用python求1到100所有奇数的和
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了用python求1到100所有奇数的和相关的知识,希望对你有一定的参考价值。
第一种
def Sum():num=0
x=1
while x<=100:
if x%2==1:#判断为奇数时相加
num+=x
x+=1
print('1---100奇数的和为:',num)
if __name__=="__main__":
Sum()
第二种
x=1
arr=[]#定义一个数组用来存储奇数
while x<=100:
if x%2==1:
arr.append(x)#如果为奇数便把它存入数组中
x+=1
print('1---100奇数的和为:',sum(arr))
#最后用python的sum函数直接把列表相加
if __name__=="__main__":
Sum()
希望可以帮助到你
i in range(0,100):if i%2==1:sum += i;】。
Python求1到100的奇数和的方法:
只要条件满足,就不断循环,条件不满足时退出循环。
sum = 0
n = 99
while n > 0:
sum = sum + n
n = n - 2
print(sum)
我们要计算100以内所有奇数之和,可以用while循环实现:
在循环内部变量n不断自减,直到变为-1时,不再满足while条件,循环退出。
#100以内奇数的和(不包括100)
sum = 0
for i in range(0,100):
if i%2==1:
sum += i
print(sum) 参考技术B 回答
您好,您的问题我已经看到了,正在整理答案,请稍等一会儿~
python求1到100的奇数和的方法:
只要条件满足,就不断循环,条件不满足时退出循环。sum = 0
n = 99
while n > 0:
sum = sum + n
n = n - 2
print(sum)
我们要计算100以内所有奇数之和,可以用while循环实现:
在循环内部变量n不断自减,直到变为-1时,不再满足while条件,循环退出。#100以内奇数的和(不包括100)
python求1到100的奇数和的方法:可以用while循环实现,在循环内部变量n不断自减,直到变为【-1】时,不再满足while条件,循环退出,代码为【for i in range(0,100):if i%2==1:sum += i;】。
总和:1+2+3+·+100=(1+100)* 50=5050
奇数和:1+3+5+·+99=(1+99)* 50 / 2=2500
偶数和:2+4+6+·+100=(2+100)*50 / 2=2550
python计算1~100的和,1~100奇数的和,1~100偶数的和,一条代码求1~100的和
1、计算1~100的数之和
1.1 for循环实现1~100的和
sum1 = 0 for i in range(1,101): sum1 = sum1 + i i += 1 print(f"1-100之间的和是:{sum1}")
1.2 while实现1~100的和
sum1 = 0 i = 1 while True: sum1 = sum1 + i if i == 100: break i += 1 print(sum1)
1.3、一条代码求1~100的和:使用sum函数
print(sum(range(1,101)))
1.4、计算1~100里面偶数之和
sum1 = 0 for i in range(1,101): if i % 2 == 0: sum1 = sum1 +i i += 1 print(f"1-100之间偶数的和是:{sum1}")
1.5、计算1~100里面奇数之和
sum1 = 0 for i in range(1,101): if i % 2 != 0: sum1 = sum1 +i i += 1 print(f"1-100之间奇数的和是:{sum1}")
2.如何在一个函数内部修改全局变量---利用 global 修改全局变量 # (译:阁楼bou)
a = 10 def aaa(): global a # 如果声明全局变量 会更改 所有 a 的值 a = 4 print(a) aaa() print(a) # 如果没有声明 代码从上往下执行 a=10,global声明后全局变量 a = 4
3.列出5个python标准库
import os 提供了不少于操作系统相关联的函数 import sys 通常用于命令行参数 import re 正则匹配 import math 数学运算 import datetime 处理日期时间
