shell编程
Posted 疯子7314
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了shell编程相关的知识,希望对你有一定的参考价值。
shell编程入门简介
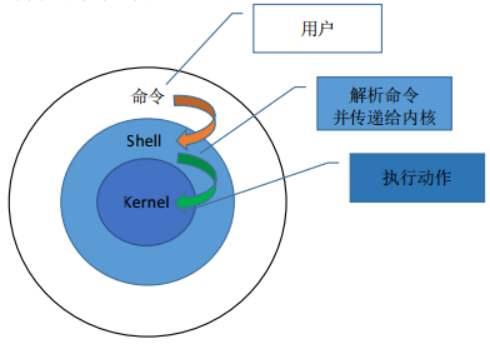
shell是用户与linux操作系统之间沟通的桥梁,用户可以输入命令执行,又可以利用shell脚本去运行
shell种类非常多,常见的shell如下:
- bourne shell(/usr/bin/sh或/bin/bash)
- bourne again shell(/bin/bash)
- C shell(/usr/bin/csh)
- K shell(/usr/bin/ksh)
不同的shell语言的语法有所不同,一般不能交换使用,最常用的shell是bash,也就是bourne agarn shell,bash由于易用和免费,在日常工作中被广泛使用,也是大多数linux操作系统默认的shell环境
shell脚本及Hello World
要熟练掌握shell语言需要大量的练习,初学者可以用shell打印 “Hello World”来增加仪式感!!!
shell编程脚本需要注意以下几点:
- shell脚本名称命名一般为英文;
- 不能使用特殊符号,空格来命名
- shell脚本要以.sh后缀
- 不建议shell命名为纯数字,一般以脚本功能命名
- shell脚本首写最好#!/bin/bash开头;
以下为第一个脚本:
[root@localhost ~]# vim a.sh #!/bin/bash echo "Hello World"
变量
shell为弱类型语言,定义变量不需要声明变量类型,可以直接用=来进行赋值,在定义变量时候有3中引用方式反引号(``),双引号(“”),单引号(‘’)
反引号:把命令的返回结果赋值给一个变量,如:
[root@localhost ~]# res=`df -h` [root@localhost ~]# echo $res 文件系统 容量 已用 可用 已用% 挂载点 /dev/mapper/centos-root 50G 2.7G 48G 6% / devtmpfs 475M 0 475M 0% /dev tmpfs 487M 0 487M 0% /dev/shm tmpfs 487M 7.7M 479M 2% /run tmpfs 487M 0 487M 0% /sys/fs/cgroup /dev/sda1 1014M 133M 882M 14% /boot /dev/mapper/centos-home 67G 33M 67G 1% /home tmpfs 98M 0 98M 0% /run/user/0
双引号:可以识别变量,如
[root@localhost ~]# name=liwang [root@localhost ~]# echo "my name is $name" my name is liwang
单引号:单引号里面的内容都当做字符创来引用,如:
[root@localhost ~]# name=liwang [root@localhost ~]# echo \'my name is $name\' my name is $name [root@localhost ~]# echo $name liwang
如果在使用时需要明确变量的类型,可以使用declare指定类型,declare常见参数如下:
-f:仅显示函数 -r:将变量定义为只读 -x:指定的变量会成为环境变量,可供shell以外的程序调用 -i:指定类型为数值,字符串或运算
小案例1:定义字符串
引用变量时一定要加$
[root@localhost ~]# vim b.sh #!/bin/bash a=1000 echo $a
小案例2:定义整数
[root@localhost ~]# cat a.sh #!/bin/bash declare -i a=10 declare -i b=20 res=`expr $a + $b` echo $res 也可以 [root@localhost ~]# cat a.sh #!/bin/bash a=10 b=20 echo $(($a+$b))
shell变量类型
shell变量的3种类型
- 系统变量
- 环境变量
- 用户变量
(1)shell常见的系统变量:
- $0:当前脚本的名称
- $n:当前脚本的第n个参数,n=1,2,3....
