影响数据检索效率的几个因素
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了影响数据检索效率的几个因素相关的知识,希望对你有一定的参考价值。
影响数据检索效率的几个因素数据检索有两种主要形态。第一种是纯数据库型的。典型的结构是一个关系型数据,比如 mysql。用户通过 SQL 表
参考技术A 影响数据检索效率的几个因素数据检索有两种主要形态。第一种是纯数据库型的。典型的结构是一个关系型数据,比如 mysql。用户通过 SQL 表达出所需要的数据,mysql 把 SQL 翻译成物理的数据检索动作返回结果。第二种形态是现在越来越流行的大数据玩家的玩法。典型的结构是有一个分区的数据存储,最初这种存储就是原始的 HDFS,后来开逐步有人在 HDFS 上加上索引的支持,或者干脆用 Elasticsearc 这样的数据存储。然后在存储之上有一个分布式的实时计算层,比如 Hive 或者 Spark SQL。用户用 Hive SQL 提交给计算层,计算层从存储里拉取出数据,进行计算之后返回给用户。这种大数据的玩法起初是因为 SQL 有很多 ad-hoc 查询是满足不了的,干脆让用户自己写 map/reduce 想怎么算都可以了。但是后来玩大了之后,越来越多的人觉得这些 Hive 之类的方案查询效率怎么那么低下啊。于是一个又一个项目开始去优化这些大数据计算框架的查询性能。这些优化手段和经典的数据库优化到今天的手段是没有什么两样的,很多公司打着搞计算引擎的旗号干着重新发明数据库的活。所以,回归本质,影响数据检索效率的就那么几个因素。我们不妨来看一看。
数据检索干的是什么事情
定位 => 加载 => 变换
找到所需要的数据,把数据从远程或者磁盘加载到内存中。按照规则进行变换,比如按某个字段group by,取另外一个字段的sum之类的计算。
影响效率的四个因素
读取更少的数据
数据本地化,充分遵循底层硬件的限制设计架构
更多的机器
更高效率的计算和计算的物理实现
原则上的四点描述是非常抽象的。我们具体来看这些点映射到实际的数据库中都是一些什么样的优化措施。
读取更少的数据
数据越少,检索需要的时间当然越少了。在考虑所有技术手段之前,最有效果的恐怕是从业务的角度审视一下我们是否需要从那么多的数据中检索出结果来。有没有可能用更少的数据达到同样的效果。减少的数据量的两个手段,聚合和抽样。如果在入库之前把数据就做了聚合或者抽样,是不是可以极大地减少查询所需要的时间,同时效果上并无多少差异呢?极端情况下,如果需要的是一天的总访问量,比如有1个亿。查询的时候去数1亿行肯定快不了。但是如果统计好了一天的总访问量,查询的时候只需要取得一条记录就可以知道今天有1个亿的人访问了。
