mysql 与oracle中的存储过程及函数有啥区别,尽可能详细哦
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了mysql 与oracle中的存储过程及函数有啥区别,尽可能详细哦相关的知识,希望对你有一定的参考价值。
本质上没区别。只是函数有如:只能返回一个变量的限制。而存储过程可以返回多个。而函数是可以嵌入在sql中使用的,可以在select中调用,而存储过程不行。执行的本质都一样。函数限制比较多,比如不能用临时表,只能用表变量.还有一些函数都不可用等等.而存储过程的限制相对就比较少
由于我现在基本上是DBA的工作,因此平时也看一些数据库方面的书籍。但是我一直对存储过程和函数之间的区别掌握不透。我向来认为存储过程可以实现的操作,函数也一样可以实现。最近,刚好大学的老师给我们上SQL-Server的课程,我对这个问题的疑惑终于慢慢解开。今天晚上顺便看了些网上的资料,觉得以下分析比较合理:
1. 一般来说,存储过程实现的功能要复杂一点,而函数的实现的功能针对性比较强。
2. 对于存储过程来说可以返回参数,而函数只能返回值或者表对象。
3. 存储过程一般是作为一个独立的部分来执行,而函数可以作为查询语句的一个部分来调用,由于函数可以返回一个表对象,因此它可以在查询语句中位于FROM关键字的后面。
4. 当存储过程和函数被执行的时候,SQL Manager会到procedure cache中去取相应的查询语句,如果在procedure cache里没有相应的查询语句,SQL Manager就会对存储过程和函数进行编译。
Procedure cache中保存的是执行计划 (execution plan) ,当编译好之后就执行procedure cache中的execution plan,之后SQL SERVER会根据每个execution plan的实际情况来考虑是否要在cache中保存这个plan,评判的标准一个是这个execution plan可能被使用的频率;其次是生成这个plan的代价,也就是编译的耗时。保存在cache中的plan在下次执行时就不用再编译了。
存储过程和用户自定义函数具体的区别
存储过程
存储过程可以使得对数据库的管理、以及显示关于数据库及其用户信息的工作容易得多。存储过程是 SQL 语句和可选控制流语句的预编译集合,以一个名称存储并作为一个单元处理。存储过程存储在数据库内,可由应用程序通过一个调用执行,而且允许用户声明变量、有条件执行以及其它强大的编程功能。
存储过程可包含程序流、逻辑以及对数据库的查询。它们可以接受参数、输出参数、返回单个或多个结果集以及返回值。
可以出于任何使用 SQL 语句的目的来使用存储过程,它具有以下优点:
可以在单个存储过程中执行一系列 SQL 语句。
可以从自己的存储过程内引用其它存储过程,这可以简化一系列复杂语句。
存储过程在创建时即在服务器上进行编译,所以执行起来比单个 SQL 语句快。
用户定义函数
函数是由一个或多个 Transact-SQL 语句组成的子程序,可用于封装代码以便重新使用。Microsoft? SQL Server? 2000 并不将用户限制在定义为 Transact-SQL 语言一部分的内置函数上,而是允许用户创建自己的用户定义函数。
可使用 CREATE FUNCTION 语句创建、使用 ALTER FUNCTION 语句修改、以及使用 DROP FUNCTION 语句除去用户定义函数。每个完全合法的用户定义函数名 (database_name.owner_name.function_name) 必须唯一。
必须被授予 CREATE FUNCTION 权限才能创建、修改或除去用户定义函数。不是所有者的用户在 Transact-SQL 语句中使用某个函数之前,必须先给此用户授予该函数的适当权限。若要创建或更改在 CHECK 约束、DEFAULT 子句或计算列定义中引用用户定义函数的表,还必须具有函数的 REFERENCES 权限。
函数中的有效语句类型包括:
DECLARE 语句,该语句可用于定义函数局部的数据变量和游标。
为函数局部对象赋值,如使用 SET 给标量和表局部变量赋值。
游标操作,该操作引用在函数中声明、打开、关闭和释放的局部游标。不允许使用 FETCH 语句将数据返回到客户端。仅允许使用 FETCH 语句通过 INTO 子句给局部变量赋值。
控制流语句。
SELECT 语句,该语句包含带有表达式的选择列表,其中的表达式将值赋予函数的局部变量。
INSERT、UPDATE 和 DELETE 语句,这些语句修改函数的局部 table 变量。
EXECUTE 语句,该语句调用扩展存储过程。
在查询中指定的函数的实际执行次数在优化器生成的执行计划间可能不同。示例为 WHERE 子句中的子查询唤醒调用的函数。子查询及其函数执行的次数会因优化器选择的访问路径而异 参考技术A 问和比较笼统。除了存储过程和函数头部定义不同。可以使用的系统函数也不同。本回答被提问者采纳 参考技术B 自己去看手册把 参考技术C
一直以来,mysql 只有针对聚合函数的汇总类功能,比如MAX, AVG 等,没有从 SQL 层针对聚合类每组展开处理的功能。不过 MySQL 开放了 UDF 接口,可以用 C 来自己写UDF,这个就增加了功能行难度。
这种针对每组展开处理的功能就叫窗口函数,有的数据库叫分析函数。
在 MySQL 8.0 之前,我们想要得到这样的结果,就得用以下几种方法来实现:
1. session 变量
2. group_concat 函数组合
3. 自己写 store routines
接下来我们用经典的 学生/课程/成绩 来做窗口函数演示
准备
学生表
mysql> show create table student \\G*************************** 1. row *************************** Table: studentCreate Table: CREATE TABLE student ( sid int(10) unsigned NOT NULL, sname varchar(64) DEFAULT NULL, PRIMARY KEY (sid)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci1 row in set (0.00 sec)