4.字典如何删除键和合并两个字典:del、pop和update
dict1 = {\'a\': 1, \'b\': 2, \'c\': 3}
dict2 = {\'aa\': 11, \'bb\': 22, \'cc\': 33}
# 两种删除
del dict1["b"]
dict1.pop("c")
print(f"del 和 pop 两种方法删除 b 和 c 后的字典为:{dict1}")
# 两种合并
# dict1.update(dict2)
# print(dict1)
dict3 = dict(dict1, **dict2)
print(dict3)
5、谈下python的GIL
GIL是python的全局解释器锁,同一进程中假如有多个线程运行,一个线程在运行python程序的时候会霸占python解释器
(加了一把锁即GIL),使该进程内的其他线程无法运行,等该线程运行完后其他线程才能运行。
如果线程运行过程中遇到耗时操作,则解释器锁解开,使其他线程运行。所以在多线程中,线程的运行仍是有先后顺序的,并不是同时进行。
多进程中因为每个进程都能被系统分配资源,相当于每个进程有了一个python解释器,所以多进程可以实现多个进程的同时运行,缺点是进程系统资源开销大
6、python实现列表去重的方法:先通过集合去重,在转列表
# 转换为集合数据类型; set(列表)方法 li = [11, 12, 13, 12, 15, 16, 13] a = set(li) c = list(a) print("值为{}\\n转列表类型为:{}".format(c, type(c))) # 字典的 fromkeys 方法实现; li = [1, 2, 3, 4, 1, 1, 2] a1 = {}.fromkeys(li) a1 = list(a1) print("值为{}\\n转列表类型为:{}".format(a1, type(a1))) li1 = [x for x in a1] # 遍历 print(f"遍历列表:{li1}")
7、fun(*args, **kwargs)中的 *args, **kwargs什么意思?
# *args (译:阿尔戈斯) 和 **kwargs(译:库尔格斯)主要用于函数定义。你可以将不定数量的参数传递给一个函数。 # 这里的不定的意思是:预先并不知道函数使用者会传递多少个参数给你,所以在这个场景下使用这两个关键字。 # *args是 用来发送一个非键值对的可变数量的参数列表给一个函数这里有个例子帮你理解这个概念: def demo(args_f, *args_v): print(args_f) for x in args_v: print(x) demo(\'a\',\'b\',\'c\',\'d\') # **kwargs 允许你将不定长度的键值对,作为参数传递给一个函数。
# 如果你想要在一个函数里处理带名字的参数,你应该使用**kwargs.这里有个例子帮你理解这个概念: def demo(**args_v): for k, v in args_v.items(): print(k, v) demo(name=\'njcx\')
8、python2和python3的range (100)的区别
# python2返回列表,python3返回迭代器,节约内存 print(range(100)) # 结果:range(0, 100)
9、一句话解释什么样的语言能够用装饰器?
- 函数可以作为参数传递的语言,可以使用装饰器
10.python内建数据类型有哪些
整型 int 整数 布尔型 bool true/false 字符串 str "abcd" 元祖 tuple (tuple) 列表 list [list] 字典 dict {dict}
11、简述面向对象中__new__ 和 __init__区别
- __init__ 是初始化方法,创建对象后,就立刻被默认调用,可接收参数
- __new__方法接受的参数虽然也是和__init__一样,但__init__是在类实例创建之后调用,而 __new__方法正是创建这个类实例的方法。
所以,__init__ 和 __new__ 最主要的区别在于:
1.__init__ 通常用于初始化一个新实例,控制这个初始化的过程,比如添加一些属性, 做一些额外的操作,发生在类实例被创建完以后。它是实例级别的方法。
2.__new__ 通常用于控制生成一个新实例的过程。它是类级别的方法。
https://www.cnblogs.com/pythonzhilian/p/12427309.html
12、简述with方法打开处理文件帮我我们做了什么?