索引是一种非常常见的减少数据读取量的策略了。一般的按行存储的关系型数据库都会有一个主键。用这个主键可以非常快速的查找到对应的行。KV存储也是这样,按照Key可以快速地找到对应的Value。可以理解为一个Hashmap。但是一旦查询的时候不是用主键,而是另外一个字段。那么最糟糕的情况就是进行一次全表的扫描了,也就是把所有的数据都读取出来,然后看要的数据到底在哪里,这就不可能快了。减少数据读取量的最佳方案就是,建立一个类似字典一样的查找表,当我们找 username=wentao 的时候,可以列举出所有有 wentao 作为用户名的行的主键。然后拿这些主键去行存储(就是那个hashmap)里捞数据,就一捞一个准了。
谈到索引就不得不谈一下一个查询使用了两个字段,如何使用两个索引的问题。mysql的行为可以代表大部分主流数据库的处理方式:
基本上来说,经验表明有多个单字段的索引,最后数据库会选一最优的来使用。其余字段的过滤仍然是通过数据读取到内存之后,用predicate去判断的。也就是无法减少数据的读取量。
在这个方面基于inverted index的数据就非常有特点。一个是Elasticsearch为代表的lucene系的数据库。另外一个是新锐的druid数据库。
效果就是,这些数据库可以把单字段的filter结果缓存起来。多个字段的查询可以把之前缓存的结果直接拿过来做 AND 或者 OR 操作。
索引存在的必要是因为主存储没有提供直接的快速定位的能力。如果访问的就是数据库的主键,那么需要读取的数据也就非常少了。另外一个变种就是支持遍历的主键,比如hbase的rowkey。如果查询的是一个基于rowkey的范围,那么像hbase这样的数据库就可以支持只读取到这个范围内的数据,而不用读取不再这个范围内的额外数据,从而提高速度。这种加速的方式就是利用了主存储自身的物理分布的特性。另外一个更常见的场景就是 partition。比如 mysql 或者 postgresql 都支持分区表的概念。当我们建立了分区表之后,查找的条件如果可以过滤出分区,那么可以大幅减少需要读取的数据量。比 partition 更细粒度一些的是 clustered index。它其实不是一个索引(二级索引),它是改变了数据在主存储内的排列方式,让相同clustered key的数据彼此紧挨着放在一起,从而在查询的时候避免扫描到无关的数据。比 partition 更粗一些的是分库分表分文件。比如我们可以一天建立一张表,查询的时候先定位到表,再执行 SQL。比如 graphite 给每个 metric 创建一个文件存放采集来的 data point,查询的时候给定metric 就可以定位到一个文件,然后只读取这个文件的数据。
