Android之网络—第二篇(Https原理)
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Android之网络—第二篇(Https原理)相关的知识,希望对你有一定的参考价值。
参考技术A android之网络—第一篇(Http原理)Android之网络—第二篇(Https原理)
Android之网络—第三篇(解读OkHttp)
Android之网络—第四篇(解读Retrofit)
说的通俗一点就是身披安全衣的Http,本质还是http,只是在http外层嵌套了一个SSL/TLS的安全层,该层做了一些数据的加解密处理。
在讲解Https原理之前,先做点准备工作,因为会涉及到SSL/TLS连接建立、SSL/TLS加解密方面的知识。所以会整体从网络架构和比较重要的知识点回顾下网络知识。
在讲解什么是SSL/TLS之前,回顾下TCP/IP协议的分层概念。通常一个网络的传输中间会经过很多的传输节点,才最终达到服务器。期间过程会包含数据的拆分和拼装、IP的解析、数据的传输等等操作,但是网络传输是很不稳定的,如果这次网络请求在中间的某一节点失败了,难道还要重新再发送一遍么?答案是不应该这么做。
为了网络传输的统一规范,就设计了这么一套网络通信的规范,每一层都专注做一件事情,即使当前失败了,也在这层做处理就可以了,尽量避免重发。
简单解释下,每层的含义:
通过上图发现,数据是由上往下传递后,再由下往回传递。这是怎么回事呢?总结就是:在 TCP / IP 协议中数据先由上往下将数据装包,然后由下往上拆包。在装包的时候,每一层都会增加一些信息用于传输,这部分信息就叫报头,当上层的数据到达本层的时候,会将数据加上本层的报头打包在一起,继续往下传递。在拆包的时候,每一层将本层需要的报头读取后,就将剩下的数据往上传。
简要分析下传输过程:
这里简单总结下传输层的两种连接方式:TCP和UDP
三次握手:客户端主动打开连接,服务器被动打开连接。
四次挥手:客户端主动关闭,服务器被动关闭
说个概念性的东西就是,现代密码学分为对称加密和非对称加密,跟传统密码学不一样的地方就是,除了可以加密文字内容外,还可以用于各种二进制数据的加解密。
通信双方使用同一个密钥,使用加密算法配合上密钥来加密,解密时使用解密算法(加密过程的完全逆运算)配合密钥来进行解密。常用的经典算法:DES(56 位密钥,密钥太短而逐渐被弃用)、AES(128 位、192 位、256 位密钥,现在最流行)。
通信双方使用公钥和加密算法对数据进行加密得到密文;使用私钥和加密算法对数据进行解密得到原数据。常用的经典算法:RSA(可用于加密和签名)、DSA(仅用于签名,但速度更快)。
这个有什么用?其实这个就是后面Https加解密的原理。原理这么简单么?是的,就这么简单。但是要理解还得慢慢往下看。
A用自己的私钥通过加密算法得到的数据密文数据,这个数据就可以称为签过名。接收方B再用A提供的公钥通过加密算法就可以还原数据,从而就验证了数据的真实性。因为只有A一个人拥有自己的私钥。
到这里咱们就可以聊聊刚才中间人伪造数据是如何处理了。通过对称加密可以防止中间人偷窥数据,通过数字签名可以防止中间人篡改伪造数据。
但是完整版的签名信息需要将签名数据取Hash值,减少数据大小
好了,看完理解了上面的知识点,到这里我们可以慢慢分析Https是如何工作的了。
先来总结一句话:Https的本质就是在客户端和服务端之间用非对称加密协商出一套对称密钥,每次发送信息之前将内容加密,接收后解密,达到内容的加密传输。解释下,就是整个数据的传输过程是用对称加密的方式来传输的,只是密钥的生成是由客户端和服务端 在创建连接的时候 通过 非对称加密的方式 协商生成的。
那这里就会有一系列的问题啦:
Q:为什么不直接用非对称加密的方式直接加密呢?
A:因为非对称加密的计算过程是复杂的数学运算,太复杂了,很慢。
Q:哦哦,那既然使用对称加密的话,这个对称密钥是怎么来的?
