树获得聚集索引主键id,然后遍历聚集索引的B+树获得行记录的对应的值。
select * from t where name=‘lisi‘;
如下图所示流程:
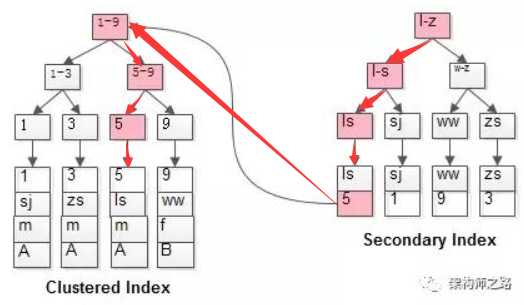
如粉红色路径,需要扫码两遍索引树:
(1)先通过普通索引定位到主键值id=5;
(2)在通过聚集索引定位到行记录;
(重点)这就是所谓的回表查询,先定位主键值,再定位行记录,它的性能较扫一遍索引树更低。
二、什么是索引覆盖(Covering index)?
explain查询计划优化章节,即explain的输出结果Extra字段为Using index时,能够触发索引覆盖。
只需要在一棵索引树上就能获取SQL所需的所有列数据,无需回表,速度更快。
三、如何实现索引覆盖?
常见的方法是:将被查询的字段,建立到联合索引里去。
仍是《迅猛定位低效SQL》中的例子:
create table user ( id int primary key, name varchar(20), sex varchar(5), index(name) )engine=innodb;
第一个SQL语句:
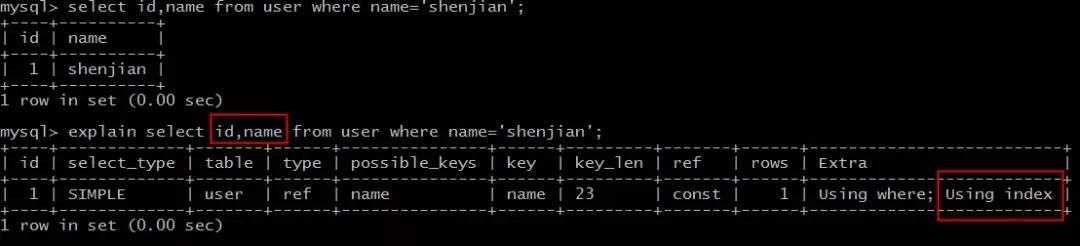
select id,name from user where name=‘shenjian‘;
能够命中name索引,索引叶子节点存储了主键id,通过name的索引树即可获取id和name,无需回表,符合索引覆盖,效率较高。
Extra:Using index。
第二个SQL语句:
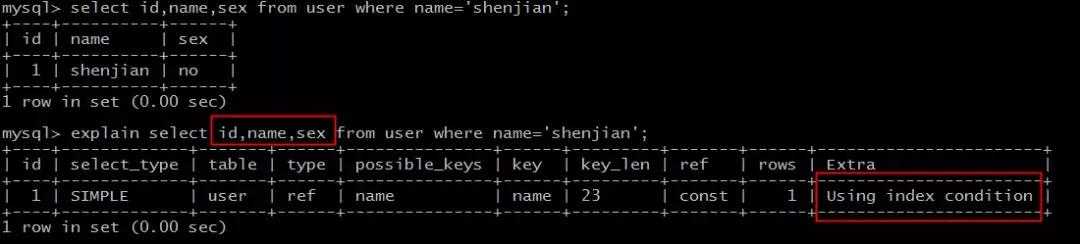
select id,name,sex from user where name=‘shenjian‘;
能够命中name索引,索引叶子节点存储了主键id,但sex字段必须回表查询才能获取到,不符合索引覆盖,需要再次通过id值扫描聚集索引获取sex字段,效率会降低。
Extra:Using index condition。
如果把(name)单列索引升级为联合索引(name, sex)就不同了。
create table user ( id int primary key, name varchar(20), sex varchar(5), index(name, sex) )engine=innodb;
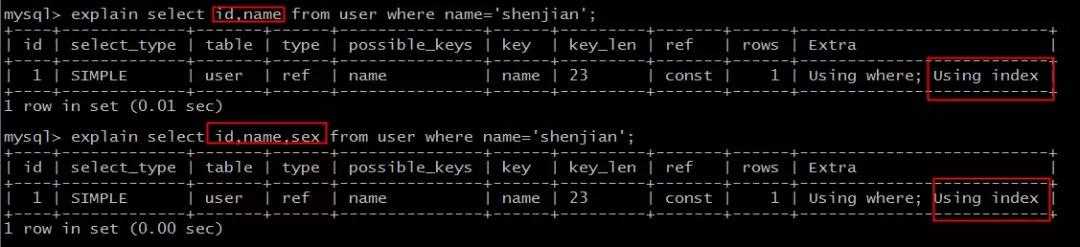
可以看到:
select id,name ... where name=‘shenjian‘;
select id,name,sex ... where name=‘shenjian‘;
都能够命中索引覆盖,无需回表。
画外音,Extra:Using index。
四、哪些场景可以利用索引覆盖来优化SQL?
场景1:全表count查询优化
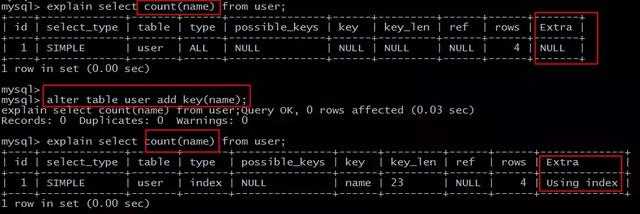
原表为:
user(PK id, name, sex);
直接:
select count(name) from user;
不能利用索引覆盖。
添加索引:
alter table user add key(name);
就能够利用索引覆盖提效。
场景2:列查询回表优化
select id,name,sex ... where name=‘shenjian‘;
这个例子不再赘述,将单列索引(name)升级为联合索引(name, sex),即可避免回表。
场景3:分页查询
select id,name,sex ... order by name limit 500,100;
将单列索引(name)升级为联合索引(name, sex),也可以避免回表。
来源:
以上是关于mysql innodb建立普通索引怎么写的主要内容,如果未能解决你的问题,请参考以下文章
MySQL - InnoDB主键索引、普通索引、唯一索引、联合索引