另外还有一点就是按行存储和按列存储的区别。按列存储的时候,每个列是一个独立的文件。查询用到了哪几个列就打开哪几个列的文件,没有用到的列的数据碰都不会碰到。反观按行存储,一张中的所有字段是彼此紧挨在磁盘上的。一个表如果有100个字段,哪怕只选取其中的一个字段,在扫描磁盘的时候其余99个字段的数据仍然会被扫描到的。
考虑一个具体的案例,时间序列数据。如何使用读取更少的数据的策略来提高检索的效率呢?首先,我们可以保证入库的时间粒度,维度粒度是正好是查询所需要的。如果查询需要的是5分钟数据,但是入库的是1分钟的,那么就可以先聚合成5分钟的再存入数据库。对于主存储的物理布局选择,如果查询总是针对一个时间范围的。那么把 timestamp 做为 hbase 的 rowkey,或者 mysql 的 clustered index 是合适。这样我们按时间过滤的时候,选择到的是一堆连续的数据,不用读取之后再过滤掉不符合条件的数据。但是如果在一个时间范围内有很多中数据,比如1万个IP,那么即便是查1个IP的数据也需要把1万个IP的数据都读取出来。所以可以把 IP 维度也编码到 rowkey 或者 clustered index 中。但是假如另外还有一个维度是 OS,那么查询的时候 IP 维度的 rowkey 是没有帮助的,仍然是要把所有的数据都查出来。这就是仅依靠主存储是无法满足各种查询条件下都能够读取更少的数据的原因。所以,二级索引是必要的。我们可以把时间序列中的所有维度都拿出来建立索引,然后查询的时候如果指定了维度,就可以用二级索引把真正需要读取的数据过滤出来。但是实践中,很多数据库并不因为使用了索引使得查询变快了,有的时候反而变得更慢了。对于 mysql 来说,存储时间序列的最佳方式是按时间做 partition,不对维度建立任何索引。查询的时候只过滤出对应的 partition,然后进行全 partition 扫描,这样会快过于使用二级索引定位到行之后再去读取主存储的查询方式。究其原因,就是数据本地化的问题了。
[page]
数据本地化
数据本地化的实质是软件工程师们要充分尊重和理解底层硬件的限制,并且用各种手段规避问题最大化利用手里的硬件资源。本地化有很多种形态