- $*:当前脚本的所有参数(不包括程序本身)
- $#:当前脚本参数的个数(不包括脚本本身)
- $?:上一条命令的执行状态,0代表ok,非0代表不成功
- $$:代表程序本身的PID
案例如下:
[root@localhost ~]# vim test.sh #!/bin/bash #程序本身 echo -e "\\033[32m-----------------------------\\033[0m" echo -e "\\033[36mPlease Select Install Menu:\\033[0m" echo echo "1)官方下载Httpd文件包" echo "2)解压apache源码包" echo "3)编译安装Httpd服务器" echo "4)启动HTTPD服务器" echo -e "\\033[32m-----------------------------\\033[0m" echo $1 $2 $3 #查看各类$的含义 echo "当前脚本名称:$0" echo "当前脚本的所有参数:$*" echo "当前脚本参数的个数:$#" echo "命令的执行状态:$?" echo "程序本身的PID:$$" #执行结果 [root@localhost ~]# bash test.sh a b c ----------------------------- Please Select Install Menu: 1)官方下载Httpd文件包 2)解压apache源码包 3)编译安装Httpd服务器 4)启动HTTPD服务器 ----------------------------- a b c 当前脚本名称:test.sh 当前脚本的所有参数:a b c 当前脚本参数的个数:3 命令的执行状态:0 程序本身的PID:8933
(2)shell常见的环境变量:
- PATH:命令所示路径,以冒号为分割;
- HOME:打印用户家目录
- SHELL:显示当前shell类型
- USER:打印当前用户名
- ID:打印当前用户ID信息
- PWD:打印当前所在路径
- TERM:打印当前终端类型
- HOSTNAME:显示当前主机名
(3)shell用户变量如下:
- NAME=liwang
- IP1=192.168.1.1
- IP2=192.168.1.100
创建echo打印菜单shell脚本,代码如下:
[root@localhost ~]# vim test.sh #!/bin/bash echo -e "\\033[32m-----------------------------\\033[0m" echo -e "\\033[36mPlease Select Install Menu:\\033[0m" echo echo "1)官方下载Httpd文件包" echo "2)解压apache源码包" echo "3)编译安装Httpd服务器" echo "4)启动HTTPD服务器" echo -e "\\033[32m-----------------------------\\033[0m" sleep 20 [root@localhost ~]# bash test.sh ----------------------------- Please Select Install Menu: 1)官方下载Httpd文件包 2)解压apache源码包 3)编译安装Httpd服务器 4)启动HTTPD服务器 -----------------------------
if语句
if条件判断语句,通常以if开头,fi结尾,也可以加入else或者elif进行多条件的判断,if表达式如下
if ((条件表达式));then 语句1 else 语句2 fi
if常见的判断逻辑运算符详解如下:
[ -f FILE ] 如果 FILE 存在且是一个普通文件则为真。 [ -d DIR ] 如果 DIR 存在且是一个目录则为真。 [ CONDITION1 -a CONDITION2 ]双方都成立 [ CONDITION1 -o CONDITION2 ]单方成立 [ -z $VAR ]空字符串 || 单方成立 && 双方都成立表达式 [ INT1 -eq INT2 ]等于,应用于整型比较 [ INT1 -ne INT2 ]不等于,应用于整型比较 [ INT1 -lt INT2 ]小于,应用于整型比较 [ INT1 -gt INT2 ]大于,应用于整型比较 [ INT1 -le INT2 ]小于或等于,应用于整型比较 [ INT1 -ge INT2 ]大于或等于,应用于整型比较
if判断括号区别
():用于多个命令组,命令替换,初始化数组 (()):整数扩展,运算符,冲定义变量值,算数比较运算 []:bash内部命令,不支持+,-,*,/数学运算符,逻辑测试使用-a -o [[]]:bash程序语言关键字,不支持+,-,*,/数学运算符,逻辑测试使用&& || {}:主要用于命令集合或者范围,例如:mkdir -p /data/201{7,8}
案例:
[root@localhost ~]# vim a.sh #!/bin/bash declare -i num=100 if [ $1 -gt $num ];then echo "enter number is too big" elif [ $1 -eq $num ];then echo "bingo" else echo "enter number is too small" fi
for语句
