Excel 中一列中有多个数据,每个数据间隔的行数不一样,用啥方法可以快速填充?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Excel 中一列中有多个数据,每个数据间隔的行数不一样,用啥方法可以快速填充?相关的知识,希望对你有一定的参考价值。
如图所示,空白行填充的文本与上面的相同。

假设数据在A列,先选中A列-->F5-->定位条件-->空值-->输入等于号 = 再按键盘上的向上箭头 ↑ ,再按 CTRL+回车 即可。
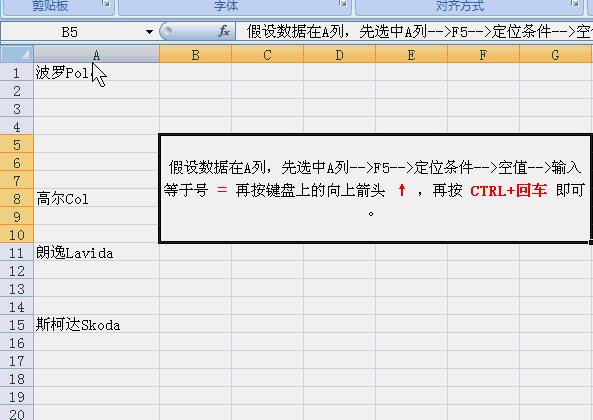
详见下面的动画演示:
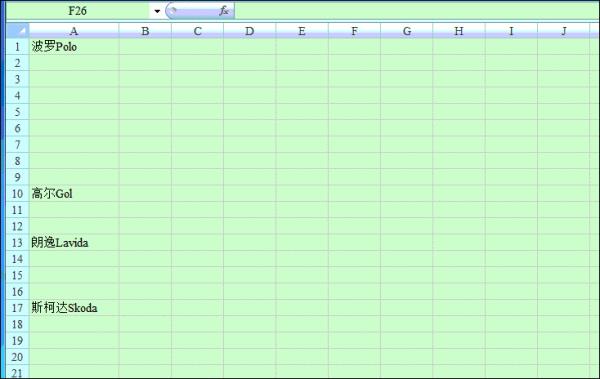
保持选中状态,依次按=↑
再按Ctrl+Enter
索引操作
索引概述
索引是对数据库表中一列或多列的值进行排序的一种结构,使用索引可以提高数据库中特定数据的查询速度。
索引是一个单独的、存储在磁盘上的数据库结构,它们包含着对数据表中所有记录的引用指针。索引用于快速找出在某个或多个列中有一特定值的行,所有 MySQL 列类型都可以被索引,对相关列使用索引是减少查询操作时间的最佳途径。
例如数据库中有 10 万条记录,现在要执行查询 SELECT * FROM table WHERE num=100000 。如果没有索引,必须遍历整个表,直到 num 等于 100000 的这一行被找到为止;如果在 num 列上创建索引,MySQL 不需要任何扫描,直接在索引里面找 100000 就可以得知这一行的位置。可见,索引的建立可以加快数据库的查询速度。
索引的优点主要如下:
(1)通过创建唯一索引可以保证数据库表中每一行数据的唯一性。
(2)可以大大加快数据的查询速度这也是创建索引最主要的原因。
(3)在实现数据的参考完整性方面可以加速表和表之间的连接。
(4)在使用分组和排序子句进行数据查询时也可以显著减少查询中分组和排序的时间。
增加索引也有许多不利的方面,主要如下:
(1)创建索引和维护索引要耗费时间,并且随着数据量的增加所耗费的时间也会增加。
(2)索引需要占磁盘空间,除了数据表占数据空间以外,每一个索引还要占一定的物理空间,如果有大量的索引,索引文件可能比数据文件更快达到最大文件尺寸。
(3)当对表中的数据进行增加、删除和修改的时候索引也要动态维护,这样就降低了数据的维护速度。
索引分类
MySQL 的索引可以分为以下几类
普通索引和唯一索引
- 普通索引:MySQL 中的基本索引类型,允许在定义索引的列中插入重复值和空值。
- 唯一索引:索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一。主键索引是一种特殊的唯一索引,不允许有空值。
单列索引和组合索引
- 单列索引:即一个索引只包含单个列,一个表可以有多个单列索引。
- 组合索引:在表的多个字段组合上创建的索引,只有在查询条件中使用了这些字段的左边字段时索引才会被使用。使用组合索引遵循最左前缀集合。
全文索引
全文索引类型为 FULLTEXT,在定义索引的列上支持值的全文查找,允许在这些索引列中插入重复值和空值。全文索引可以在 CHAR、VARCHAR 或者 TEXT 类型的列上创建。在 MySQL 中只有 MyISAM 存储引擎支持全文索引。
空间索引
空间索引是对空间数据类型的字段建立的索引,MySQL 中的空间数据类型有 4 种,分别是 GEOMETRY、POINT、LINESTRING 和 POLYGON。MySQL 使用 SPATIAL 关键字进行扩展,使得能够用与创建正规索引类似的语法创建空间索引。创建空间索引的列必须将其声明为 NOT NULL,空间索引只能在存储引擎为 MyISAM 的表中创建。
创建和查看索引
在使用 CREATE TABLE 创建表时,除了可以定义列的数据类型以外,还可以定义主键约束、外键约束或者唯一性约束,而不论创建哪种约束,在定义约束时相当于在指定列上创建了一个索引。在创建表时创建索引的基本语法格式如下:
CREATE TABLE table_name [col_name data_type]
[UNIQUE | FULLTEXT | SPATIAL] [INDEX | KEY] [index_name] (col_name [length]) [ASC | DESC]
UNIQUE、FULLTEXT 和 SPATIAL 为可选参数,分别表示唯一索引、全文索引和空间索引;INDEX 和 KEY 为同义词,两者的作用相同,用来指定创建索引;index_name 指定索引的名称,为可选参数,如果不指定,MySQL 默认 col_name 为索引名称;col_name 为需要创建索引的字段列,该列必须从数据表中该定义的多个列中选择;length 为可选参数,表示索引的长度,只有字符串类型的字段才能指定索引长度;ASC 或 DESC 指定升序或者降序的索引值存储。
创建和查看普通索引
普通索引是最基本的索引类型,没有唯一性之类的限制,其作用只是加快对数据的访问速度。
【例】在 fruit 表中的 city_index 字段上建立普通索引
create table fruit (
id int not null,
name varchar(50) not null,
price decimal(8,2) not null,
city varchar(100) not null,
index(city)
);
该语句执行完毕之后,使用 SHOW CREATE TABLE 查看表结构
mysql> show create table fruit G
*************************** 1. row ***************************
Table: fruit
Create Table: CREATE TABLE `fruit` (
`id` int(11) NOT NULL,
`name` varchar(50) NOT NULL,
`price` decimal(8,2) NOT NULL,