打开文件在进行读写的时候可能会出现一些异常状况,如果按照常规的 f.open 写法
我们需要 try,except,finally,做异常判断,并且文件最终不管遇到什么情况
都要执行 finally f.close() 关闭文件
with 方法帮我们实现了 finally 中 f.close
(当然还有其他自定义功能,有兴趣可以研究with方法源码)
13、列表[1,2,3,4,5],请使用map()函数输出[1,4,9,16,25],并使用列表推导式提取出大于10的数,最终输出[16,25]
# map() 函数第一个参数是fun,第二个参数是-般是list, 第三个参数可以写list,也可以不写根据需求 list1 = [1, 2, 3, 4, 5] def fn(i): return i ** 2 res = map(fn, list1) res = [i for i in res if i > 10] print(res)
14、python中生成随机整数、随机小数、0--1之间小数方法
import random # (译:软的木) import numpy # (译:娜姆py) # 随机整数: random.randint(a,b),(译:软的木.软din特)生 成区间内的整数 a = random.randint(0, 10) print("随机正整数:", a) # 随机小数:习惯用 numpy 库,利用numpy.random.randn(5) (译:娜姆py.软的木.软的n)生成5个随机小数 b = numpy.random.randn(5) print("5个随机小数:", b) # 0-1随机小数: random.random(), (译:软的木.软的木)括号中不传参 c = random.random() print("0-1随机小数:", c) # 结果: # 随机正整数: 7 # 5个随机小数: [-0.13004373 -1.18237795 -0.60275202 0.30063551 -0.29836968] # 0-1随机小数: 0.7667893087661188
15、避免转义给字符串加哪个字母表示原始字符串?
- r,表示需要原始字符串,不转义特殊字符
16、<div class="nam">中国</div>,用正则匹配出标签里面的内容("中国"),其中class的类名是不确定的
import re # findall (译:法的奥) str1 = \'<div class="nam">中国</div>\' # .代表可有可无,*代表任意字符,满足类名可以变化;(.*?)提取文本 res = re.findall(r\'<div class=".*">(.*?)</div>\', str1) print(res) # 结果:[\'中国\']
17、python中断言方法举例
- assert ()方法,断言成功,则程序继续执行,断言失败,则程序报错
a = 3 assert (a > 1) print("断言成功,程序继续向下执行") b = 3 assert (b > 6) print("断言失败,程序报错")
18、数据表student有id,name,score,city字段,其中name中的名字可有重复,需要消除重复行,请写sql语句
select distinct name from student # distinct(抵死真可特)
19、10个Linux常用命令
Is pwd cd touch rm mkdir tree cp mv cat more grep echo
20、python2和python3区别? 列举5个
1、Python3 使用 print 必须要以小括号包裹打印内容,比如print(\'hi\')
Python2 既可以使用带小括号的方式,也可以使用一个空格来分隔打印内容,比如 print \'hi\'
2、python2 range(1,10)返回列表,python3中返回迭代器,节约内存
3、python2 中使用 ascii 编码,python3 中使用 utf-8 编码
4、python2 中 unicode 表示字符串序列,str 表示字节 序列
python3 中 str 表示字符串序列,byte 表示字节序列
5、python2 中为正常显示中文,引入 coding 声明,python3 中不需要
6、python2 中是 raw_input() 函数, python3 中是input()函数
21、列出python中可变数据类型和不可变数据类型,并简述原理
# 不可变数据类型:数值型、字符串型string和元组tuple # 不允许变量的值发生变化,如果改变了变量的值,相当于是新建了-一个对象,而对于相同 # 的值的对象,在内存中则只有一一个对象(- -个地址), 如下图用id()方法可以打印对象的id a = 3 b = 3 print(id(a)) print(id(b)) # 结果:8791318717328 # 8791318717328 # 可变数据类型:列表list和字典dict; # 允许变量的值发生变化,即如果对变量进行append、+= 等这种操作后,只是改变了变量的值,而不会新建一个对象, # 变量引用的对象的地址也不会变化,不过对于相同的值的不同对象,在内存中则会存在不同的对象, # 即每个对象都有自己的地址,相当于内存中对于同值的对象保存了多份,这里不存在引用计数,是实实在在的对象。 c = [1, 2] d = [1, 2] print(id(c)) print(id(d)) # 结果:5530248 # 5530312
22. s="ajldjlajfdljfddd", 去重并从小到大排序输出"adfjl"
