开发scrapy web界面
Posted apuyuseng
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了开发scrapy web界面相关的知识,希望对你有一定的参考价值。
scrapy 是一个很强大的爬虫框架,可以自定义很多插件,满足我们不同的需求....
首先我们应该要会用twisted 写web service
其实scrapy 已经帮我们做了整理了
from scrapy.utils.reactor import listen_tcp
listen_tcp就可以开启web service
所以web 插件可以这样写
class WebService(server.Site): name = ‘WebService‘ def __init__(self, crawler): self.crawler = crawler self.crawler.itemData = [] portal = Portal(PublichtmlRealm(Root(self.crawler)), [StringCredentialsChecker(‘test‘, ‘tset‘)]) credential_factory = BasicCredentialFactory("Auth") resource = HTTPAuthSessionWrapper(portal, [credential_factory]) server.Site.__init__(self,resource) self.crawler.signals.connect(self.start_listening, signals.engine_started) self.crawler.signals.connect(self.stopService, signals.engine_stopped) self.crawler.signals.connect(self.item_scraped, signals.item_scraped) self.crawler.signals.connect(self.spider_idle, signal=signals.spider_idle) @classmethod def from_crawler(cls, crawler): return cls(crawler) def start_listening(self): self.port = listen_tcp([8000,8070], ‘127.0.0.1‘,self) h = self.port.getHost() logger.info("scrapy web console available at http://%(host)s:%(port)d", {‘host‘: h.host, ‘port‘: h.port}, extra={‘crawler‘: self.crawler}) import webbrowser webbrowser.open("http://%(host)s:%(port)d"%{‘host‘: h.host, ‘port‘: h.port}) def stopService(self): self.port.stopListening() def item_scraped(self,item, response, spider): try: self.crawler.itemData.append(item) except: pass def spider_idle(self): raise DontCloseSpider
然后界面可以在Root里实现。
以下是实现的界面
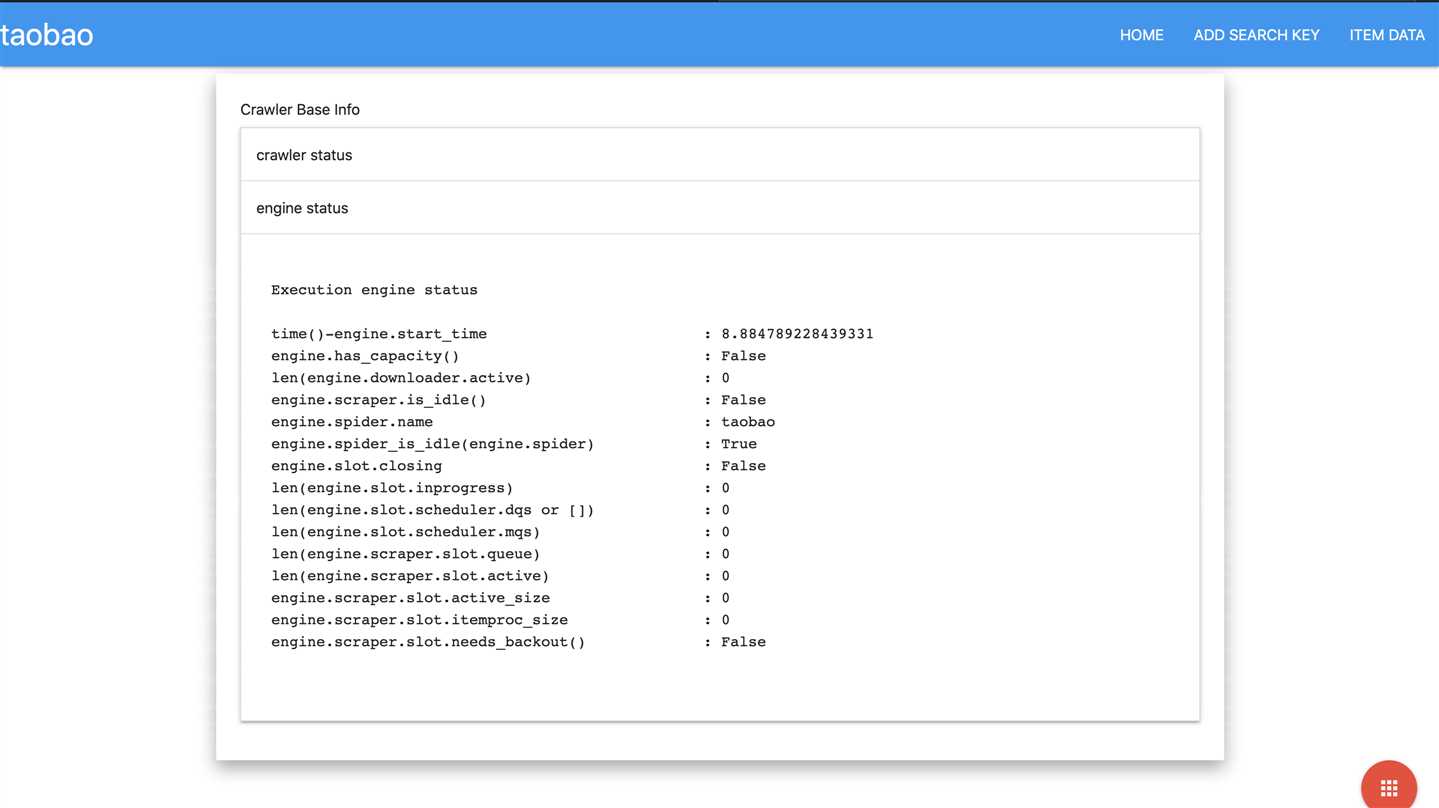
可以添加控制爬虫的一些操作,如爬虫暂停、添加开始爬的内容等
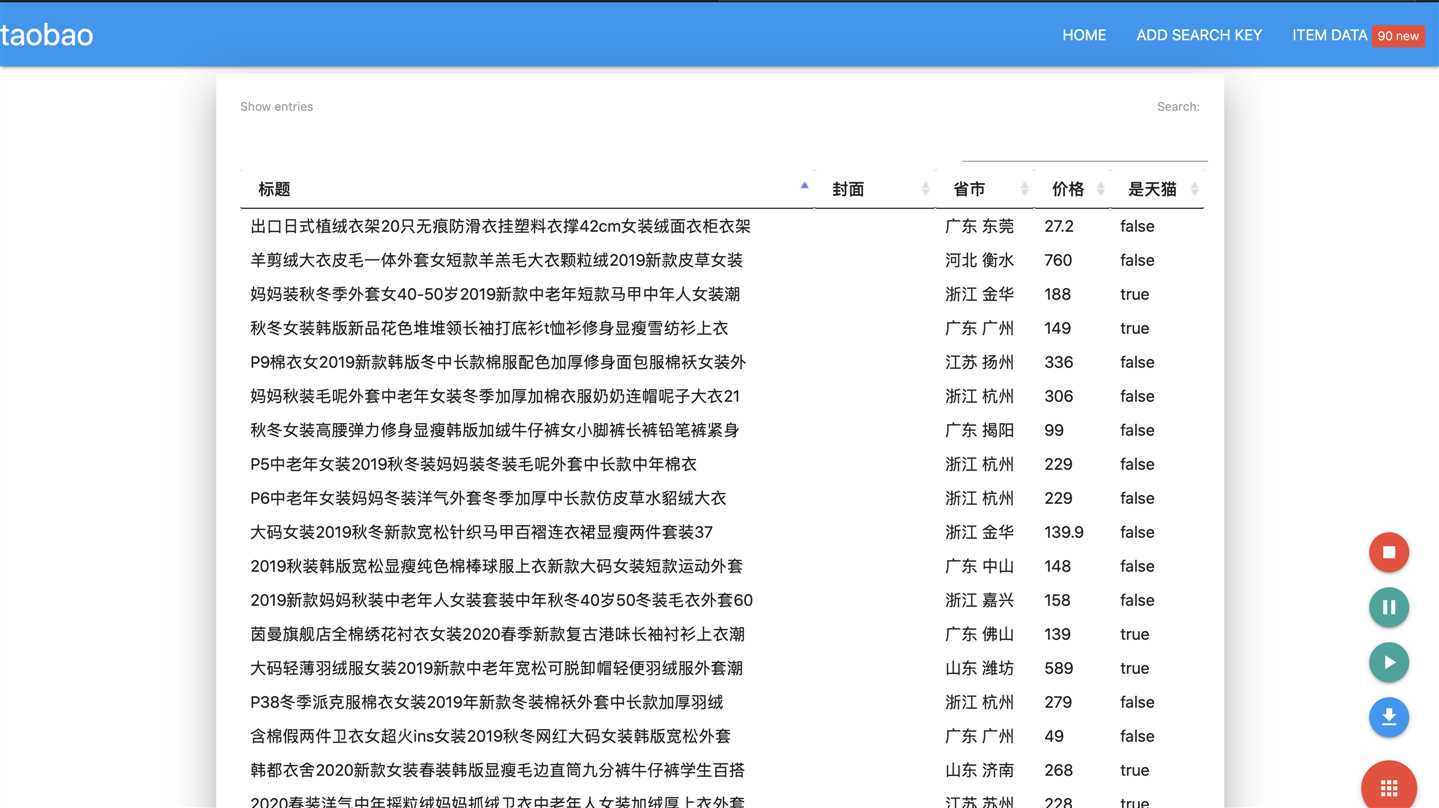
当然、还可以做一些调试的界面或是其他有趣的
以上是关于开发scrapy web界面的主要内容,如果未能解决你的问题,请参考以下文章