for循环语句主要用于对某个数据域进行循环读取,对文件进行遍历,通常用于循环某个文件或者列表,其语法格式以for...do开头,done结尾,语法格式如下:
for var in 表达式 do 语句1 done 列表生成方式: (1)整数列表 (start..end) $(seq start [step] end) $(cat test.sh)
案例1:循环出BAT网站如下:
[root@localhost ~]# vim b.sh #!/bin/bash for addr in www.baidu.com www.taobao.com www.qq.com do echo $addr done
案例2:计算1到100的总和
[root@localhost ~]# cat c.sh #!/bin/bash declare -i sum=0 for ((i=1;i<=100;i++)) do sum+=$i done echo $sum
案例3:循环打包查找出来的文件
[root@localhost test]# cat d.sh #!/bin/bash for i in `find ./ -name "*.txt"` do tar -cvf $i.tar $i done
while循环
while循环语句跟for循环类似,主要用于对某个数据域进行循环读取,对文件进行遍历,通常用于循环某个文件或者列表,满足条件会一直循环,不满足则退出循环,其语法格式为while...do开头,done结尾,语法格式为:
while CONDITION; do 循环体 done CONDITION 循环控制条件,进入循环之前,先做一次判断,每一次循环之后会再做判断 条件为true,则执行一次循环,知道条件测试状态为false循环终止 因此:CONDITION一般应该有循环控制变量,而此变量的值会在循环体不断的被修正 while的特殊用法(遍历文件的每一行): [root@fengzi ~]# while read line;do echo $line; done</root/a.txt
练习
1.添加10个用户
2.通过ping命令探测192.168.254.1-10范围内所有主机的在线状态
3.查找/root/test中所有以.txt后缀的文件的后缀加上.bak
4.编写脚本,把/root/目录下的所有目录复制到/tmp/目录;
答案
1题


[root@localhost ~]# vim b.sh #!/bin/bash for i in {1..10} do useradd user$i && echo "user$i" | passwd --stdin root done
2题
[root@localhost ~]# vim b.sh done #!/bin/bash declare -i uphosts=0 declare -i downhosts=0 for i in {1..10} do ping -c 1 -w 1 192.168.254.$i &>/dev/null if [ $? -eq 0 ];then echo "192.168.254.$i is up" let uphosts++ else echo "192.168.254.$i is down" let downhosts++ fi done echo "up is $uphosts" echo "down is $downhosts"
3题
#!/bin/bash for i in `find ./ -name "*.txt"` do mv $i $i.bak done
4题
[root@localhost test]# for i in `ls`;do [ -d $i ] && cp -a $i /tmp; done
read语句
read可以交互式接收值,例如输入名字liwang,把liwang这个名字在赋予给变量name,如下:
[root@localhost test]# read -p "please enter your name?:" name;echo $name please enter your name?:liwang liwang
case语句
case选择语句主要用于对多个选择条件进行匹配输出,与if...elif语句结构类似,通常用于脚本传递输入参数,打印输出结果及内容,其语法格式以case...in开头,esac结尾,
语法格式如下:
case语句: case 变量引用 in: PART1) 分支1 ;; PART2) 分支2 ;; PATH3) 分支3 ;; *) 分支4 ;; esac
案例:
[root@fengzi ~]# cat test.sh #!/bin/bash cat << EOF please choose this cpu) show cpu information mem) show mem information disk) show disk information ============================= EOF read -p "please choose:" choose case $choose in cpu) vmstat | awk \'NR==3 {print $15}\' ;; mem) free -m ;; disk) df -h ;; *) enter wrong!! ;; esac
select语句
select语句一般用于选择,常用语选择菜单的创建,语法格式为select...in do开头,done结尾
语法格式如下:
select i in 表达式 do 语句 done