A:在实际的场景中,服务端会对接N个客户端,这个对称密钥如果都使用同一个密钥来通信的话,肯定是不合理的,只要破解了其中一个,其他所有的都会被破解。所以整体的网络架构应该是使用不同加密方式用不同的密钥来进行数据传输的。模型如下图
Q:但是在网络场景中,对称加密的密钥是不能直接在网络上传输的。服务端和客户端是如何都知道的呢?
A:这个是服务端和客户端一起协商根据只有它俩知道的规则分别生成,就不用通过网络传输啦。
Q:如果保证它俩协商出来的密钥不被破解呢?
A:当然是使用非对称加密的方式啦。通过之前的加密知识,可以知道非对称加密是目前来说是绝对安全的。而且一个私钥可以有多个公钥,正好满足一个服务端对N个客户端的场景。模型如下图:
实际在协商通讯的过程中,这个公钥是服务端给客户端发送的。而且需要注意 这个公钥是用来协商生成对称密钥的,不是用来做数据的加密传输的 。
Q:哦哦,原来是这样,但是这样子还是有问题啊,客户端与服务端在协商生成密钥的过程中为了保证数据被偷窥和被篡改的风险,一般会要求有两套公钥和私钥分别做加解密和签名验证处理的,上面的模型只有一套公钥和私钥,没法规避数据被被篡改的风险呀。
A:能提出这个问题,说明之前的学习理解得很好。从上面的模型,可以保证在协商的过程中客户端A/B/C/D分别向服务器传输的数据是安全。但是服务器发送给客户端的数据是如何保证的呢?换句话说就是,客户端如何验证数据是服务端发送过来的,而不是被中间假冒掉包的数据。这不就是之前讲的数字签名的内容么?而实际情况中,就是通过CA证书来处理这个问题的。
Q:那这个CA证书是怎么验证的呢?
A:请看下面的CA证书的分析。
回归之前的分析,我们的问题点卡在了“服务器发送给客户端的数据是如何保证的呢”。对吧。实际上在协商通信的过程中,服务端会先给客户端下发证书信息,这个证书信息里面会包含非对称加密的公钥。但是考虑一个问题,如何保证这个公钥就是客户端要的公钥呢?或者说怎么保证这个证书就是真实的证书,而不是被篡改假冒的证书。只有验证了这一步,客户端才完全信赖服务端,才给服务器发消息,也才接受服务器的消息。这时候就只需要一套公钥和私钥客户端和服务端就可以通信了。
Q:那客户端如何验证服务端下发的证书和公钥是正确的呢?
A:先换个概念,将证书里面的公钥假设为一串数据。要验证这个数据,只需要提供这串数据的签名以及加密这段数据的签名的私钥对应的公钥就可以了,如下图框框所示。
Q:那这样子又有另外的一个问题产生了怎么去验证 这段数据的签名的私钥对应的公钥 了?
A:同样的,也是需要提供对应的签名和对应签名的私钥对应的公钥。
Q:但是这样子下去就会变成一个循环了,怎么办?
其实在这里还会有一个场景问题:第三方签发机构不可能只给你一家公司制作证书,它也可能会给中间人这样有坏心思的公司发放证书。这样的,中间人就有机会对你的证书进行调包,客户端在这种情况下是无法分辨出是接收的是你的证书,还是中间人的。因为不论中间人,还是你的证书,都能使用第三方签发机构的公钥进行解密。
A:是的,为处理这个问题,就需要讲一个根证书的东西。先举个例子:假设你是HR,你手上拿到候选人的学历证书,证书上写了持证人,颁发机构,颁发时间等等,同时证书上,还写有一个最重要的:证书编号!我们怎么鉴别这张证书是的真伪呢?只要拿着这个证书编号上相关机构去查,如果证书上的持证人与现实的这个候选人一致,同时证书编号也能对应上,那么就说明这个证书是真实的。同样的,Https请求验证时,会用到手机操作系统内置的根证书去验证这个证书的真伪的。
到这里就简要分析完了证书的验证过程。证书会包含很多信息,包括服务器公钥,服务器名字,服务器地区等等信息。这个是没法篡改的。其中对Https连接来说最重要的就是服务器的公钥。
之前学习完TCP的连接过程,现在我们开始来唠唠Https连接。什么是Https连接呢?准确来说就是SSL/TLS加解密层的连接。
大致的建立流程:
详细的建立流程:
客户端MAC secret,服务端MAC secret的主要作用:用来认证这个消息是正确的,完整的,解决对称加密方式没法验证消息的缺点。
至此完整的Https在TLS层连接过程分析完毕。
如果觉得我的文章对你有帮助,请随意赞赏。您的支持将鼓励我继续创作!
