hadoop安装时配置core-site.xml文件时候,出现如下问题。
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hadoop安装时配置core-site.xml文件时候,出现如下问题。相关的知识,希望对你有一定的参考价值。
[root@localhost hadoop]# source core-site.xml
bash: core-site.xml: line 1: syntax error near unexpected token `newline'
bash: core-site.xml: line 1: `<?xml version="1.0" encoding="UTF-8"?>'
请问如何解决?
文件里边内容没问题的,为了检测,我从新装了一遍hadoop,没有操作之前source了一下,但是还是有这样的问题。
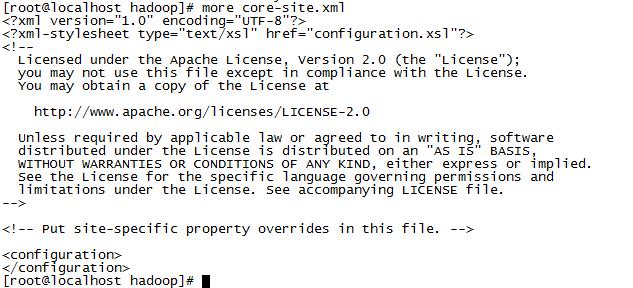
1 [hadoop@bigdata-senior01 hadoop-2.5.0]$ $HADOOP_HOME/bin/hdfs dfs -put
2 $HADOOP_HOME/etc/hadoop/core-site.xml /demo1
你们问的是这个, 这个 命令的用法是,
$HADOOP_HOME/bin/hdfs dfs -put $HADOOP_HOME/etc/hadoop/core-site.xml /demo1
这是一句 话 ,格式是: hdfs dfs -put <localfile> <dst file> 把想传上去的本地文件, 传送到hdfs 创建的目标文件夹里。 参考技术A 这个是xml文件,不是.bashrc或者其他的配置文件,所以不用source,配置完了直接生效的。。。
所以你这个不是错误,没有必要重装,如果hadoop某些服务启动不了,可以去看日志找问题。 参考技术B 楼主这个问题解决了没有,我也遇到了相同的问题,同样是xml文件报这个错,究竟这是怎么回事啊,如果你解决了麻烦告诉一下啊先谢谢了!~ 参考技术C 检查xml文件,有没有不符合语法的地方,或者多弄个不起眼的符号自己没发现追问
文件里边内容没问题的,为了检测,我从新装了一遍hadoop,没有操作之前source了一下,但是还是有这样的问题。
追答把文件发个图呗!
追问我从新贴了一个图。
追答你为什么要source core-site.xml;
安装hadoop应该是不需要这个操作的
Ubuntu 安装 Hadoop(伪分布模式)
在Ubuntu14.04下安装Hadoop2.4.0 (单机模式)基础上配置
一、配置core-site.xml
/usr/local/hadoop/etc/hadoop/core-site.xml 包含了hadoop启动时的配置信息。
编辑器中打开此文件
sudo gedit /usr/local/hadoop/etc/hadoop/core-site.xml

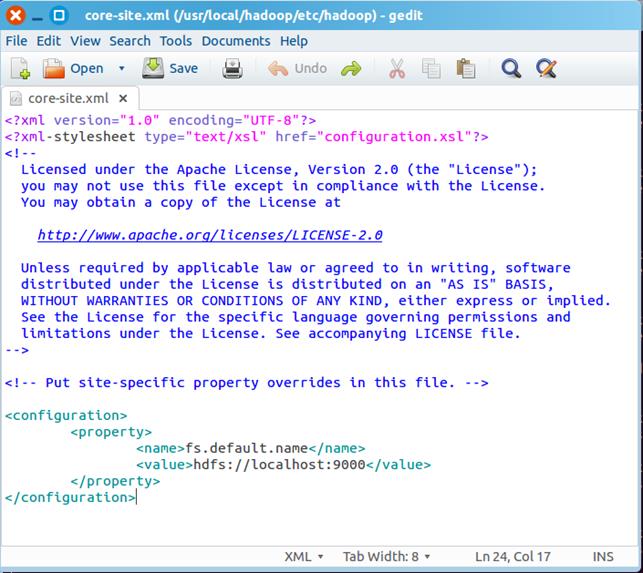
在该文件的<configuration></configuration>之间增加如下内容:
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
保存、关闭编辑窗口。
最终修改后的文件内容如下:
二、配置yarn-site.xml
/usr/local/hadoop/etc/hadoop/yarn-site.xml包含了MapReduce启动时的配置信息。
编辑器中打开此文件
sudo gedit yarn-site.xml

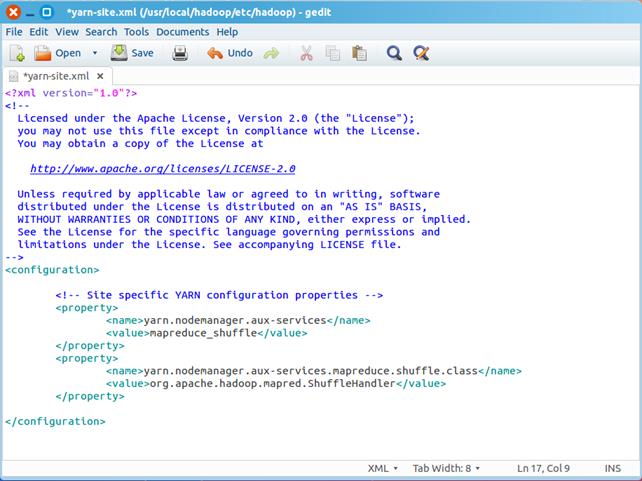
在该文件的<configuration></configuration>之间增加如下内容:
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
保存、关闭编辑窗口
最终修改后的文件内容如下
三、创建和配置mapred-site.xml
默认情况下,/usr/local/hadoop/etc/hadoop/文件夹下有mapred.xml.template文件,我们要复制该文件,并命名为mapred.xml,该文件用于指定MapReduce使用的框架。
复制并重命名
cp mapred-site.xml.template mapred-site.xml
编辑器打开此新建文件
sudo gedit mapred-site.xml