课程表
mysql> show create table course\\G*************************** 1. row *************************** Table: courseCreate Table: CREATE TABLE `course` ( `cid` int(10) unsigned NOT NULL, `cname` varchar(64) DEFAULT NULL, PRIMARY KEY (`cid`)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci1 row in set (0.00 sec)
成绩表
mysql> show create table score\\G*************************** 1. row *************************** Table: scoreCreate Table: CREATE TABLE `score` ( `sid` int(10) unsigned NOT NULL, `cid` int(10) unsigned NOT NULL, `score` tinyint(3) unsigned DEFAULT NULL, PRIMARY KEY (`sid`,`cid`)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci1 row in set (0.00 sec)
测试数据
mysql> select * from student;
+-----------+--------------+
| sid | sname |
+-----------+--------------+
| 201910001 | 张三 |
| 201910002 | 李四 |
| 201910003 | 武松 |
| 201910004 | 潘金莲 |
| 201910005 | 菠菜 |
| 201910006 | 杨发财 |
| 201910007 | 欧阳修 |
| 201910008 | 郭靖 |
| 201910009 | 黄蓉 |
| 201910010 | 东方不败 |
+-----------+--------------+
10 rows in set (0.00 sec)
mysql> select * from score;;
+-----------+----------+-------+
| sid | cid | score |
+-----------+----------+-------+
| 201910001 | 20192001 | 50 |
| 201910001 | 20192002 | 88 |
| 201910001 | 20192003 | 54 |
| 201910001 | 20192004 | 43 |
| 201910001 | 20192005 | 89 |
| 201910002 | 20192001 | 79 |
| 201910002 | 20192002 | 97 |
| 201910002 | 20192003 | 82 |
| 201910002 | 20192004 | 85 |
| 201910002 | 20192005 | 80 |
| 201910003 | 20192001 | 48 |
| 201910003 | 20192002 | 98 |
| 201910003 | 20192003 | 47 |
| 201910003 | 20192004 | 41 |
| 201910003 | 20192005 | 34 |
| 201910004 | 20192001 | 81 |
| 201910004 | 20192002 | 69 |
| 201910004 | 20192003 | 67 |
| 201910004 | 20192004 | 99 |
| 201910004 | 20192005 | 61 |
| 201910005 | 20192001 | 40 |
| 201910005 | 20192002 | 52 |
| 201910005 | 20192003 | 39 |
| 201910005 | 20192004 | 74 |
| 201910005 | 20192005 | 86 |
| 201910006 | 20192001 | 42 |
| 201910006 | 20192002 | 52 |
| 201910006 | 20192003 | 36 |
| 201910006 | 20192004 | 58 |
| 201910006 | 20192005 | 84 |
| 201910007 | 20192001 | 79 |
| 201910007 | 20192002 | 43 |
| 201910007 | 20192003 | 79 |
| 201910007 | 20192004 | 98 |
| 201910007 | 20192005 | 88 |
| 201910008 | 20192001 | 45 |
| 201910008 | 20192002 | 65 |
| 201910008 | 20192003 | 90 |
| 201910008 | 20192004 | 89 |
| 201910008 | 20192005 | 74 |
| 201910009 | 20192001 | 73 |
| 201910009 | 20192002 | 42 |
| 201910009 | 20192003 | 95 |
| 201910009 | 20192004 | 46 |
| 201910009 | 20192005 | 45 |