案例1:选择操作系统
[root@localhost test]# vim d.sh #!/bin/bash echo "please choose your OS:" select i in CentOS RedHat SUSE do echo "you choose OS is $i" break done
案例2:case和select结合使用
#!/bin/bash echo "please choose php mysql httpd quit" select i in php mysql httpd quit do case $i in php) echo "you choose is $i" ;; mysql) echo "you choose is $i" ;; httpd) echo "you choose is $i" ;; quit) break ;; esac done
shell函数编程
shell允许将一组命令集火语句形成一个可用块,这些块称之为shell函数,shell函数的好处在于只需要定义一次,后期随时调用,无需在shell脚本中添加重复的代码,其语法格式为function () {开头 }结尾,也可以function NAME(){}来定义。
例如:
[root@mynode1 data]# cat test.sh #!/bin/bash adduser () { if [ $# -lt 1 ];then echo "参数个数为:$#" else if id $1 &>/dev/null;then echo "user is exists!" else useradd $1 echo "create $1 successfully!!" fi fi }
adduser $1
locate命令
locate命令是一个非实时查找(数据库查找)的命令,依赖于事先构建的索引:索引的构建是在系统较为空闲时自动进行(周期性进行),手动更新数据(updatedb)
索引构建过程需要遍历整个跟文件系统,极其消耗资源
工作特点:
- 查找速度快
- 模糊查找
- 非实时查找
示例:
[root@mynode1 usr]# locate 11.txt /etc/pki/nssdb/pkcs11.txt /usr/local/python3.6/lib/python3.6/test/test_email/data/msg_11.txt /usr/share/doc/git-1.8.3.1/RelNotes/1.7.11.txt /usr/share/man/man5/pkcs11.txt.5.gz /usr/share/vim/vim74/doc/gui_x11.txt.gz /usr/share/vim/vim74/doc/usr_11.txt.gz
shell编程四剑客
find、sed、grep、awk
find命令
find命令主要用于实时查找操作系统文件,目录的查找,
工作特点:
- 工作速度略慢
- 精确查找
- 实时查找
语法格式:
- find [OPTION]... [查找路径] [查找条件] [处理动作]
- 查找路径:指定具体目标路径:默认为当前目录
- 查找条件:指定的查找标准:可以是文件名,大小,类型,权限等标准进行,默认为指定路径下的所有文件
- 处理动作:对符合条件的文件做什么操作:默认输出至屏幕
条件查找
查找深度
-maxdepth #
根据文件名查找:
-name:\'文件名称\' *,?,[],[^] -iname \'文件名称\', 不区分大小写
根据属主,属组查找:
-user: USERNAME:查找属主为指定用户的文件 -group: GROUP:查找属组为指定组的文件 -uid UserID:查找属主为指定的UID号的文件 -gid GroupID:查找属组为指定的GID号的文件
-nouser:查找没有属主的文件
-nogroup:查找没有属组的文件
根据文件类型查找:
-type TYPE:
f:普通文件
d:目录文件
l:符号链接文件
s:套接字文件
b:块设备文件
c:字符设备文件
p:管道文件
组合条件:
与: -a 或: -o 非: -not,!
根据文件大小来查找:
-size[+|-] #UNIT 常用单位:k,M,G #UNIT:(#-1,#] -#UNIT:[0,#-1] +#UNIT:(#,∞)
根据时间戳:
以"天"为单位 -atime [/|-] #:[#,#+1] #天,不到#+1天内的文件 +#: [#+1,∞] #+1天以前的文件 -#: [0,#) #天内访问的文件 -mtime -ctime mtime ls -l 显示最近修改文件内容的时间 atime ls -lu 显示最近访问文件的时间 ctime ls -li 显示最近文件有所改变的状态,如文件修改,属性\\属主改变,节点,链接变化等 以"分钟"为单位: -amin -mmin -cmin
根据权限查找:
-perm[+|-]MODE
MODE: 精确权限匹配-MODE:每一类对象必须同时拥有为其制定的权限标准
处理动作
-print:默认的处理动作,显示到屏幕 -ls:类似于对查找的文件执行“ls -l”命令 -delete: 删除查找到的文件: -fls /path/to/somefile:查找到的所有文件的长格式信息保存至文件中 -ok COMMAND {} \\; 对查找到的每个文件执行有COMMAND指定的命令 对于每个文件执行命令之前,都会交互式要求用户确认 -exec COMMAND {} \\;对查找到的每个文件执行由COMMAND指定的命令 注意:find传递查找到的文件至后面指定的命令时,查找到所有符合条件的文件一次性传递给后面的命令,有些命令不能接受过多的参数,此时命令执行可能会失效
