解析IBM x3850 RAID5服务器故障恢复方案
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了解析IBM x3850 RAID5服务器故障恢复方案相关的知识,希望对你有一定的参考价值。
【基本信息】
服务器型号:IBM X3850服务器,
硬盘型号:73G SAS硬盘,
硬盘数量:5块硬盘 其中4块组成一个RAID5,另一块做为热备盘(Hot-Spare),
操作系统:linux redhat 5.3,应用系统为构架于oracle的一个oa。
【故障表现】
3号盘早已经离线,但热备盘未自动激活rebuild(原因不明),之后2号盘离线,RAID崩溃。
oracle已经不再对本oa系统提供后续支持,用户要求尽可能数据恢复+操作系统复原。
【初检结论】
热备盘完全无启用,硬盘无明显物理故障,无明显同步表现。数据通常可恢复。
【恢复方案】
1、保护原环境,关闭服务器,确保在恢复过程中不再开启服务器。
2、把故障硬盘编号排序,用以确保硬盘取出槽位后可以完全复原。
3、将故障硬盘挂载至只读环境,对所有故障硬盘做完全镜像(参考<如何对磁盘做完整的全盘镜像备份>)。备份完成后交回原故障盘,之后的恢复操作直到数据确认无误前不再涉及原故障盘。
4、对备份盘进行RAID结构分析,得到其原来的RAID级别,条带规则,条带大小,校验方向,META区域等。
5、根据得到的RAID信息搭建一组虚拟的RAID5环境。
6、进行虚拟磁盘及文件系统解释。
7、检测虚拟结构是否正确,如不正确,重复4-7过程。
8、确定数据无误后,按用户要求回迁数据。如果仍然使用原盘,需确定已经完全对原盘做过备份后,重建RAID,再做回迁。回迁操作系统时,可以使用linux livecd或win pe(通常不支持)等进行,也可以在故障服务器上用另外硬盘安装一个回迁用的操作系统,再进行扇区级别的回迁。
9、数据移交后,由我数据恢复中心延长保管数据3天,以避免可能忽略的纰漏。
【预估周期】
备份时间:2小时左右
解释及导出数据时间:约4小时
回迁操作系统:约4小时。
【过程详解】
1、对原硬盘进行完整镜像,镜像后发现2号盘有10-20个坏扇区,其余磁盘均无坏道。
2、通过对结构的分析得到的最佳结构为0,1,2,3盘序,缺3号盘,块大小512扇区,backward parity(Adaptec),结构如下图: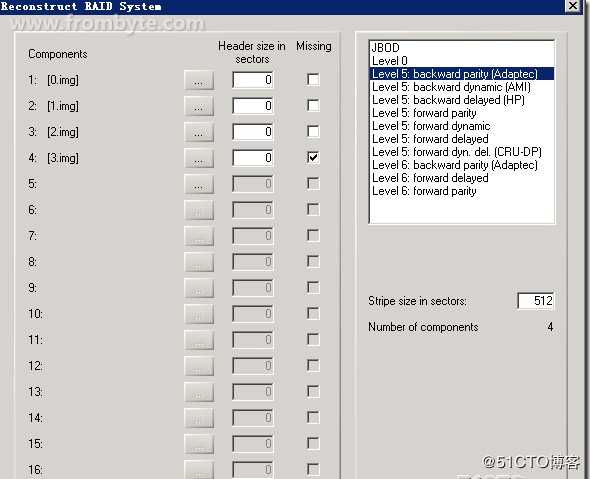
3、组好后数据验证,200M以上的最新压缩包解压无报错,确定结构正确。
4、直接按此结构生成虚拟RAID到一块单硬盘上,打开文件系统无明显报错。
5、确定备份包安全的情况下,经客户同意后,对原盘重建RAID,重建时已经用全新硬盘更换损坏的2号盘。将恢复好的单盘用USB方式接入故障服务器,再用linux SystemRescueCd启动故障服务器,之后通过dd命令进行全盘回写。
6、回写后,启动操作系统。
7、dd所有数据后,启动操作系统,无法进入,报错信息为:/etc/rc.d/rc.sysinit:Line 1:/sbin/pidof:Permission denied,分析为此文件权限有问题。
8、用SystemRescueCd重启后检查,此文件时间、权限、大小均有明显错误,显然节点损坏。
9、重新分析重组数据中的根分区,定位出错的/sbin/pidof,发现问题因2号盘坏道引起。
10、使用0,1,3这3块盘,针对2号盘的损坏区域进行xor补齐。补齐后重新校验文件系统,依然有错误,再次检查inode表,发现2号盘损坏区域有部分节点表现为(图中的55 55 55部分):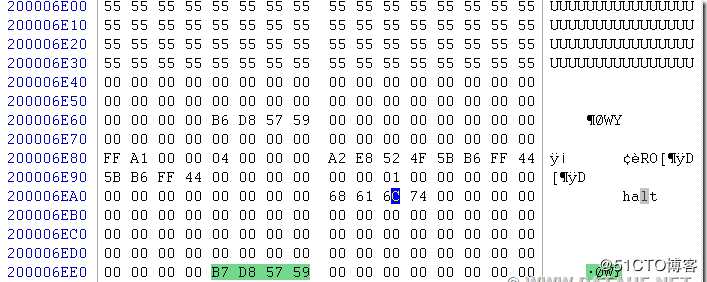
11、很明显,虽然节点中描述的uid还正常存在,但属性,大小,以最初的分配块全部是错误的。按照所有可能进行分析,确定无任何办法找回此损坏节点。只能希望修复此节点,或复制一个相同的文件过来。对所有可能有错的文件,均通过日志确定原节点块的节点信息,再做修正。
12、修正后重新dd根分区,执行fsck -fn /dev/sda5,进行检测,依然有报错,如下图: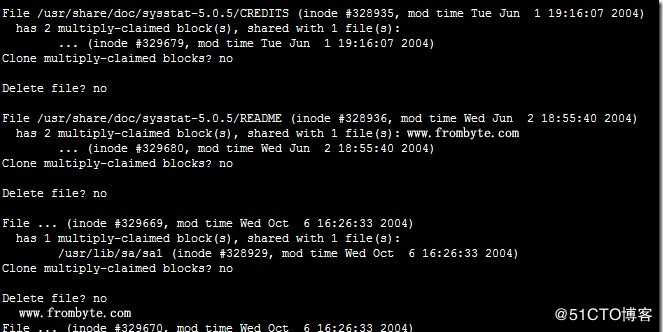
13、根据提示,在系统中发现有多个节点共用同样的数据块。按此提示进行底层分析,发现,因3号盘早掉线,帮存在节点信息的新旧交集。
14、按节点所属的文件进行区别,清除错误节点后,再次执行fsck -fn /dev/sda5,依然有报错信息,但已经很少。根据提示,发现这些节点多位于doc目录下,不影响系统启动,于是直接fsck -fy /dev/sda5强行修复。
15、修复后,重启系统,成功进入桌面。启动数据库服务,启动应用软件,一切正常,无报错。
到此,数据恢复及系统回迁工作完成。以上是关于解析IBM x3850 RAID5服务器故障恢复方案的主要内容,如果未能解决你的问题,请参考以下文章
服务器数据恢复某品牌x3850服务器RAID5两块磁盘先后掉线,服务器崩溃的数据恢复案例