openpcdet之pointpillar代码阅读——第二篇:网络结构
文章目录
pointpillar相关的其它文章链接如下:
上一篇文章,我们梳理了数据增强和数据处理,并且得到了相应的pillar数据。下面我们继续讲pointpillar中的网络结构。
整体网络结构如下:
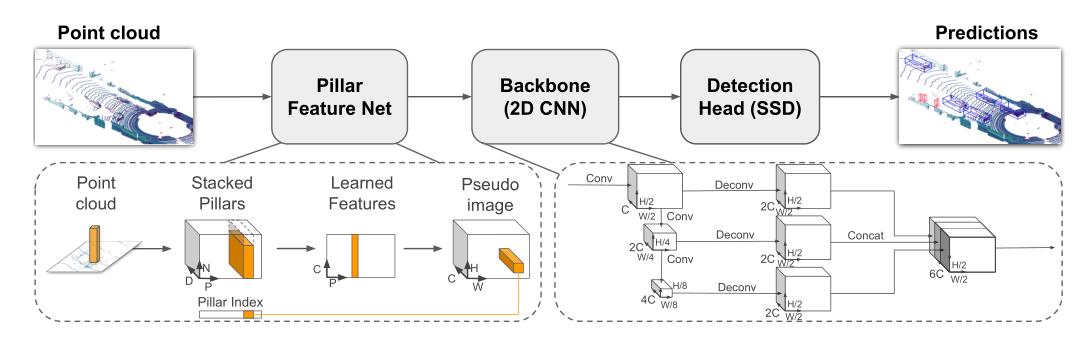
1. VFE
功能:这部分是简化版的pointnet网络,将经过数据增强和数据处理过后的pillar(N,4)数据,经过BN层、Relu激活层和max pool层得到(C, H, W)数据。
在VFE之前的data_dict的数据如下所示:
'''
batch_dict:
points:(N,5) --> (batch_index,x,y,z,r) batch_index代表了该点云数据在当前batch中的index
frame_id:(batch_size,) -->帧ID-->我们存放的是npy的绝对地址,batch_size个地址
gt_boxes:(batch_size,N,8)--> (x,y,z,dx,dy,dz,ry,class),
use_lead_xyz:(batch_size,) --> (1,1,1,1),batch_size个1
voxels:(M,32,4) --> (x,y,z,r)
voxel_coords:(M,4) --> (batch_index,z,y,x) batch_index代表了该点云数据在当前batch中的index
voxel_num_points:(M,):每个voxel内的点云
batch_size:batch_size大小
'''
随后经过VFE之后,就可以把原始的点云结构
(
N
∗
4
)
(N*4)
(N∗4)变换成了
(
D
,
P
,
N
)
(D,P,N)
(D,P,N),其中 D代表了每个点云的特征维度,也就是每个点云10个特征(论文中只有9维),P代表了所有非空的立方柱体,N代表了每个pillar中最多会有多少个点。具体操作以及说明如下:
- D ( x , y , z , x c , r , y c , z c , x p , y p , z p ) D(x,y,z, x_c ,r, y_c , z_c , x_p ,y_p,z_p) D(x,y,z,xc,r,yc,zc,xp,yp,zp):xyz表示点云的真实坐标,下标c代表了每个点云到该点所对应pillar中所有点平均值的偏移量,下标p表示该点距离所在pillar中心点的偏移量。
- P:代表了所有非空的立方柱体,yaml配置中有最大值MAX_NUMBER_OF_VOXELS。
- N:代表了每个pillar中最多会有多少个点,实际操作取32。
得到 ( D , P , N ) (D,P,N) (D,P,N)的张量后,接下来这里使用了一个简化版的pointnet网络对点云的数据进行特征提取(即将这些点通过MLP升维,然后跟着BN层和Relu激活层),得到一个 ( C , P , N ) (C,P,N) (C,P,N)形状的张量,之后再使用max pooling操作提取每个pillar中最能代表该pillar的点。那么输出会变成 ( C , P , N ) − > ( C , P ) − > ( C , H , W ) (C,P,N)->(C,P)->(C, H, W) (C,P,N)−>(C,P)−>(C,H,W)
这部分代码在:pcdet/models/backbones_3d/vfe/pillar_vfe.py,具体的注释代码如下:
import torch
import torch.nn as nn
import torch.nn.functional as F
from .vfe_template import VFETemplate
class PFNLayer(nn.Module):
def __init__(self,
in_channels,
out_channels,
use_norm=True,
last_layer=False):
super().__init__()
self.last_vfe = last_layer
self.use_norm = use_norm
if not self.last_vfe:
out_channels = out_channels // 2
# x的维度由(M, 32, 10)升维成了(M, 32, 64),max pool之后32才去掉
if self.use_norm:
self.linear = nn.Linear(in_channels, out_channels, bias=False)
self.norm = nn.BatchNorm1d(out_channels, eps=1e-3, momentum=0.01)
else:
self.linear = nn.Linear(in_channels, out_channels, bias=True)
self.part = 50000
def forward(self, inputs):
if inputs.shape[0] > self.part:
# nn.Linear performs randomly when batch size is too large
num_parts = inputs.shape[0] // self.part
part_linear_out = [self.linear(inputs[num_part*self.part:(num_part+1)*self.part])