# set去重,去重转成 list ,利用 sort 方法排序,reeverse= False 是从小到大排 # list是不变数据类型,s.sort时候没有返回值,所以注释的代码写法不正确 s = "ajldjlajfdljfddd" s = set(s) s = list(s) s.sort(reverse=False) # s = s.sort(reverse=False) res = "".join(s) print(res)
23、用 lambda 函数实现两个数相乘 (lambda译:兰木达),(sum译:萨姆)
sum = lambda a, b: a*b print(sum(3, 4))
24、字典根据键从小到大排序
dict1 = {"name": "zs ", "age": 18, "city": "深圳", "tel": " 1362626627"}
list = sorted(dict1.items(), key=lambda i: i[0], reverse=False)
print("sorted根据字典键排序\\n:{}".format(list))
new_dict = {}
for i in list:
new_dict[i[0]] = i[1]
print("新字典\\n:{}".format(new_dict))
# 结果:
# sorted根据字典键排序
# :[(\'age\', 18), (\'city\', \'深圳\'), (\'name\', \'zs \'), (\'tel\', \' 1362626627\')]
# 新字典
# :{\'age\': 18, \'city\': \'深圳\', \'name\': \'zs \', \'tel\': \' 1362626627\'}
25、利用 collections (译:克耐克深思)库的 Counter (译:康特)方法统计字符串每个单词出现的次数
"kjalfj;ldsjafl;hdsllfdhg;lahfbl;hI;ahlf;h"
from collections import Counter a = "kjalfj;ldsjafl;hdsllfdhg;lahfbl;hI;ahlf;h" res = Counter(a) print(res) # 结果: # Counter({\'l\': 8, \';\': 6, \'h\': 6, \'f\': 5, \'a\': 4, \'j\': 3, \'d\': 3, \'s\': 2, \'k\': 1, \'g\': 1, \'b\': 1, \'I\': 1})
26、字符串 a = "not 404 found 张三 99 深圳",每个词中间是空格,用正则过滤掉英文和数字,最终输出"张三 深圳"
import re a = "not 404 found 张三 99 深圳" list = a.split(" ") print(list) # 结果:[\'not\', \'404\', \'found\', \'张三\', \'99\', \'深圳\'] # res = re.findall(r\'\\d+|[a-zA-Z]+\', a) # \\d+:匹配数字,[a-zA-Z]+:匹配单词,|:链接多个匹配方式 # 顺便贴上匹配小数的代码,虽然能匹配,但是健壮性有待进一步确认 res = re.findall(r\'\\d+\\.?\\d*|[a-zA-Z]+\', a) for i in res: if i in list: list.remove(i) new_str = " ".join(list) print(res) # 结果:[\'not\', \'404\', \'found\', \'99\'] print(new_str) # 结果:张三 深圳
27. filter (译:fai欧特)方法求出列表所有奇数并构造新列表,a=[1,2,3,4,5,6,7,8,9,10]
# filter()函数用于过滤序列,过滤掉不符合条件的元素,返回由符合条件元素组成的新列表。 # 该接收两个参数,第一个为函数,第二个为序列,序列的每个元素作为参数传递给函数进行判, # 然后返回True或False,最后将返回True的元素放到新列表
a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] def fn(a): return a % 2 == 1 newlist = filter(fn, a) newlist = [i for i in newlist] print(newlist) # 结果:[1, 3, 5, 7, 9]
28、列表推导式求列表所有奇数并构造新列表,a = [1, 2, 3, 4,5, 6, 7, 8, 9, 10]
a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] res = [i for i in a if i % 2 == 1] print(res) # 结果:[1, 3, 5, 7, 9]
29、正则re.complie作用
re.compile (译:康排偶)是将正则表达式编译成一个对象,加快速度,并重复使用
30、 a= (1,) b=(1), c=("1")分别是什么类型的数据?
