mysql进行分区之后所占的空间是否会变更大?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了mysql进行分区之后所占的空间是否会变更大?相关的知识,希望对你有一定的参考价值。
主库备库的表大小也对不上,分区表和原表的表大小也对不上,搞不懂。分区分了61个,只用了42个。找了几个条件查了下数据都是对的上的,应该不是没同步。想问 下是不是分区的特性是这样的?(但又感觉不太对,主库备库的表大小也对不上)也不确定是不是mysql版本不一样的问题...
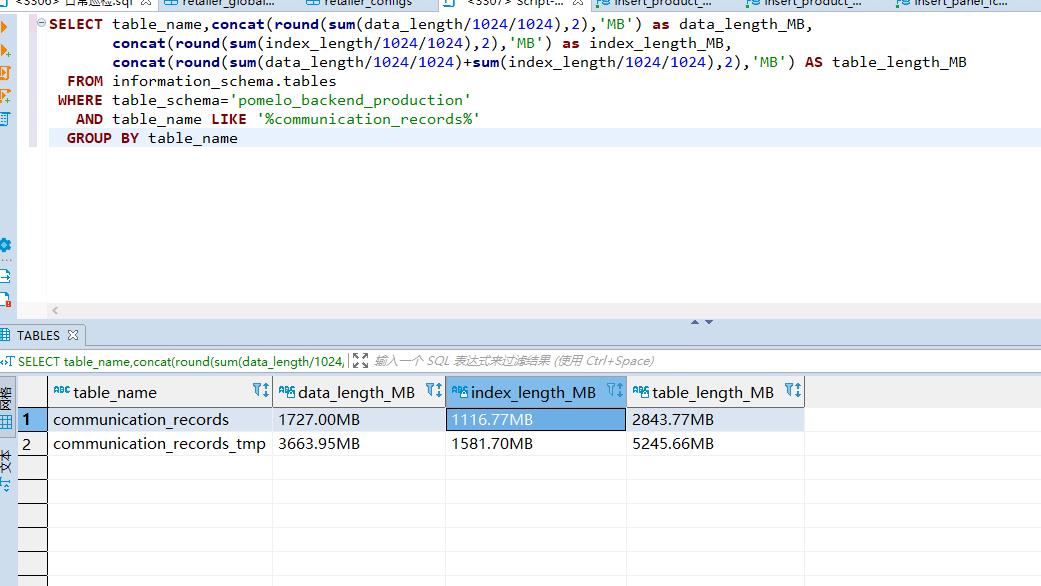
这些原因就导致了主从库占用磁盘空间大小有些差别现象。
Sql优化之Mysql表分区
一 分区表适用于以下场景
1:表非常大以至于无法全部放在内存中,或者只在标的最后部分有热点数据,其他均是历史数据
2:分区表的数据更容易维护。例如想批量删除大量数据可以使用清除整个分区的方式。另外还可以对一个独立分区进行优化、检查、修复等操作。
3:分区表的数据可以分布在不同的物理设备上,从而高效的利用多个硬件设备
4:可以使用分区表来避免某些特殊的瓶颈。例如InnoDB的单个索引的互斥访问、ext3文件系统的inode锁竞争等。
5:如果需要,还可以备份和恢复独立的分区,这在非常大的数据集的场景下效果非常好。
二 分区原理以及限制
mysql数据库中的数据是以文件的形势存在磁盘上的,默认放在/mysql/data下面(可以通过my.cnf中的datadir来查看),一张表主要对应着三个文件,一个是frm存放表结构的,一个是myd存放表数据的,
一个是myi存表索引的。如果一张表的数据量太大的话,那么myd,myi就会变的很大,查找数据就会变的很慢,这个时候我们可以利用mysql的分区功能,
在物理上将这一张表对应的三个文件,分割成许多个小块,这样呢,我们查找一条数据时,就不用全部查找了,只要知道这条数据在哪一块,然后在那一块找就行了。
如果表的数据太大,可能一个磁盘放不下,这个时候,我们可以把数据分配到不同的磁盘里面去。
分区表的限制

分区表的原理
SELECT 查询:当查询一个分区表的时候,分区层先打开并锁住所有底层表,优化器先判断是否可以过滤部分分区,然后再调用对应的存储引擎接口访问各个分区的数据;
INSERT操作:当写入一条数据时,分区层先打开并锁住所有的底层表,然后确定那个分区接收这条数据,然后再将记录写入对应的底层表;
DELETE操作:当删除一条记录时,分区层现代开并锁住所有的底层表,然后确定数据对应的分区,最后对相应底层进行删除操作;
UPDATE操作:当更新一条记录时,分区层先打开并锁住所有的底层表,MYSQL先确定需要更新的记录在哪个分区,然后取出数据并更新,在判断更新后的数据应该放在哪个分区,最后对底层表进行写入操作,并对原数据所在的底层表进行删除操作。
当然其中有些操作是支持过滤的。例如当删除一条记录时,MYSQL 需要先找到这条记录,如果where条件恰好和分区表达式匹配,就可以将所有不包含这条记录的分区都过滤掉。同样的操作对于update同样有效。如果是insert操作,其本身就是只命中一个分区 ,其他分区都会被过滤掉。MYSQL先确定这条记录属于哪个分区,再将记录写入对应的底层分区表,无须对任何其他分区进行操作。(虽然每个操作都会“”“先打开并锁住所有的底层表”,但是并不是说分区表在处理过程中是锁住全表的,如果存储引擎能够自己实现行级锁,例如InnoDB,则会在分区层释放对应表锁)。
分区表的类型:MYSQL支持多种分区表
最常见的就是根据范围进行分区,每个分区存储落在某个范围的记录,分区表达式可以是列,也可以是列的表达式。下面的例子是将每一年的销售额存放在不同的分区里。
三 创建分区操作
增加子分区操作
子分区是分区表中每个分区的再次分割,子分区既可以使用HASH希分区,也可以使用KEY分区。这 也被称为复合分区(composite partitioning)
1. 如果一个分区中创建了子分区,其他分区也要有子分区
2. 如果创建了了分区,每个分区中的子分区数必有相同
3. 同一分区内的子分区,名字不相同,不同分区内的子分区名子可以相同(5.1.50不适用)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
mysql> CREATE TABLE IF NOT EXISTS `sub_part` (
-> `news_id` int(11) NOT NULL COMMENT ‘新闻ID‘,
-> `content` varchar(1000) NOT NULL DEFAULT ‘‘ COMMENT ‘新闻内容‘,
-> `u_id` int(11) NOT NULL DEFAULT 0s COMMENT ‘来源IP‘,
-> `create_time` DATE NOT NULL DEFAULT ‘0000-00-00 00:00:00‘ COMMENT ‘时间‘
-> ) ENGINE=INNODB DEFAULT CHARSET=utf8
-> PARTITION BY RANGE(YEAR(create_time))
