将数据存储在Amazon S3中可带来很多好处,包括规模、可靠性、成本效率等方面。最重要的是,你可以利用Amazon EMR中的Apache Spark,Hive和Presto之类的开源工具来处理和分析数据。 尽管这些工具功能强大,但是在处理需要进行增量数据处理以及记录级别插入,更新和删除场景时,仍然非常具有挑战。
与客户交谈时,我们发现有些场景需要处理对单条记录的增量更新,例如:
- 遵守数据隐私法规,在该法规中,用户选择忘记或更改应用程序对数据使用方式的协议。
- 使用流数据,当你必须要处理特定的数据插入和更新事件时。
- 实现变更数据捕获(CDC)架构来跟踪和提取企业数据仓库或运营数据存储中的数据库变更日志。
- 恢复迟到的数据,或分析特定时间点的数据。
从今天开始,EMR 5.28.0版包含Apache Hudi(孵化中),因此你不再需要构建自定义解决方案来执行记录级别的插入,更新和删除操作。Hudi是Uber于2016年开始开发,以解决摄取和ETL管道效率低下的问题。最近几个月,EMR团队与Apache Hudi社区紧密合作,提供了一些补丁,包括将Hudi更新为Spark 2.4.4,支持Spark Avro,增加了对AWS Glue Data Catalog的支持,以及多个缺陷修复。
使用Hudi,即可以在S3上执行记录级别的插入,更新和删除,从而使你能够遵守数据隐私法律、消费实时流、捕获更新的数据、恢复迟到的数据和以开放的、供应商无关的格式跟踪历史记录和回滚。 创建数据集和表,然后Hudi管理底层数据格式。Hudi使用Apache Parquet和Apache Avro进行数据存储,并内置集成Spark,Hive和Presto,使你能够使用与现在所使用的相同工具来查询Hudi数据集,并且几乎实时地访问新数据。
启动EMR群集时,只要选择以下组件之一(Hive,Spark,Presto),就可以自动安装和配置Hudi的库和工具。你可以使用Spark创建新的Hudi数据集,以及插入,更新和删除数据。每个Hudi数据集都会在集群的已配置元存储库(包括AWS Glue Data Catalog)中进行注册,并显示为可以通过Spark,Hive和Presto查询的表。
Hudi支持两种存储类型,这些存储类型定义了如何写入,索引和从S3读取数据:
-
写时复制(Copy On Write)– 数据以列格式(Parquet)存储,并且在写入时更新数据数据会创建新版本文件。此存储类型最适合用于读取繁重的工作负载,因为数据集的最新版本在高效的列式文件中始终可用。
-
读时合并(Merge On Read)– 将组合列(Parquet)格式和基于行(Avro)格式来存储数据; 更新记录至基于行的
增量文件中,并在以后进行压缩,以创建列式文件的新版本。 此存储类型最适合于繁重的写工作负载,因为新提交(commit)会以增量文件格式快速写入,但是要读取数据集,则需要将压缩的列文件与增量文件合并。
下面让我们快速预览下如何在EMR集群中设置和使用Hudi数据集。
结合Apache Hudi与Amazon EMR
从EMR控制台开始创建集群。在高级选项中,选择EMR版本5.28.0(第一个包括Hudi的版本)和以下应用程序:Spark,Hive和Tez。在硬件选项中,添加了3个任务节点,以确保有足够的能力运行Spark和Hive。
群集就绪后,使用在安全性选项中选择的密钥对,通过SSH进入主节点并访问Spark Shell。 使用以下命令来启动Spark Shell以将其与Hudi一起使用:
$ spark-shell --conf "spark.serializer=org.apache.spark.serializer.KryoSerializer"
--conf "spark.sql.hive.convertMetastoreParquet=false"
--jars /usr/lib/hudi/hudi-spark-bundle.jar,/usr/lib/spark/external/lib/spark-avro.jar
使用以下Scala代码将一些示例ELB日志导入写时复制存储类型的Hudi数据集中:
import org.apache.spark.sql.SaveMode
import org.apache.spark.sql.functions._
import org.apache.hudi.DataSourceWriteOptions
import org.apache.hudi.config.HoodieWriteConfig
import org.apache.hudi.hive.MultiPartKeysValueExtractor
//Set up various input values as variables
val inputDataPath = "s3://athena-examples-us-west-2/elb/parquet/year=2015/month=1/day=1/"