在该文件的<configuration></configuration>之间增加如下内容:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
保存、关闭编辑窗口
最终修改后的文件内容如下

四、配置hdfs-site.xml
/usr/local/hadoop/etc/hadoop/hdfs-site.xml用来配置集群中每台主机都可用,指定主机上作为namenode和datanode的目录。
创建文件夹,如下图所示
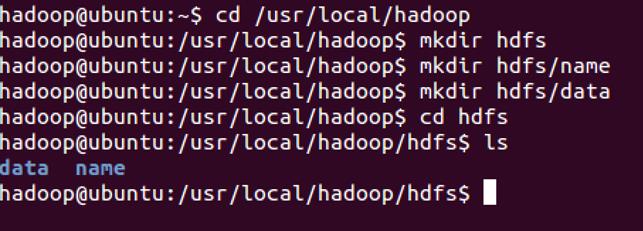
你也可以在别的路径下创建上图的文件夹,名称也可以与上图不同,但是需要和hdfs-site.xml中的配置一致。
编辑器打开hdfs-site.xml
在该文件的<configuration></configuration>之间增加如下内容:
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/hdfs/data</value>
</property>
保存、关闭编辑窗口
最终修改后的文件内容如下:

五、格式化hdfs
在profile文件中添加:
export JAVA_LIBRARY_PATH=/usr/local/hadoop/lib/native
(注:调用hadoop里的库)
hdfs namenode -format
只需要执行一次即可,如果在hadoop已经使用后再次执行,会清除掉hdfs上的所有数据。
六、启动Hadoop
经过上文所描述配置和操作后,下面就可以启动这个单节点的集群
执行启动命令:
sbin/start-dfs.sh
执行该命令时,如果有yes /no提示,输入yes,回车即可。
接下来,执行:
sbin/start-yarn.sh
执行完这两个命令后,Hadoop会启动并运行
执行 jps命令,会看到Hadoop相关的进程,如下图:

浏览器打开 http://localhost:50070/,会看到hdfs管理页面
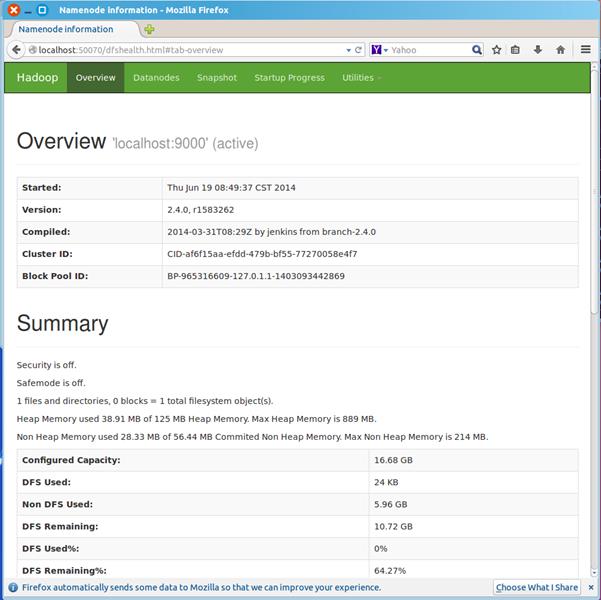
浏览器打开http://localhost:8088,会看到hadoop进程管理页面

七、WordCount验证
dfs上创建input目录
bin/hadoop fs -mkdir -p input

把hadoop目录下的README.txt拷贝到dfs新建的input里
hadoop fs -copyFromLocal README.txt input

运行WordCount
hadoop jar share/hadoop/mapreduce/sources/hadoop-mapreduce-examples-2.4.0-sources.jar org.apache.hadoop.examples.WordCount input output

可以看到执行过程
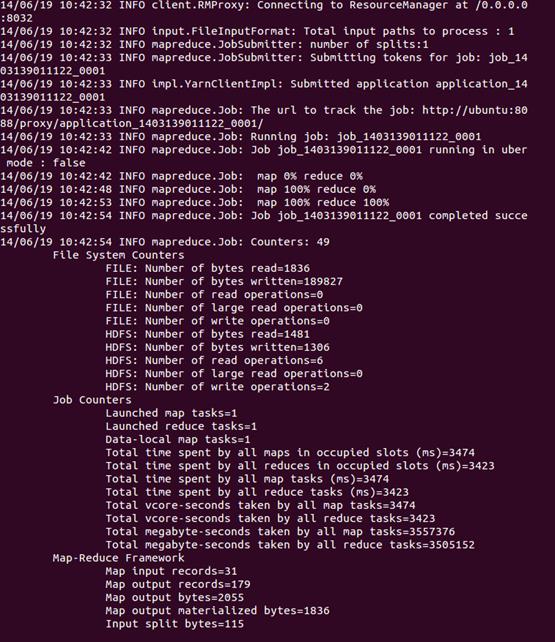
运行完毕后,查看单词统计结果
hadoop fs -cat output/*

以上是关于hadoop安装时配置core-site.xml文件时候,出现如下问题。的主要内容,如果未能解决你的问题,请参考以下文章