最常见的最好理解的本地化问题是网络问题。我们都知道网络带宽不是无限的,比本地磁盘慢多了。如果可能尽量不要通过网络去访问数据。即便要访问,也应该一次抓取多一些数据,而不是一次搞一点,然后搞很多次。因为网络连接和来回的开销是非常高的。这就是 data locality 的问题。我们要把计算尽可能的靠近数据,减少网络上传输的数据量。
这种带宽引起的本地化问题,还有很多。网络比硬盘慢,硬盘比内存慢,内存比L2缓存慢。做到极致的数据库可以让计算完全发生在 L2 缓存内,尽可能地避免频繁地在内存和L2之间倒腾数据。
另外一种形态的问题化问题是磁盘的顺序读和随机读的问题。当数据彼此靠近地物理存放在磁盘上的时候,顺序读取一批是非常快的。如果需要随机读取多个不连续的硬盘位置,磁头就要来回移动从而使得读取速度快速下降。即便是 SSD 硬盘,顺序读也是要比随机读快的。
基于尽可能让数据读取本地化的原则,检索应该尽可能地使用顺序读而不是随机读。如果可以的话,把主存储的row key或者clustered index设计为和查询提交一样的。时间序列如果都是按时间查,那么按时间做的row key可以非常高效地以顺序读的方式把数据拉取出来。类似地,按列存储的数据如果要把一个列的数据都取出来加和的话,可以非常快地用顺序读的方式加载出来。
二级索引的访问方式典型的随机读。当查询条件经过了二级索引查找之后得到一堆的主存储的 key,那么就需要对每个 key 进行一次随机读。即便彼此仅靠的key可以用顺序读做一些优化,总体上来说仍然是随机读的模式。这也就是为什么时间序列数据在 mysql 里建立了索引反而比没有建索引还要慢的原因。
为了尽可能的利用顺序读,人们就开始想各种办法了。前面提到了 mysql 里的一行数据的多个列是彼此紧靠地物理存放的。那么如果我们把所需要的数据建成多个列,那么一次查询就可以批量获得更多的数据,减少随机读取的次数。也就是把之前的一些行变为列的方式来存放,减少行的数量。这种做法的经典案例就是时间序列数据,比如可以一分钟存一行数据,每一秒的值变成一个列。那么行的数量可以变成之前的1/60。
但是这种行变列的做法在按列存储的数据库里就不能直接照搬了,有些列式数据库有column family的概念,不同的设置在物理上存放可能是在一起的也可能是分开的。对于 Elasticsearch 来说,要想减少行的数量,让一行多pack一些数据进去,一种做法就是利用 nested document。内部 Elasticsearch 可以保证一个 document 下的所有的 nested document是物理上靠在一起放在同一个 lucene 的 segment 内。