for num_part in range(num_parts+1)]
x = torch.cat(part_linear_out, dim=0)
else:
x = self.linear(inputs)
torch.backends.cudnn.enabled = False
#permute变换维度,(M, 64, 32) --> (M, 32, 64)
# 这里之所以变换维度,是因为BatchNorm1d在通道维度上进行,对于图像来说默认模式为[N,C,H*W],通道在第二个维度上
x = self.norm(x.permute(0, 2, 1)).permute(0, 2, 1) if self.use_norm else x
torch.backends.cudnn.enabled = True
x = F.relu(x)
# 完成pointnet的最大池化操作,找出每个pillar中最能代表该pillar的点
x_max = torch.max(x, dim=1, keepdim=True)[0]
if self.last_vfe:
return x_max
else:
x_repeat = x_max.repeat(1, inputs.shape[1], 1)
x_concatenated = torch.cat([x, x_repeat], dim=2)
return x_concatenated
class PillarVFE(VFETemplate):
def __init__(self, model_cfg, num_point_features, voxel_size, point_cloud_range, **kwargs):
super().__init__(model_cfg=model_cfg)
self.use_norm = self.model_cfg.USE_NORM
self.with_distance = self.model_cfg.WITH_DISTANCE
self.use_absolute_xyz = self.model_cfg.USE_ABSLOTE_XYZ
# num_point_features:10
num_point_features += 6 if self.use_absolute_xyz else 3
if self.with_distance:
num_point_features += 1
#[64]
self.num_filters = self.model_cfg.NUM_FILTERS
assert len(self.num_filters) > 0
# num_filters: [10, 64]
num_filters = [num_point_features] + list(self.num_filters)
pfn_layers = []
#len(num_filters) - 1 == 1
for i in range(len(num_filters) - 1):
in_filters = num_filters[i] # 10
out_filters = num_filters[i + 1] # 64
pfn_layers.append(
PFNLayer(in_filters, out_filters, self.use_norm, last_layer=(i >= len(num_filters) - 2))
)
#收集PFN层,在forward中执行
self.pfn_layers = nn.ModuleList(pfn_layers)
self.voxel_x = voxel_size[0]
self.voxel_y = voxel_size[1]
self.voxel_z = voxel_size[2]
self.x_offset = self.voxel_x / 2 + point_cloud_range[0]
self.y_offset = self.voxel_y / 2 + point_cloud_range[1]
self.z_offset = self.voxel_z / 2 + point_cloud_range[2]
def get_output_feature_dim(self):
return self.num_filters[-1]
def get_paddings_indicator(self, actual_num, max_num, axis=0):
'''
指出一个pillar中哪些是真实数据,哪些是填充的0数据
'''
actual_num = torch.unsqueeze(actual_num, axis + 1)
max_num_shape = [1] * len(actual_num.shape)
max_num_shape[axis + 1] = -1
max_num = torch.arange(max_num, dtype=torch.int, device=actual_num.device).view(max_num_shape)
paddings_indicator = actual_num.int() > max_num
return paddings_indicator
def forward(self, batch_dict, **kwargs):
'''
batch_dict:
