array = [0,1,2,3,4,5] ;
print len(array) 6;
同样,要获取一字符串的长度,也是用这个len函数,包括其他跟长度有关的,都是用这个函数。
L1=len(list1) #列表list1的长度
list2=list(set(list1)) #可以用set,直接去掉重复的元素
[456, 'abc']print "First list length : ",
len(list1);print "Second list length : ", len(list2);
扩展资料:
Python 是一门有条理的和强大的面向对象的程序设计语言,类似于Perl, Ruby, Scheme, Java。
自从20世纪90年代初Python语言诞生至今,它已被逐渐广泛应用于系统管理任务的处理和Web编程。
以下实例展示了 len()函数的使用方法:
#!/usr/bin/pythonlist1,
list2 = [123, 'xyz', 'zara']
参考资料:Python-百度百科
参考技术A
参考代码:
list1 = ['physics', 'chemistry', 1997, 2000];
list2 = [1, 2, 3, 4, 5 ];
list3 = ["a", "b", "c"];
len(list1)
len(list2)
len(list3)
Python支持列表切割(list slices),可以取得完整列表的一部分。支持切割操作的类型有str, bytes, list, tuple等。它的语法是...[left:right]或者...[left:right:stride]。假定nums变量的值是[1, 3, 5, 7,],那么下面几个语句为真:
nums[2:5] == [5, 7] 从下标为2的元素切割到下标为5的元素,但不包含下标为5的元素。
nums[1:] == [3, 5, 7] 切割到最后一个元素。
nums[:-3] == [1, 3, 5, 7] 从最开始的元素一直切割到倒数第3个元素。
nums[:] == [1, 3, 5, 7] 返回所有元素。改变新的列表不会影响到nums。
nums[1:5:2] == [3, 7] 从下标为1的元素切割到下标为5的元素但不包含下标为5的元素,且步长为2。

扩展资料:
Python 是一门有条理的和强大的面向对象的程序设计语言,类似于Perl, Ruby, Scheme, Java。
Python在设计上坚持了清晰划一的风格,这使得Python成为一门易读、易维护,并且被大量用户所欢迎的、用途广泛的语言。
设计者开发时总的指导思想是,对于一个特定的问题,只要有一种最好的方法来解决就好了。这在由Tim Peters写的Python格言(称为The Zen of Python)里面表述为:There should be one-- and preferably only one --obvious way to do it. 这正好和Perl语言(另一种功能类似的高级动态语言)的中心思想TMTOWTDI(There's More Than One Way To Do It)完全相反。
Python的作者有意的设计限制性很强的语法,使得不好的编程习惯(例如if语句的下一行不向右缩进)都不能通过编译。其中很重要的一项就是Python的缩进规则。