# 整型 int 整数 # 布尔型 bool true/false # 字符串 str "abcd" # 元祖 tuple (tuple) # 列表 list [list] # 字典 dict {dict} print(type(1)) # 结果:<class \'int\'> print(type(1, )) # 结果:<class \'int\'> print(type("1")) # 结果:<class \'str\'>
31、两个列表[1,5,7,9]和[2,2,6,8]合并为[1,2,2,3,6,7,8,9]
# extend 可以将另一个集合中的元素逐一添加到列表中,区别于 append 整体添加 a = [1, 5, 7, 9] b = [2, 2, 6, 8] a.extend(b) # 合并(译:伊克斯谈的) print(a) # 结果:[1, 5, 7, 9, 2, 2, 6, 8] a.sort(reverse=False) # 排序(译:速特) print(a) # 结果:[1, 2, 2, 5, 6, 7, 8, 9] a.append(b) # 结果:[1, 5, 7, 9, [2, 2, 6, 8]]
32、用 python 删除文件和用 linux 命令删除文件方法
python: os.remove(文件名) # (儒哎慕斯)
linux:rm 文件名
33、log日志中,我们需要用时间戳记录 error,warning 等的发生时间,
请用 datetime 模块打印当前时间戳 "2018-04-01 11:38:54" 顺便把星期的代码也贴上了
import datetime a = str(datetime.datetime.now().strftime(\'%Y-%m-%d %H:%M:%S\')) \\ + " 星期 " + str(datetime.datetime.now().isoweekday()) print(a) # 结果:2020-06-17 20:18:06 星期 3
34、数据库优化查询方法
- 外键、索引、联合查询、选择特定字段等等
35、请列出你会的任意一种统计图(条形图、折线图等)绘制的开源库,第三方也行
- pychart、matplotlib
36、写一段自定义异常代码
# 自定义异常用 raise 抛出异常 def fn(): try: for i in range(5): if i > 2: raise Exception("自定义异常用:数字大于2了") except Exception as ret: print(ret)
37、正则表达式匹配中,(.*) 和(.*?) 匹配区别?
# (.*)是贪婪匹配,会把满足正则的尽可能多的往后匹配 # (.*?) 是非贪婪匹配,会把满足正则的尽可能少匹配 import re s = "<a>哈哈</a><a>呵呵</a>" res1 = re.findall("<a>(.*)</a>", s) print("贪婪匹配", res1) # 结果:贪婪匹配 [\'哈哈</a><a>呵呵\'] res2 = re.findall("<a>(.*?)</a>", s) print("非贪婪匹配", res2) # 结果:非贪婪匹配 [\'哈哈\', \'呵呵\']
38、正则表达式匹配中,(.*) 和(.*?) 匹配区别?
- ORM,全拼Object-Relation Mapping,意为对象关系映射
- 实现了数据模型与数据库的解耦,通过简单的配置就可以轻松更换数据库,而不需要修改代码只需要面向对象编程,
- orm 操作本质上会根据对接的数据库引擎,翻译成对应的sq|语句,所有使用 Django 开发的项目无需关心程序底层使用的是MySQL、Oracle、sitit.....如果数据库迁移,只需要更换 Django 的数据库引擎即可
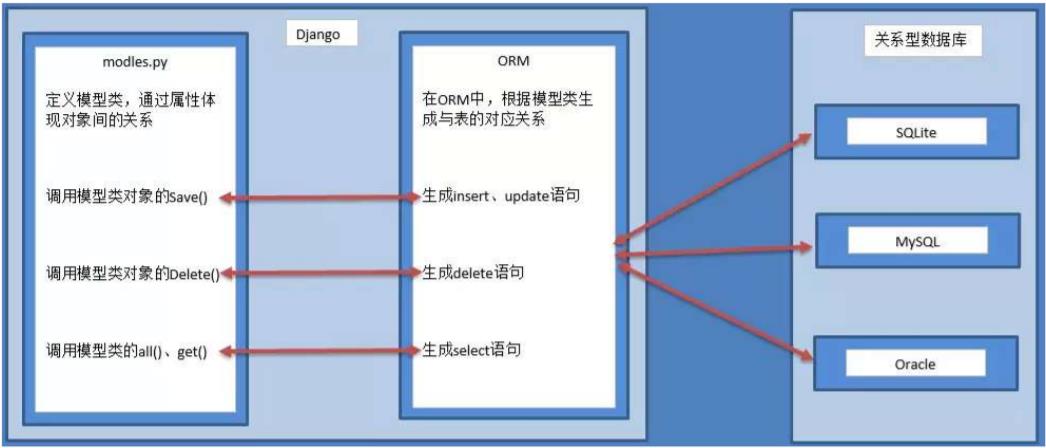
39、[[1,2],[3,4],[5,6]]一行代码展开该列表,得出[1,2,3,4,5,6]列表推导式的骚操作