points:(N,5) --> (batch_index,x,y,z,r) batch_index代表了该点云数据在当前batch中的index
frame_id:(batch_size,) -->帧ID-->我们存放的是npy的绝对地址,batch_size个地址
gt_boxes:(batch_size,N,8)--> (x,y,z,dx,dy,dz,ry,class),
use_lead_xyz:(batch_size,) --> (1,1,1,1),batch_size个1
voxels:(M,32,4) --> (x,y,z,r)
voxel_coords:(M,4) --> (batch_index,z,y,x) batch_index代表了该点云数据在当前batch中的index
voxel_num_points:(M,):每个voxel内的点云
batch_size:4:batch_size大小
'''
voxel_features, voxel_num_points, coords = batch_dict['voxels'], batch_dict['voxel_num_points'], batch_dict['voxel_coords']
#求每个pillar中所有点云的平均值,设置keepdim=True的,则保留原来的维度信息
points_mean = voxel_features[:, :, :3].sum(dim=1, keepdim=True) / voxel_num_points.type_as(voxel_features).view(-1, 1, 1)
#每个点云数据减去该点对应pillar的平均值,得到差值 xc,yc,zc
f_cluster = voxel_features[:, :, :3] - points_mean
# 创建每个点云到该pillar的坐标中心点偏移量空数据 xp,yp,zp
f_center = torch.zeros_like(voxel_features[:, :, :3])
'''
coords是每个网格点的坐标,即[432, 496, 1],需要乘以每个pillar的长宽得到点云数据中实际的长宽(单位米)
同时为了获得每个pillar的中心点坐标,还需要加上每个pillar长宽的一半得到中心点坐标
每个点的x、y、z减去对应pillar的坐标中心点,得到每个点到该点中心点的偏移量
'''
f_center[:, :, 0] = voxel_features[:, :, 0] - (coords[:, 3].to(voxel_features.dtype).unsqueeze(1) * self.voxel_x + self.x_offset)
f_center[:, :, 1] = voxel_features[:, :, 1] - (coords[:, 2].to(voxel_features.dtype).unsqueeze(1) * self.voxel_y + self.y_offset)
f_center[:, :, 2] = voxel_features[:, :, 2] - (coords[:, 1].to(voxel_features.dtype).unsqueeze(1) * self.voxel_z + self.z_offset)
#配置中使用了绝对坐标,直接组合即可。
if self.use_absolute_xyz:
features = [voxel_features, f_cluster, f_center] #10个特征,直接组合
else:
features = [voxel_features[..., 3:], f_cluster, f_center]
#距离信息,False
if self.with_distance:
points_dist = torch.norm(voxel_features[:, :, :3], 2, 2, keepdim=True)
features.append(points_dist)
features = torch.cat(features, dim=-1)
voxel_count = features.shape[1]
#mask中指明了每个pillar中哪些是需要被保留的数据
mask = self.get_paddings_indicator(voxel_num_points, voxel_count, axis=0)
mask = torch.unsqueeze(mask, -1).type_as(voxel_features)
#由0填充的数据,在计算出现xc,yc,zc和xp,yp,zp时会有值
#features中去掉0值信息。
features *= mask
#执行上面收集的PFN层,每个pillar抽象出64维特征
for pfn in self.pfn_layers:
features = pfn(features)
features = features.squeeze()
batch_dict['pillar_features'] = features
return batch_dict
2. MAP_TO_BEV
功能:将得到的pillar数据,投影至二维坐标中。
在经过简化版的pointnet网络提取出每个pillar的特征信息后,就需要将每个的pillar数据重新放回原来的坐标中,也就是二维坐标,组成 伪图像 数据。
对应到论文中就是stacked pillars,将生成的pillar按照坐标索引还原到原空间中。