参考资料:百度百科-Python
count():
统计列表中元素重复的次数
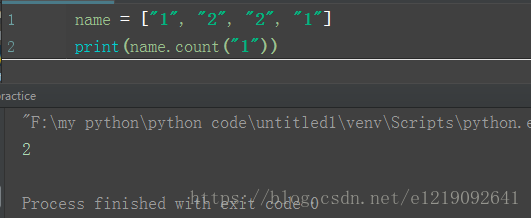
name = ["1", "2", "2", "1"]
print(name.count("1"))
len():
就算“长度”
如果要统计列表中所有的元素的个数那么用count()函数就不行了,因为count()至少要输入一个参数,此时就可以用到len()函数了,
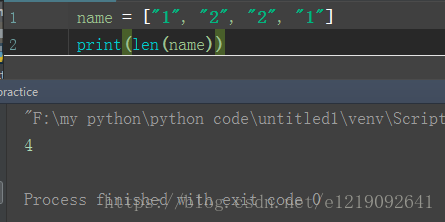
name = ["1", "2", "2", "1"]
print(len(name))
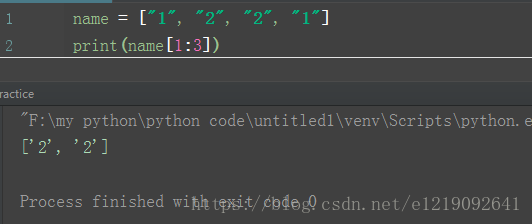
列表的切片:
直接用列表名+[ ](里面的第一个参数表示起始位置,第二个参数是步长,默认是1,可以省略,第三个参数是停止位置,应该是停止位置的前一个,是不包括前一个位置的)
append():
在列表中的最后位置添加元素
name = ["4", "3", "2", "1"]
name.append("5")
print(name)
name = ["4", "3", "2", "1"]
name.reverse()
print(name)
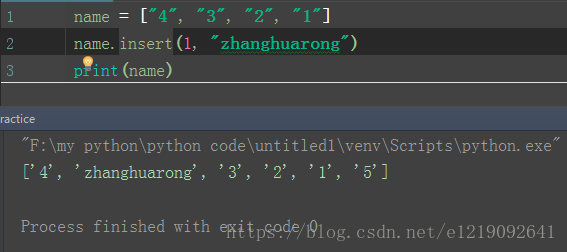
insert():
可以在任意位置插入新元素
name = ["4", "3", "2", "1"]
name.insert(1,"zhanghuarong")
print(name)
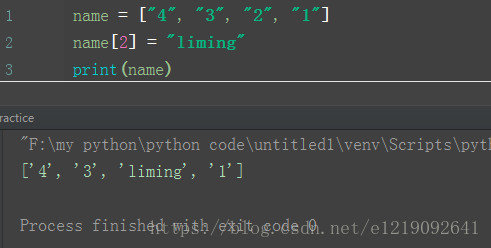
替换:
name = ["4", "3", "2", "1"]
name[2] = "liming"
print(name)
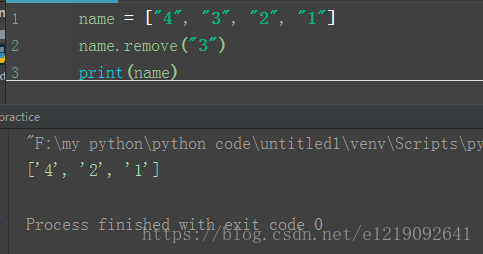
remove():
name = ["4", "3", "2", "1"]
name.remove("3")
print(name)
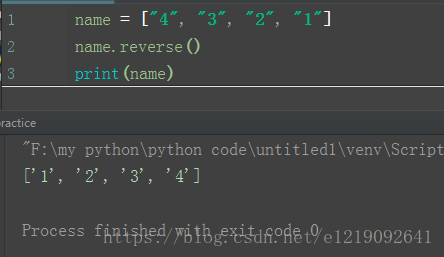
reverse():
列表元素翻转
name = ["4", "3", "2", "1"]
name.reverse()
print(name)
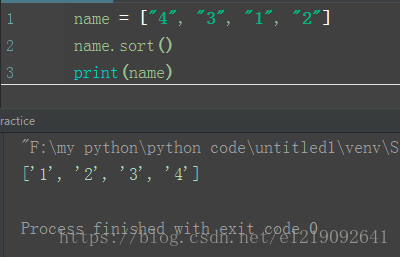
sort():
升序排序
name = ["4", "3", "1", "2"]
name.sort()
print(name)
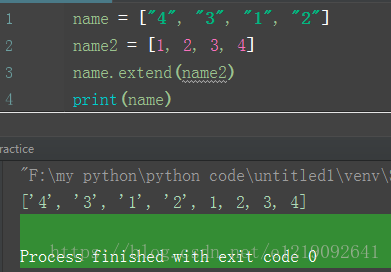
extend():
name = ["4", "3", "1", "2"]
name2 = [1, 2, 3, 4]
name.extend(name2)
print(name)
clear():
清除列表所有的元素
name = ["4", "3", "1", "2"]
name.clear()
print(name)
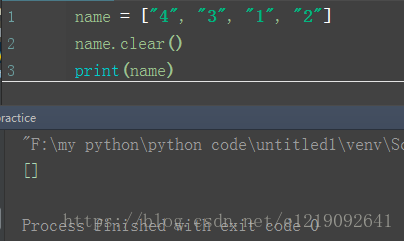
清除列表元素以后就是一个空列表了。