| 201910010 | 20192001 | 58 |
| 201910010 | 20192002 | 52 |
| 201910010 | 20192003 | 55 |
| 201910010 | 20192004 | 87 |
| 201910010 | 20192005 | 36 |
+-----------+----------+-------+
50 rows in set (0.00 sec)
mysql> select * from course;
+----------+------------+
| cid | cname |
+----------+------------+
| 20192001 | mysql |
| 20192002 | oracle |
| 20192003 | postgresql |
| 20192004 | mongodb |
| 20192005 | dble |
+----------+------------+
5 rows in set (0.00 sec)
MySQL 8.0 之前
比如我们求成绩排名前三的学生排名,我来举个用 session 变量和 group_concat 函数来分别实现的例子:
session 变量方式
每组开始赋一个初始值序号和初始分组字段。
SELECT
b.cname,
a.sname,
c.score, c.ranking_score
FROM
student a,
course b,
(
SELECT
c.*,
IF(
@cid = c.cid,
@rn := @rn + 1,
@rn := 1
) AS ranking_score,
@cid := c.cid AS tmpcid
FROM
(
SELECT
*
FROM
score
ORDER BY cid,
score DESC
) c,
(
SELECT
@rn := 0 rn,
@cid := ''
) initialize_table
) c
WHERE a.sid = c.sid
AND b.cid = c.cid
AND c.ranking_score <= 3
ORDER BY b.cname,c.ranking_score;
+------------+-----------+-------+---------------+
| cname | sname | score | ranking_score |
+------------+-----------+-------+---------------+
| dble | 张三 | 89 | 1 |
| dble | 欧阳修 | 88 | 2 |
| dble | 菠菜 | 86 | 3 |
| mongodb | 潘金莲 | 99 | 1 |
| mongodb | 欧阳修 | 98 | 2 |
| mongodb | 郭靖 | 89 | 3 |
| mysql | 李四 | 100 | 1 |
| mysql | 潘金莲 | 81 | 2 |
| mysql | 欧阳修 | 79 | 3 |
| oracle | 武松 | 98 | 1 |
| oracle | 李四 | 97 | 2 |
| oracle | 张三 | 88 | 3 |
| postgresql | 黄蓉 | 95 | 1 |
| postgresql | 郭靖 | 90 | 2 |
| postgresql | 李四 | 82 | 3 |
+------------+-----------+-------+---------------+
15 rows in set, 5 warnings (0.01 sec)
group_concat 函数方式
利用 findinset 内置函数来返回下标作为序号使用。
SELECT
*
FROM
(
SELECT
b.cname,
a.sname,
c.score,
FIND_IN_SET(c.score, d.gp) score_ranking
FROM
student a,
course b,
score c,
(
SELECT
cid,
GROUP_CONCAT(
score
ORDER BY score DESC SEPARATOR ','
) gp
FROM
score
GROUP BY cid
ORDER BY score DESC
) d
WHERE a.sid = c.sid
AND b.cid = c.cid
AND c.cid = d.cid
ORDER BY d.cid,
score_ranking
) ytt
WHERE score_ranking <= 3;
+------------+-----------+-------+---------------+
| cname | sname | score | score_ranking |
+------------+-----------+-------+---------------+
| dble | 张三 | 89 | 1 |
| dble | 欧阳修 | 88 | 2 |
| dble | 菠菜 | 86 | 3 |
| mongodb | 潘金莲 | 99 | 1 |
| mongodb | 欧阳修 | 98 | 2 |
| mongodb | 郭靖 | 89 | 3 |
| mysql | 李四 | 100 | 1 |
| mysql | 潘金莲 | 81 | 2 |
| mysql | 欧阳修 | 79 | 3 |
| oracle | 武松 | 98 | 1 |
| oracle | 李四 | 97 | 2 |
| oracle | 张三 | 88 | 3 |
| postgresql | 黄蓉 | 95 | 1 |
| postgresql | 郭靖 | 90 | 2 |
| postgresql | 李四 | 82 | 3 |
+------------+-----------+-------+---------------+
15 rows in set (0.00 sec)
MySQL 8.0 窗口函数