`city` varchar(100) NOT NULL,
KEY `city` (`city`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
1 row in set (0.00 sec)
由结果可以看到,在 fruit 表的 city 字段上成功地创建了索引,其索引名称 city 由 MySQL 自动添加。
使用 EXPLAIN 语句查看索引是否正在使用:
mysql> EXPLAIN SELECT * FROM fruit WHERE city=‘上海‘ G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: fruit
partitions: NULL
type: ref
possible_keys: city
key: city
key_len: 302
ref: const
rows: 1
filtered: 100.00
Extra: NULL
1 row in set, 1 warning (0.01 sec)
对 EXPLAIN 语句输出结果中的各个行解释如下:
(1)select_type 行指定所使用的 SELECT 查询类型,这里值为 SIMPLE,表示简单的 SELECT,不使用 UNION 或子查询。其他可能的取值有 PRIMARY、UNION、SUBQUERY 等。
(2)table 行指定数据库读取的数据表的名字,它们按被读取的先后顺序排列。
(3)type 行指定了本数据表与其他数据表之间的关联关系,可能的取值有 system、const、eq_ref、ref、range、index 和 All。
(4)possible_keys 行给出了 MySQL 在搜索数据记录时可以选用的各个索引。
(5)key 行是 MySQL 实际选用的索引。
(6)key_len 行给出索引按字节计算的长度,key_len 数值越小表示越快。
(7)ref 行给出了关联关系中另一个数据表里的数据列的名字。
(8)rows 行是 MySQL 在执行这个查询时预计会从这个数据表里读出的数据行的个数。
(9)Extra 行提供了与关联操作有关的信息。
可以看到,possible_keys 和 key 的值都为 city,在查询时使用了索引。
创建和查看唯一索引
唯一索引与前面的普通索引类似,不同的是索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一。
【例】创建 newfruit 表,在表中的 id 字段上使用 UNIQUE 关键字创建唯一索引
create table newfruit
(
id int not null,
name varchar(50) not null,
price decimal(8,2) not null,
city varchar(100) not null,
UNIQUE INDEX UniqIdx(id)
);
该语句执行完毕之后,使用 SHOW CREATE TABLE 查看表结构
mysql> show create table newfruit G
*************************** 1. row ***************************
Table: newfruit
Create Table: CREATE TABLE `newfruit` (
`id` int(11) NOT NULL,
`name` varchar(50) NOT NULL,
`price` decimal(8,2) NOT NULL,
`city` varchar(100) NOT NULL,
UNIQUE KEY `UniqIdx` (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
1 row in set (0.00 sec)
由结果可以看到,在 id 字段上已经成功建立了一个名为 Uniqldx 的唯一索引。
创建和查看多列索引
组合索引是在多个字段上创建一个索引。
【例】创建 fruit2 表,在表中的 id、name 和 price 字段上建立组合索引
create table fruit2
(
id int not null,
name varchar(50) not null,
price decimal(8,2) not null,
city varchar(100) not null,
INDEX Mmindex(id, name, price)
);
该语句执行完毕之后,使用 SHOW CREATE TABLE 查看表结构
mysql> show create table fruit2 G
*************************** 1. row ***************************
Table: fruit2
Create Table: CREATE TABLE `fruit2` (
`id` int(11) NOT NULL,
`name` varchar(50) NOT NULL,
`price` decimal(8,2) NOT NULL,
`city` varchar(100) NOT NULL,
KEY `Mmindex` (`id`,`name`,`price`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
1 row in set (0.00 sec)
由结果可以看到,在 id、name 和 price 字段上已经成功建立了一个名为 Mmindex 的组合索引。
在 fruit2 表中查询 id 和 name 字段,使用 EXPLAIN 语句查看索引的使用情况
mysql> EXPLAIN SELECT * FROM fruit2 WHERE id=1 AND name=‘苹果‘ G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: fruit2
partitions: NULL
type: ref