-> SUBPARTITION BY HASH(TO_DAYS(create_time))(
-> PARTITION p0 VALUES LESS THAN (1990)(SUBPARTITION s0,SUBPARTITION s1,SUBPARTITION s2),
-> PARTITION p1 VALUES LESS THAN (2000)(SUBPARTITION s3,SUBPARTITION s4,SUBPARTITION good),
-> PARTITION p2 VALUES LESS THAN MAXVALUE(SUBPARTITION tank0,SUBPARTITION tank1,SUBPARTITION tank3)
-> );
Query OK, 0 rows affected (0.07 sec)
|
分区管理
增加分区操作(针对设置MAXVALUE)
range添加分区
|
1
2
3
|
mysql>alter table operation_log add partition(partition `2013-10` values less than (1383235200)); --->适用于没有设置MAXVALUE的分区添加
ERROR 1481 (HY000):MAXVALUE can only be used in last partition definition
mysql>alter table operation_log REORGANIZE partition `2013-09` into (partition `2013-09` values less than (1380556800),partition `2013-10` values less than (1383235200),partition `2013-11` values less than maxvalue);
|
list添加分区
|
1
2
3
|
mysql> alter table list_part add partition(partition p4 values in (25,26,28));
Query OK, 0 rows affected (0.01 sec)
Records: 0 Duplicates: 0 Warnings: 0
|
hash重新分区
|
1
2
3
|
mysql> alter table list_part add partition(partition p4 values in (25,26,28));
Query OK, 0 rows affected (0.01 sec)
Records: 0 Duplicates: 0 Warnings: 0
|
key重新分区
|
1
2
3
|
mysql> alter table key_part add partition partitions 4;
Query OK, 1 row affected (0.06 sec)//有数据也会被重新分配
Records: 1 Duplicates: 0 Warnings: 0
|
子分区添加新分区,虽然我没有指定子分区,但是系统会给子分区命名的
|
1
2
3
|
mysql> alter table sub1_part add partition(partition p3 values less than MAXVALUE);
Query OK, 0 rows affected (0.02 sec)
Records: 0 Duplicates: 0 Warnings: 0
|
删除分区操作
alter table user drop partition2013-05;
分区表其他操作
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
重建分区(官方:与先drop所有记录然后reinsert是一样的效果;用于整理表碎片)
alter table operation_log rebuild partition `2014-01`;
重建多个分区
alter table operation_log rebuild partition `2014-01`,`2014-02`;
过程如下:
pro
优化分区(如果删除了一个分区的大量记录或者对一个分区的varchar blob text数据类型的字段做了许多更新,此时可以对分区进行优化以回收未使用的空间和整理分区数据文件)
alter table operation_log optimize partition `2014-01`;
优化的操作相当于check partition,analyze partition 和repair patition
分析分区
alter table operation_log analyze partition `2014-01`;
修复分区
alter table operation_log repair partition `2014-01`;
检查分区
alter table operation_log check partition `2014-01`;
|
以上是关于mysql进行分区之后所占的空间是否会变更大?的主要内容,如果未能解决你的问题,请参考以下文章