# 运行过程: for i in a ,每个i是[1,2],[3,4] ,[5,6] ,for j in i,每个j就是1,2,3,4,5,6,合并后就是结果 a = [[1, 2], [3, 4], [5, 6]] x = [j for i in a for j in i] print(x) # 结果:[1, 2, 3, 4, 5, 6] # 还有更骚的方法,将列表转成numpy矩阵,通过numpy的flatten ()方法,代码永远是 import numpy b = numpy.array(a).flatten().tolist() print(b) # 结果:[1, 2, 3, 4, 5, 6]
40、x="abc",y="def" ,z=["d","e","f"],分别求出 x.join(y) 和 x.join(z)返回的结果
join()括号里面的是可迭代对象,x插入可迭代对象中间,形成字符串,结果一致,
有没有突然感觉字符串的常见操作都不会玩了
顺便建议大家学下os.path.join(方法,拼接路径经常用到,也用到了join,和字符串操作中的join有什么区别,该问题大家可以查阅相关文档,后期会有答案
x = "abc" y = "def" z = ["d", "e", "f"] m = x.join(y) n = x.join(z) print(m) # 结果:dabceabcf print(n) # 结果:dabceabcf
41、举例说明异常模块中try except else finally的相关意义
try..except..else没有捕获到异常,执行else语句
try..except..finally不管是否捕获到异常,都执行 finally 语句
42、Python 中交换两个数值
a, b = 3, 4 print(a, b) # 结果:dabceabcf a, b = b, a print(a, b) # 结果:dabceabcf
43、举例说明zip () 函数用法
zip()函数在运算时,会以- -个或多个序列(可迭代对象)做为参数,返回一个元组的列表。同时将这些序列中并排的元素配对。
zip()参数可以接受任何类型的序列,同时也可以有两个以上的参数;当传入参数的长度不同时,zip能自动以最短序列长度为准进行截取,获得元组。
44.a= "张明98分",用re.sub, 将98替换为100
import re a= "张明98分" ret = re.sub(r"\\d+", "100", a) print(ret)
45.写5条常用sq|语句
show databases; show tables; desc表名; select * from表名; delete from表名where id=5; update students set gender=0,hometown= "北京" where id=5
46、a="hello" 和 b= "你好" 编码成 bytes类型
a = "hello" b = "你好" print(a, b) print(type(a), type(b))
47、[1,2,3] + [4,5,6]的结果是多少?
两个列表相加,等价于 extend
a = [1, 2, 3] b = [4, 5, 6] res = a + b print(res) print(type(res)) # 结果: # hello 你好 # <class \'str\'> <class \'str\'> # [1, 2, 3, 4, 5, 6] # <class \'list\'>
48、提高 python 运行效率的方法
1、使用生成器,因为可以节约大量内存
2、循环代码优化,避免过多重复代码的执行
3、核心模块用Cython PyPy等, 提高效率
4、多进程、多线程、协程
5、多个 if elif 条件判断,可以把最有可能先发生的条件放到前面写,这样可以减少程序判断的次数,提高效率.