网络的data locality就比较为人熟知了。map reduce的大数据计算模式就是利用map在数据节点的本地把数据先做一次计算,往往计算的结果可以比原数据小很多。然后再通过网络传输汇总后做 reduce 计算。这样就节省了大量网络传输数据的时间浪费和资源消耗。现在 Elasticsearch 就支持在每个 data node 上部署 spark。由 spark 在每个 data node 上做计算。而不用把数据都查询出来,用网络传输到 spark 集群里再去计算。这种数据库和计算集群的混合部署是高性能的关键。类似的还有 storm 和 kafka 之间的关系。
网络的data locality还有一个老大难问题就是分布式大数据下的多表join问题。如果只是查询一个分布式表,那么把计算用 map reduce 表达就没有多大问题了。但是如果需要同时查询两个表,就意味着两个表可能不是在物理上同样均匀分布的。一种最简单的策略就是找出两张表中最小的那张,然后把表的内容广播到每个节点上,再做join。复杂一些的是对两个单表做 map reduce,然后按照相同的 key 把部分计算的结果汇集在一起。第三种策略是保证数据分布的方式,让两张表查询的时候需要用到的数据总在一起。没有完美的方案,也不大可能有完美的方案。除非有一天网络带宽可以大到忽略不计的地步。
更多的机器
这个就没有什么好说的了。多一倍的机器就多一倍的 CPU,可以同时计算更多的数据。多一倍的机器就多一倍的磁头,可以同时扫描更多的字节数。很多大数据框架的故事就是讲如何如何通过 scale out解决无限大的问题。但是值得注意的是,集群可以无限大,数据可以无限多,但是口袋里的银子不会无限多的。堆机器解决问题比升级大型机是要便宜,但是机器堆多了也是非常昂贵的。特别是 Hive 这些从一开始就是分布式多机的检索方案,刚开始的时候效率并不高。堆机器是一个乘数,当数据库本来单机性能不高的时候,乘数大并不能起到决定性的作用。
更高效的计算和计算实现
检索的过程不仅仅是磁盘扫描,它还包括一个可简单可复杂的变换过程。使用 hyperloglog,count min-sketch等有损算法可以极大地提高统计计算的性能。数据库的join也是一个经常有算法创新的地方。