val hudiTableName = "elb_logs_hudi_cow"
val hudiTablePath = "s3://MY-BUCKET/PATH/" + hudiTableName
// Set up our Hudi Data Source Options
val hudiOptions = Map[String,String](
DataSourceWriteOptions.RECORDKEY_FIELD_OPT_KEY -> "request_ip",
DataSourceWriteOptions.PARTITIONPATH_FIELD_OPT_KEY -> "request_verb",
HoodieWriteConfig.TABLE_NAME -> hudiTableName,
DataSourceWriteOptions.OPERATION_OPT_KEY ->
DataSourceWriteOptions.INSERT_OPERATION_OPT_VAL,
DataSourceWriteOptions.PRECOMBINE_FIELD_OPT_KEY -> "request_timestamp",
DataSourceWriteOptions.HIVE_SYNC_ENABLED_OPT_KEY -> "true",
DataSourceWriteOptions.HIVE_TABLE_OPT_KEY -> hudiTableName,
DataSourceWriteOptions.HIVE_PARTITION_FIELDS_OPT_KEY -> "request_verb",
DataSourceWriteOptions.HIVE_ASSUME_DATE_PARTITION_OPT_KEY -> "false",
DataSourceWriteOptions.HIVE_PARTITION_EXTRACTOR_CLASS_OPT_KEY ->
classOf[MultiPartKeysValueExtractor].getName)
// Read data from S3 and create a DataFrame with Partition and Record Key
val inputDF = spark.read.format("parquet").load(inputDataPath)
// Write data into the Hudi dataset
inputDF.write
.format("org.apache.hudi")
.options(hudiOptions)
.mode(SaveMode.Overwrite)
.save(hudiTablePath)
在Spark Shell中,现在就可以计算Hudi数据集中的记录:
scala> inputDF2.count()
res1: Long = 10491958
在选项(options)中,使用了与为集群中的Hive Metastore集成,以便在默认数据库(default)中创建表。 通过这种方式,我可以使用Hive查询Hudi数据集中的数据:
hive> use default;
hive> select count(*) from elb_logs_hudi_cow;
...
OK
10491958
现在可以更新或删除数据集中的单条记录。 在Spark Shell中,设置了一些用来查询更新记录的变量,并准备用来选择要更改的列的值的SQL语句:
val requestIpToUpdate = "243.80.62.181"
val sqlStatement = s"SELECT elb_name FROM elb_logs_hudi_cow WHERE request_ip = \'$requestIpToUpdate\'"
执行SQL语句以查看列的当前值:
scala> spark.sql(sqlStatement).show()
+------------+
| elb_name|
+------------+
|elb_demo_003|
+------------+
然后,选择并更新记录:
// Create a DataFrame with a single record and update column value
val updateDF = inputDF.filter(col("request_ip") === requestIpToUpdate)
.withColumn("elb_name", lit("elb_demo_001"))
现在用一种类似于创建Hudi数据集的语法来更新它。 但是这次写入的DataFrame仅包含一条记录:
// Write the DataFrame as an update to existing Hudi dataset