49、简述 mysql 和 redis 区别
redis:内存型非关系数据库, 数据保存在内存中,速度快
mysql:关系型数据库,数据保存在磁盘中,检索的话,会有一-定的Io操作,访问速度相对慢
50、遇到bug如何处理
1、细节上的错误,通过 print () 打印,能执行到 print () 说明一般,上面的代码没有问题,分段检测程序是否有问题,如果是 js 的话可以 alert 或 console.log
2、如果涉及- -些第三方框架,会去查官方文档或者- -些技术博客。
3、对于bug的管理与归类总结,- -般测试将测试出的bug用teambin等bug管理 工具进行记录,然后我们会一条一 条进行修改, 修改的过程也是理解业务逻辑和提高自己编程逻辑缜密性的方法,我也都会收藏做一些笔记记录。
4、导包问题、城市定位多音字造成的显示错误问题
51、正则匹配,匹配日期2018-03-20
urI=\'https://sycm.taobao.com/bda/tradinganaly/overview/get_ summary.json?dateRange=201 8-03-20%7C2018-03-20&dateType=recent1 &device= 1&token= ff25b109b&_ =1521595613462\'
仍有同学问正则,其实匹配并不难,提取一段特征语句,用(.*?) 匹配即可
import re url = \'https://sycm.taobao.com/bda/tradinganaly/overview/get_ summary.json?dateRange=201 8-03-20%7C2018-03-20&dateType=recent1 &device= 1&token= ff25b109b&_ =1521595613462\' result = re.findall(r\'dateRange=(.*?)%7C(.*?)&\', url) print(result) # 结果:[(\'201 8-03-20\', \'2018-03-20\')]
52、list = [2,3,5,4,9,6],从小到大排序,不许用sort,输出[2,3,4,5,6,9]
利用min()方法求出最小值,原列表删除最小值,新列表加入最小值,递归调用获取最小值的函数,反复操作
list = [2, 3, 5, 4, 9, 6] new_list = [] def get_min(list): # 获取列表最小值 a = min(list) # 删除最小值 list.remove(a) # 将最小值加入新的列表 new_list.append(a) # 保证最后列里面有值,递归调用获取最小值 # 直到所有值获取完,并加入新列表返回 if len(list) > 0: get_min(list) return new_list new_list = get_min(list) print(new_list)
53、写一个单列模式
因为创建对象时_ new_ 方法执行, 并且必须return返回实例化出来的对象所 cls.__ instance 是否存在, 不存在的话就创建对象,存在的话就返回该对象,来保证只有一个实例对象存在(单列),打印ID,值一样,说明对象同一个
class Singlenton(object): __instance = None def __new__(cls, *args, **kwargs): # 如果类属性_instance的值为None, # 那么就创建一个对象,并且赋值为这个对象的引用,保证下次调用这个方法时 # 能够知道之前已经创建过对象了,这样就保证了只有1个对象 if not cls.__instance: cls.__instance = object.__new__(cls) return cls.__instance a = Singlenton(18, "dongGe") b = Singlenton(8, "dongGe") print(id(a)) print(id(b)) a.age = 19 # 给a指向的对象添加一个属性 print(b.age) # 获取b指向的对象的age属性 # 结果 37021064 37021064 19
54、保留两位小数
题目本身只有a="%.03f"%1.3335,让计算a的结果,为了扩充保 留小数的思路,提供 round 方法(数值,保留位数)
a = "%.03f" % 1.3335 print(a, type(a)) b = round(float(a), 1) print(b) b = round(float(a), 2) print(b) A = zip(("a", "b", "c", "d", "e"), (1, 2, 3, 4, 5)) A0 = dict(A) print(A0) # 结果 1.333 <class \'str\'> 1.3 1.33 {\'a\': 1, \'b\': 2, \'c\': 3, \'d\': 4, \'e\': 5}
55、求三个方法打印结果
fn("one", 1)直接将键值对传给字典;
fn("two", 2)因为字典在内存中是可变数据类型,所以指向同一个地址,传了新的额参数后,会相当于给字典增加键值对
fn("three", 3, {})因为传了- -个新字典,所以不再是原先默认参数的字典
def fn(k, v, dic={}): dic[k] = v print(dic) fn("one", 1) fn("two", 2) fn("three", 3