计算实现就是算法是用C++实现的还是用java,还是python实现的。用java是用大Integer实现的,还是小int实现的。不同的语言的实现方式会有一些固定的开销。不是说快就一定要C++,但是 python 写 for 循环是显然没有指望的。任何数据检索的环节只要包含 python/ruby 这些语言的逐条 for 循环就一定快不起来了。
结论
希望这四点可以被记住,成为一种指导性的优化数据检索效率的思维框架。无论你是设计一个mysql表结构,还是优化一个spark sql的应用。从这四个角度想想,都有哪些环节是在拖后腿的,手上的工具有什么样的参数可以调整,让随机读变成顺序读,表结构怎么样设计可以最小化数据读取的量。要做到这一点,你必须非常非常了解工具的底层实现。而不是盲目的相信,xx数据库是最好的数据库,所以它一定很快之类的。如果你不了解你手上的数据库或者计算引擎,当它快的时候你不知道为何快,当它慢的时候你就更加无从优化了。
数据科学之 如何找到指标的最 佳分裂点的几个想法
1 问题定义
一类问题:
影响整体用户活跃度,的因素中有单次打开时长这一指标,
如何找到打开多久是比较好的阈值?
这个可以看成是一个有监督的寻找合理分裂点的过程,这里就抛砖引玉几种可能性
- 决策树来找分裂点
- 有监督分箱(卡方/决策树)
- 离散回归模型(比较好的一种)
- shap值
另一类问题(下篇给出最近的想法):
张三是一个连锁店的老板,他想知道每个门店店员做的好/坏,
光看销售额是最简单粗暴,比较有利的能不能看到店员的画像,
比如服务态度、工龄、所在区域等;
另外有没有一种可能,工龄从青年 -> 中年,销售额可以量化提升多少?
最终可以给每个门店设置KPI。
2 关联方法
2.1 决策树来找分裂点
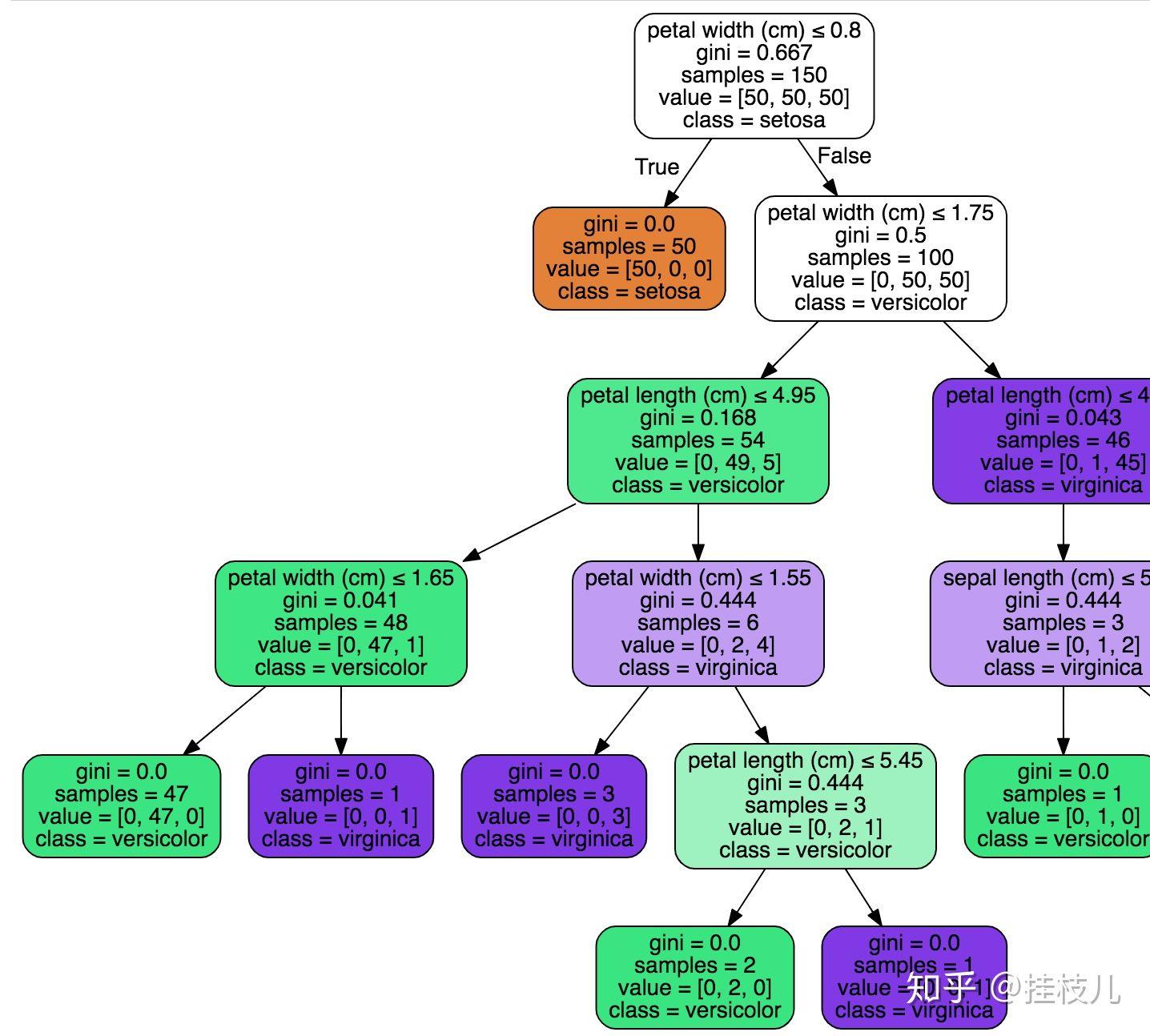
盗图来看一下:非常fancy的可视化决策树dtree_viz
这个是比较传统的决策树分裂的图,可以从其中看到重要特征的分裂点:
当然还有可视化效果更好的就是:
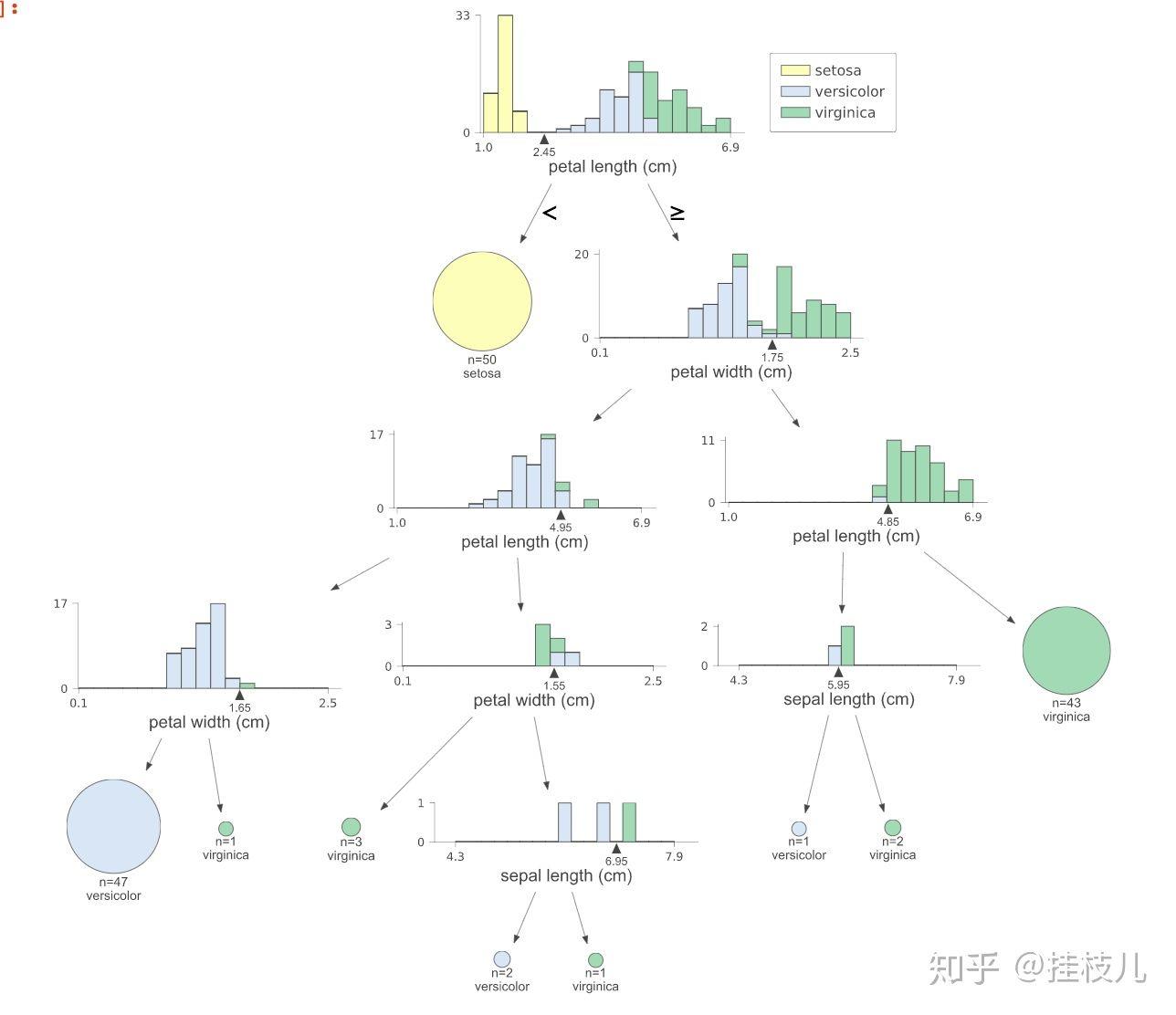
依照上面的寻找分裂点,那就是petal length这个指标,[1.75,4.85,4.95]是分割点;
当然这个分割点的由来是由GINI最小的作为分割点,而且有可能一个单一指标,可以细分很碎,取到什么层级是比较好的?
可以要从指标的覆盖度等角度来衡量取到什么粒度了。
2.2 有/无 监督分箱(等比/等宽-卡方/决策树)
参考:评分卡应用 - 利用Toad进行有监督分箱(卡方分箱/决策树分箱)
影响整体用户活跃度,的因素中有单次打开时长这一指标,
如何找到打开多久是比较好的阈值?