updateDF.write
.format("org.apache.hudi")
.options(hudiOptions)
.option(DataSourceWriteOptions.OPERATION_OPT_KEY,
DataSourceWriteOptions.UPSERT_OPERATION_OPT_VAL)
.mode(SaveMode.Append)
.save(hudiTablePath)
在Spark Shell中,检查更新的结果:
scala> spark.sql(sqlStatement).show()
+------------+
| elb_name|
+------------+
|elb_demo_001|
+------------+
现在想删除相同的记录。要删除它,可在写选项中传入了EmptyHoodieRecordPayload有效负载:
// Write the DataFrame with an EmptyHoodieRecordPayload for deleting a record
updateDF.write
.format("org.apache.hudi")
.options(hudiOptions)
.option(DataSourceWriteOptions.OPERATION_OPT_KEY,
DataSourceWriteOptions.UPSERT_OPERATION_OPT_VAL)
.option(DataSourceWriteOptions.PAYLOAD_CLASS_OPT_KEY,
"org.apache.hudi.EmptyHoodieRecordPayload")
.mode(SaveMode.Append)
.save(hudiTablePath)
在Spark Shell中,可以看到该记录不再可用:
scala> spark.sql(sqlStatement).show()
+--------+
|elb_name|
+--------+
+--------+
Hudi是如何管理所有的更新和删除? 我们可以通过Hudi命令行界面(CLI)连接到数据集,便可以看到这些更改被解释为提交(commits):
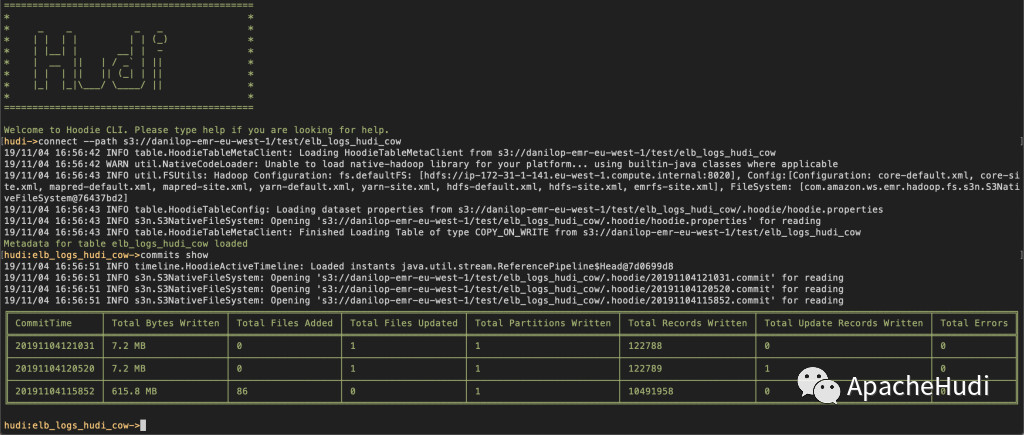
可以看到,此数据集是写时复制数据集,这意味着每次对记录进行更新时,包含该记录的文件将被重写以包含更新后的值。 你可以查看每次提交(commit)写入了多少记录。表格的底行描述了数据集的初始创建,上方是单条记录更新,顶部是单条记录删除。
使用Hudi,你可以回滚到每个提交。 例如,可以使用以下方法回滚删除操作:
hudi:elb_logs_hudi_cow->commit rollback --commit 20191104121031
在Spark Shell中,记录现在回退到更新之后的位置:
scala> spark.sql(sqlStatement).show()
+------------+
| elb_name|
+------------+
|elb_demo_001|
+------------+
写入时复制是默认存储类型。 通过将其添加到我们的hudiOptions中,我们可以重复上述步骤来创建和更新读时合并数据集类型:
DataSourceWriteOptions.STORAGE_TYPE_OPT_KEY -> "MERGE_ON_READ"
如果更新读时合并数据集并使用Hudi CLI查看提交(commit)时,则可以看到读时合并与写时复制相比有何不同。使用读时合并,你仅写入更新的行,而不像写时复制一样写入整个文件。这就是为什么读时合并对于需要更多写入或使用较少读取次数更新或删除繁重工作负载的用例很有帮助的原因。增量提交作为Avro记录(基于行的存储)写入磁盘,而压缩数据作为Parquet文件(列存储)写入。为避免创建过多的增量文件,Hudi会自动压缩数据集,以便使得读取尽可能地高效。
创建读时合并数据集时,将创建两个Hive表:
- 第一个表的名称与数据集的名称相同。
- 第二个表的名称后面附加了字符_rt; _rt后缀表示实时。
查询时,第一个表返回已压缩的数据,并不会显示最新的增量提交。使用此表可提供最佳性能,但会忽略最新数据。查询实时表会将压缩的数据与读取时的增量提交合并,因此该数据集称为读时合并。这将导致可以使用最新数据,但会导致性能开销,并且性能不如查询压缩数据。这样,数据工程师和分析人员可以灵活地在性能和数据新鲜度之间进行选择。
已可用
EMR 5.28.0的所有地区现在都可以使用此新功能。将Hudi与EMR结合使用无需额外费用。你可以在EMR文档中了解更多有关Hudi的信息。 这个新工具可以简化你在S3中处理,更新和删除数据的方式。也让我们知道你打算将其用于哪些场景!