这部分代码在:pcdet/models/backbones_2d/map_to_bev/pointpillar_scatter.py,具体的注释代码如下:
import torch
import torch.nn as nn
class PointPillarScatter(nn.Module):
def __init__(self, model_cfg, grid_size, **kwargs):
super().__init__()
self.model_cfg = model_cfg
self.num_bev_features = self.model_cfg.NUM_BEV_FEATURES #64
self.nx, self.ny, self.nz = grid_size # [432,496,1]
assert self.nz == 1
def forward(self, batch_dict, **kwargs):
'''
batch_dict['pillar_features']-->为VFE得到的数据(M, 64)
voxel_coords:(M,4) --> (batch_index,z,y,x) batch_index代表了该点云数据在当前batch中的index
'''
pillar_features, coords = batch_dict['pillar_features'], batch_dict['voxel_coords']
batch_spatial_features = []
# 根据batch_index,获取batch_size大小
batch_size = coords[:, 0].max().int().item() + 1
for batch_idx in range(batch_size):
# 创建一个空间坐标所有用来接受pillar中的数据
# spatial_feature 维度 (64,214272)
spatial_feature = torch.zeros(
self.num_bev_features,
self.nz * self.nx * self.ny,
dtype=pillar_features.dtype,
device=pillar_features.device)
batch_mask = coords[:, 0] == batch_idx #返回mask,[True, False...]
this_coords = coords[batch_mask, :] #获取当前的batch_idx的数
#计算pillar的索引,该点之前所有行的点总和加上该点所在的列即可
indices = this_coords[:, 1] + this_coords[:, 2] * self.nx + this_coords[:, 3]
indices = indices.type(torch.long) # 转换数据类型
pillars = pillar_features[batch_mask, :]
pillars = pillars.t()
# 在索引位置填充pillars
spatial_feature[:, indices] = pillars
# 将空间特征加入list,每个元素为(64, 214272)
batch_spatial_features.append(spatial_feature)
# 在第0个维度将所有的数据堆叠在一起
batch_spatial_features = torch.stack(batch_spatial_features, 0)
# reshape回原空间(伪图像) (4, 64, 214272)--> (4, 64, 496, 432)
batch_spatial_features = batch_spatial_features.view(batch_size, self.num_bev_features * self.nz, self.ny, self.nx)
batch_dict['spatial_features'] = batch_spatial_features
#返回数据
return batch_dict
3. BACKBONE_2D
功能:骨干网络,提取特征
经过上面的映射操作,将原来的pillar提取最大的数值后放回到相应的坐标后,就可以得到类似于图像的数据了;只有在有pillar非空的坐标处有提取的点云数据,其余地方都是0数据,所以得到的一个(batch_size,64, 432, 496)的张量还是很稀疏的。
BACKBONE_2D的输入特征维度(batch_size,64, 432, 496),输出的特征维度为[batch_size, 384, 248, 216]。
需要说明的是,主干网络构建了下采样和上采样网络,分别为加入到了blocks和deblocks中,上采样和下采样的具体操作可查看下列代码和注释。
这部分代码在:pcdet/models/backbones_2d/base_bev_backbone.py,具体的注释代码如下:
import numpy as np
import torch
import torch.nn as nn
class BaseBEVBackbone(nn.Module):
# input_channels = 64
def __init__(self, model_cfg, input_channels):
super()