练习
1.查找/var目录下属主为root,且属组为mail的所有文件或者是目录
2.查找/usr目录下不属于root、bin或者hadoop的所有文件或目录
3.查找/etc目录下最近一周其内容修改过,同时属主不为root,也不是hadoop的文件或者目录
4.查找当前系统上没有属主或者属组,且最近一周内曾被访问过的文件或者目录
5.查找/etc目录下大于1M且类型为普通文件的所有文件
6.查找/etc目录下所有用户没有写权限的文件
7.查找/etc目录下至少有一类用户没有执行权限的文件
答案1.find /var -user root -group mail
2.find /usr \\( ! -user root -o -user bin -o ! -user hadoop \\) -ls
3.find /etc \\( -mtime -7 -a ! -user root -a -user hadoop \\) -ls
4.find / \\( -nouser -a -nogroup -a mtime -7 \\)
5.find /etc \\( -size +1M -type f \\) -exec ls -ltr {} \\;
6.find /etc -perm +775 -type f -exec ls -ltr {} \\;
7.find /etc ! -perm -111
shell脚本搭建yum本地仓库脚本
[root@localhost ~]# cat yum.sh #!/bin/bash mount /dev/cdrom /mnt/ &>/dev/null mkdir -p /root/myrepo/ if [ $? -eq 0 ];then cp -a /mnt/Packages/* /root/myrepo/ &>/dev/null else cp -a /mnt/Packages/* /root/myrepo/ &>/dev/null fi cd /root/myrepo/ createrepo ./ if (($?!=0));then yum install createrepo -y &>/dev/null createrepo ./ fi mkdir -p /tmp/old if [ $? -eq 0 ];then mv /etc/yum.repos.d/* /tmp/old &>/dev/null else mv /etc/yum.repos.d/* /tmp/old &>/dev/null fi cat>/etc/yum.repos.d/my.repo <<EOF [myself] name=myself baseurl=file:///root/myrepo gpgcheck=0 enabled=1 EOF yum clean all && yum makecache if [ $? -eq 0 ];then echo "yum server is ok!!" else echo "yum server is error!!" fi
sed
sed是一个非交互式文本编辑器,它可以对文本文件和标准输入进行编辑,标准输入可以来自键盘输入,文本重定向,字符串,变量来自于管道的文本,与vim编辑器相似,它一次处理一行内容,sed可以编辑一个或多个文件,简化对文件的反复操作
在处理文本时把当前处理的行存储在临时缓冲区,称之为“模式空间”,紧接着用sed处理缓冲区中的内容,处理完成之后把缓冲区的内容输出至屏幕或者写入文件,逐行处理知道末尾,然而要打印在屏幕上,实质文件内容并没有改变,除非用户使用重定向存储输出或写入文件,其语法格式为:
sed [OPTION]... {script-only-if-no-other-script} [input-file]...
常用选项:
-n:不输出模式中的内容至屏幕 -e:多点编辑
-i:原处编辑
地址定界:
(1)不给地址:对全文进行处理 (2)单地址 #:指定的行 /pattern/:被此处模式所能匹配到的每一行
编辑命令:
d:删除 p:显示模式空间中的内容 a \\text:在行后面追加文本,支持使用\\n实现多行追加; i \\text:在行前面插入文本, 支持使用\\n实现多行插入 c \\text:替换行为单行或多行文本 w /path/to/somefile: 保存模式空间中的内容至指定文件中 =:为模式空间中的行打印行号 !:取反条件
awk命令
awk是一个优良的文本处理工具,Linux及UNIX环境中现有的功能最强大的数据处理引擎之一,以Aho、Weinberger、Kernighan三位发明者名字首字母命名为awk,awk是一个行级文本高效处理工具,awk的原理是逐行处理文件中的数据,查找与命令行中所给定内容相匹配的模式,如果发现匹配内容,则进行下一个编程步骤,如果找不到匹配内容,则继续处理下一行
awk常用参数、变量详解如下:
语法格式为:
- awk \'pattern + {action}\' file
awk基本语法参数详解如下:
- 单行号 \'\' 是为了和shell命令区分开
- 大括号{}表示一个命令分组
- pattern是一个过滤器,表示匹配pattern条件的行才进行action处理
- action是处理动作,常见动作为print
awk内置变量详解如下:
- F:分隔符,默认是空格
- OFS:输出分隔符
- RS:输入记录分隔符(输入换行符), 指定输入时的换行符