MySQL 8.0 后提供了原生的窗口函数支持,语法和大多数数据库一样,比如还是之前的例子:
用 row_number() over () 直接来检索排名。
mysql>
SELECT
*
FROM
(
SELECT
b.cname,
a.sname,
c.score,
row_number() over (
PARTITION BY b.cname
ORDER BY c.score DESC
) score_rank
FROM
student AS a,
course AS b,
score AS c
WHERE a.sid = c.sid
AND b.cid = c.cid
) ytt
WHERE score_rank <= 3;
+------------+-----------+-------+------------+
| cname | sname | score | score_rank |
+------------+-----------+-------+------------+
| dble | 张三 | 89 | 1 |
| dble | 欧阳修 | 88 | 2 |
| dble | 菠菜 | 86 | 3 |
| mongodb | 潘金莲 | 99 | 1 |
| mongodb | 欧阳修 | 98 | 2 |
| mongodb | 郭靖 | 89 | 3 |
| mysql | 李四 | 100 | 1 |
| mysql | 潘金莲 | 81 | 2 |
| mysql | 欧阳修 | 79 | 3 |
| oracle | 武松 | 98 | 1 |
| oracle | 李四 | 97 | 2 |
| oracle | 张三 | 88 | 3 |
| postgresql | 黄蓉 | 95 | 1 |
| postgresql | 郭靖 | 90 | 2 |
| postgresql | 李四 | 82 | 3 |
+------------+-----------+-------+------------+
15 rows in set (0.00 sec)
那我们再找出课程 MySQL 和 DBLE 里不及格的倒数前两名学生名单。
mysql>
SELECT
*
FROM
(
SELECT
b.cname,
a.sname,
c.score,
row_number () over (
PARTITION BY b.cid
ORDER BY c.score ASC
) score_ranking
FROM
student AS a,
course AS b,
score AS c
WHERE a.sid = c.sid
AND b.cid = c.cid
AND b.cid IN (20192005, 20192001)
AND c.score < 60
) ytt
WHERE score_ranking < 3;
+-------+--------------+-------+---------------+
| cname | sname | score | score_ranking |
+-------+--------------+-------+---------------+
| mysql | 菠菜 | 40 | 1 |
| mysql | 杨发财 | 42 | 2 |
| dble | 武松 | 34 | 1 |
| dble | 东方不败 | 36 | 2 |
+-------+--------------+-------+---------------+
4 rows in set (0.00 sec)
到此为止,我们只是演示了row_number() over() 函数的使用方法,其他的函数有兴趣的朋友可以自己体验体验,方法都差不多。
Mysql中的函数
什么是函数
mysql中的函数与存储过程类似,都是一组SQL集;
与存储过程的区别
函数可以return值,存储过程不能直接return,但是有输出参数可以输出多个返回值;
函数可以嵌入到sql语句中使用,而存储过程不能;
函数一般用于实现较简单的有针对性的功能(如求绝对值、返回当前时间等),存储过程用于实现复杂的功能(如复杂的业务逻辑功能);
mysql自带函数
mysql本身已经实现了一些常见的函数,如数学函数、字符串函数、日期和时间函数等等,不一一列举,这里简单的使用下几个函数:
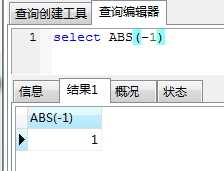
求绝对值ABS:
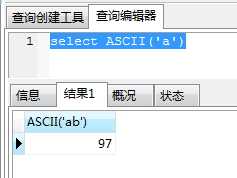
求ASCII:
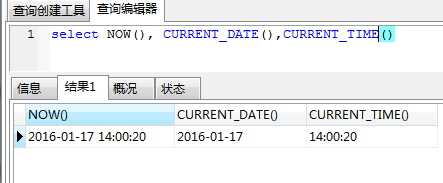
时间相关(NOW、CURRENT_DATE、CURRENT_TIME):
自定义函数
自定义个函数,判断输入参数是否大于等于10:

-- ----------------------------
-- Function structure for `func_compare`
-- ----------------------------
DROP FUNCTION IF EXISTS `func_compare`;
DELIMITER ;;
CREATE DEFINER=`root`@`localhost` FUNCTION `func_compare`(a int) RETURNS varchar(200) CHARSET utf8
BEGIN
#Routine body goes here...
IF a >= 10 THEN
RETURN ‘大于等于10‘;
ELSE
RETURN ‘小于10‘;
END IF;
END
;;
DELIMITER ;
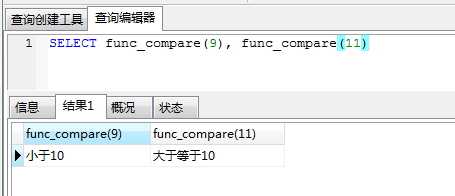
验证函数:
SELECT func_compare(9), func_compare(11)
执行结果:
以上是关于mysql 与oracle中的存储过程及函数有啥区别,尽可能详细哦的主要内容,如果未能解决你的问题,请参考以下文章