possible_keys: Mmindex
key: Mmindex
key_len: 156
ref: const,const
rows: 1
filtered: 100.00
Extra: NULL
1 row in set, 1 warning (0.00 sec)
可以看到,在查询 id 和 name 字段时使用了名为 Mmindex 的索引,如果查询 name 与 price 的组合或者单独查询 name 和 price 字段,将不会使用索引。
例如这里只查询 name 字段:
mysql> EXPLAIN SELECT * FROM fruit2 WHERE name=‘苹果‘ G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: fruit2
partitions: NULL
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 1
filtered: 100.00
Extra: Using where
1 row in set, 1 warning (0.00 sec)
从结果可以看出,possible_keys 和 key 的值为 NULL,说明在查询的时候并没有使用索引。
创建和查看全文索引
全文索引可以用于全文搜索。只有 MyISAM 存储引擎支持全文索引,并且只为 CHAR、VARCHAR和TEXT列。全文索引只能添加到整个字段上,不支持局部(前缀)索引。
【例】创建 fruit3 表,在表中的 city 字段上建立全文索引。
create table fruit3 (
id int not null,
name varchar(50) not null,
price decimal(8,2) not null,
city varchar(100) not null,
FULLTEXT INDEX Fullindex(city)
) ENGINE=MyISAM;
语句执行完毕之后,使用 SHOW CREATE TABLE 查看表结构
mysql> show create table fruit3 G
*************************** 1. row ***************************
Table: fruit3
Create Table: CREATE TABLE `fruit3` (
`id` int(11) NOT NULL,
`name` varchar(50) NOT NULL,
`price` decimal(8,2) NOT NULL,
`city` varchar(100) NOT NULL,
FULLTEXT KEY `Fullindex` (`city`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8
1 row in set (0.00 sec)
由结果可以看到,在 city 字段上已经成功建立了一个名为 Fullindex 的全文索引。全文索引非常适合大型数据集,对于小的数据集,它的用处可能比较小。
删除索引
在 MySQL 中删除索引使用 DROP INDEX 或者 ALTER TABLE,两者可实现相同的功能。
使用 DROP INDEX 删除索引
语法格式如下:
DROP INDEX index_name ON table_name;
【例】删除 newfruit 表中名称为 Uniqldx 的唯一索引
drop index uniqidx on newfruit;
mysql> show create table newfruit G
*************************** 1. row ***************************
Table: newfruit
Create Table: CREATE TABLE `newfruit` (
`id` int(11) NOT NULL,
`name` varchar(50) NOT NULL,
`price` decimal(8,2) NOT NULL,
`city` varchar(100) NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8
1 row in set (0.00 sec)
可以看到,在 newfruit 表中已经没有名称为 Uniqldx 的唯一索引,删除索引成功
使用 ALTER TABLE 删除索引
基本语法格式如下:
ALTER TABLE table_name DROP INDEX index_name;
【例】删除 fruit2 表中名称为 Mmindex 的组合索引
ALTER TABLE fruit2 DROP INDEX Mmindex;
mysql> show create table fruit2 G
*************************** 1. row ***************************
Table: fruit2
Create Table: CREATE TABLE `fruit2` (
`id` int(11) NOT NULL,
`name` varchar(50) NOT NULL,
`price` decimal(8,2) NOT NULL,
`city` varchar(100) NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8
1 row in set (0.00 sec)
由结果可以看到,fruit2 表中已经没有名称为 Mmindex 的组合索引,删除索引成功。
以上是关于Excel 中一列中有多个数据,每个数据间隔的行数不一样,用啥方法可以快速填充?的主要内容,如果未能解决你的问题,请参考以下文章
如何计算包含一组列中的值和 Pandas 数据框中另一列中的另一个值的行数?
Excel2007怎么选中一列中除了第一行之外的下面所有的行?
关于Excel判断一列数据是不是在另一列中存在,并且把存在的数据提取出来