- ORS:输出记录分隔符(输出换行符),输出时用指定符号代替换行符
- NR:当前行数,从1开始
- NF:当前记录字段个数
- $0:当前记录
- $1~$n:当前记录第n个字段
1.awk打印硬盘设备名称,默认以空格分隔,代码如下:
[root@localhost ~]# df -h | awk \'{print $1}\' 文件系统 /dev/mapper/centos-root devtmpfs tmpfs tmpfs tmpfs /dev/sda1 /dev/mapper/centos-home tmpfs
2.awk以空格、/、%分隔,代码如下
[root@localhost ~]# df -h | awk -F \'[ /%]\' \'{print $1}\' 文件系统 devtmpfs tmpfs tmpfs tmpfs tmpfs
3.awk以空格分隔,打印第一列,同时将内容追加到/tmp/awk.log中,代码如下:
[root@localhost ~]# df -h | awk \'{print $1 > "/tmp/awk.log"}\'
4.打印df -h,显示第三行和第五行,NR表示打印行,$0表示所有文本域,代码如下:
[root@localhost ~]# df -h | awk \'NR==3;NR==5 {print}\' [root@localhost ~]# df -h | awk \'NR==3;NR==5 {print $0}\'
note:如果想打印3到5行的话用:
df -h | awk \'NR==3,NR==5 {print $0}\'
5.查看/etc/passwd文件,以:分隔,打印第一列,并且只显示前5行
[root@localhost ~]# head -5 /etc/passwd | awk -F: \'{print $1}\' [root@localhost ~]# awk \'NR>=1&&NR<=5 {print $1}\' /etc/passwd
6.查看/etc/passwd文件,以:分割,打印第五行的第一列
[root@localhost ~]# cat passwd | awk -F: \'{if(NR==5)print $1}\' lp
7.打印偶数行信息
cat passwd | awk -F: \'{if((NR%2==0))print}\'
8.OFS格式化输出,冒号分割的地方替换成---
[root@localhost ~]# cat passwd | awk -F: \'{if((NR%2==0))print $1,$2,$3,$4}\' OFS="---" bin---x---1---1 adm---x---3---4 sync---x---5---0 halt---x---7---0 operator---x---11---0 ftp---x---14---50 systemd-network---x---192---192 polkitd---x---999---998 postfix---x---89---89 mysql---x---997---995 apache---x---48---48 lichen---x---1001---1001 bbbbbbb--------- bb--------- bbbb--------- rooa---------
9.RS用法
[root@liwang ~]# echo "1a2a3a4a5a" | awk \'BEGIN{RS="a"}{print$0}\' 1 2 3 4 5 [root@liwang ~]# echo \'1ab2bc3cd4de5\' | awk \'BEGIN{RS="[a-z]+"}{print $0}\' 1 2 3 4 5
grep
全面搜索正则表达式,grep是一种强大的文本搜索工具,他能够使用正则表达式搜索文本,并把匹配的行打印出来
grep常用参数如下:
- -c:计算找打的符合行的次数
- -i:忽略大小写
- -n:顺便输出行号
- -v:反向选择,即显示不包含匹配文本的所有行
- -E:允许使用egrep扩展模式匹配
通配符类型详解如下:
- *:0个或多个字符数字
- ?:匹配任意一个字符
- #:表示注释
- |:管道符
- ;:多个命令连续执行
- &:后台运行
- !:逻辑运算非
- []:内容范围,匹配括号中的内容
- {}:命令块,多个命令匹配
正则表达式如下:
- *:前一个字符匹配0次或多次
- .:匹配除了换行符以外的任意一个字符
- .*:代表任意字符
- ^:匹配行首,即以某个字符开头
- $:匹配行位,即某个字符结尾
- \\(...\\):标记匹配符
- []:匹配中括号里的任意字符,但只匹配一个字符
- [^]:匹配除中括号以外的任意一个字符
- \\:转译符,取消特殊含义
- {n}:匹配字符出现n次
- {n,}:匹配字符出现大于等于n次
- {n,m}:匹配字符至少出现n次,最多出现m次
- \\w:匹配文字和数字字符
- \\s:匹配任何空白字符
- \\d:匹配一个数字字符,等价于[0-9]
1.匹配/etc/passwd文件中出现root字符的总行数
[root@localhost ~]# grep -c \'root\' /etc/passwd 2
2.不区分大小写查找ROOT所有行
[root@localhost ~]# grep -i \'ROOT\' /etc/passwd以上是关于shell编程的主要内容,如果未能解决你的问题,请参考以下文章