无监督分箱那就非常简单了,等比/等宽进行处理 单次打开时长 后,在每个分区计算用户活跃度的差异,来找到比较比较好的分裂点。
这里还有有监督的方式,也是一种比较科学的,用户活跃度(是否活跃1/0) ~ 单词打开时长,根据IV来寻找分割点,这里分割的几个准则:每箱样本量、固定箱数等来判定。

比如此时,依图可以这么划分:
单次打开时长,[0,5.5],占所有样本的35%,在这里面都是label = 2的样本;
单次打开时长[7.1,+ ),占所有样本的8%,这里面 y label的平均值为1.64
这里最佳的分裂点其实是可以“自我调节”出来的
2.3 离散回归模型(比较好的一种)
重复事件(表现形态:活跃、留存、复购)建模的案例学习笔记
来到文章的【1.3.2 PWP-GT 重复事件建模在看点业务中的实际应用】,可以看到:
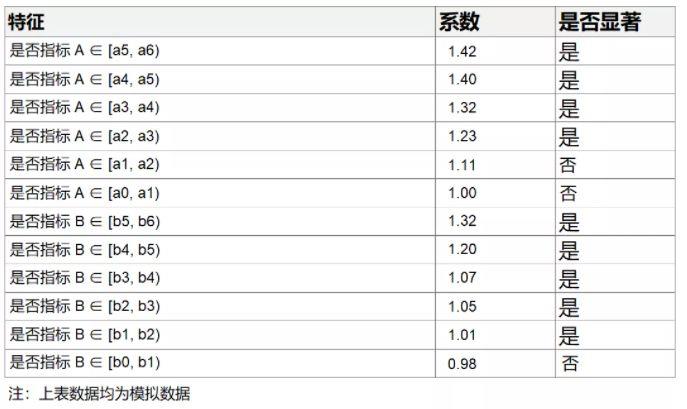
这里YY一下,比如打开时长a,均等切分为,[a0,a1,…,a6],可能实际含义是[0h,1h,…,5h],然后对活跃度=Y做回归,
这里的回归系数的显著性,就是指标合理的表现,
来YY解读一下这个图,[a0,a1],[a1,a2]是不显著的,其他都是显著的;代表,打开时长在2h以上的是明显的,这是一个非常重要的阈值。
而且,还可以量化出来说,如果打开时长在[a4,a5]([4h,5h])那么活跃度会比[a0,a1]高出40%
如果要在显著的时间里面再画一个阈值,可以观察系数的增长幅度,比如:
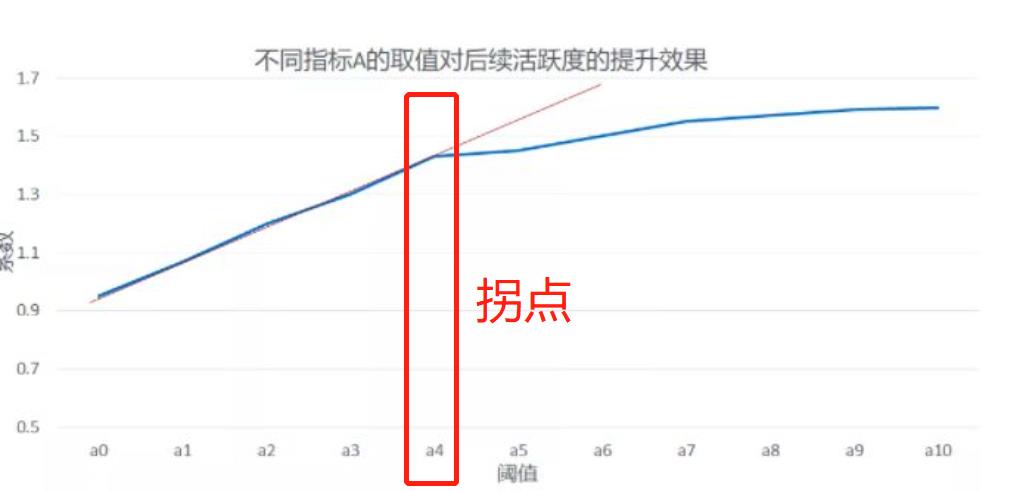
那a4,4H就是一个非常好的新阈值点;
所以离散回归是非常好的可以找到阈值、量化指标水平的方式。
2.4 shap值
重复事件(表现形态:活跃、留存、复购)建模的案例学习笔记在【2.2 指标阈值确定下腾讯看点与快手的差别】小节,有提到shap值的方式
用特征密度散点图:beeswarm:
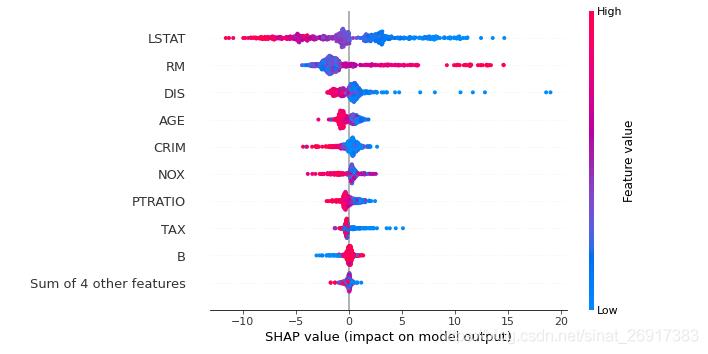
假设LSTAT这个指标,越大(红)可能导致SHAP约低,则选择蓝/红渐变那个阶段,作为阈值;
那么YY成这次的命题,RM是打开时长,整体Y是活跃度;
这里代表,打开时长越长(越红),对活跃度越有利(SHAP值为正);
分割点应该就是shap值=0时,打开时长的值,比如是3H,这里可以看到:
- 3H以上的用户比较少
- 3H以下的用户,比较多
以上是关于影响数据检索效率的几个因素的主要内容,如果未能解决你的问题,请参考以下文章