在shell编程中,怎样对每一行每一列的数据进行操作?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了在shell编程中,怎样对每一行每一列的数据进行操作?相关的知识,希望对你有一定的参考价值。
比如我有一个200行6列的文本文件,需要对每行每列的数据进行操作,之后再写入到另一个文件中。问题是怎样取出数据呢(先对第一行的每一个数据进行操作,完成之后将结果保存到另一个文本文件中;对第二行数据进行同样的操作。)?如果是C\C++语言就比较容易,shell刚刚接触,不会呢。先谢谢大家了。

使用如下结构也可以达到你的目的:
cat file.txt | while read line
do
#处理每行内容 "$line"
done
或者:
while read line
do
#处理每行内容 "$line"
done <file.txt
建议直接给出具体要求,给出源文件的格式示例以及最终要求达到的效果。追问
好的。文本流格式是:
1.1 0xD8130000 0x0 0x3 0x0 0x0
1.2 0xD8130000 0x4 0x7 0x0 0x0
上面这样的。
操作如下:
1、第一行,取出每一列的数据,有六个,分别赋值给六个变量,这六个变量与相应寄存器在内存中的数据进行对比,是否可读可写,比较之后将测试结果输出到另一个文本文件中,作为一行。
2、第一行处理完毕,接着第二行处理,方式与1是一样的。
srcFile=/path/file.txt
desFile=/path/output.txt
cat $srcFile | while read line
do
# Acquire all 6 data in a line and put into array
for i in `seq 6`
do
data[$i]=`echo "$line" | awk -v a=$i 'print $a'`
# 与相应寄存器在内存中的数据进行对比
# 将返回的测试结果字符串与上次结果字符串连接起来,中间用空格分隔
# 例如:ret="$ret $result"
done
ret=$ret:1 #Remove the 1st space
echo "$ret" >>$desFile
done
shell无法直接操作内存,”与相应寄存器在内存中的数据进行对比并输出测试结果“,这个只能通过调用外部工具来实现。
data[$i]=`echo "$line" | awk -v a=$i 'print $a'`
这行是打印每一列的数据,能够操作她吗?我尝试了只有源文件,将14、15行
注释掉,运行这个脚本,显示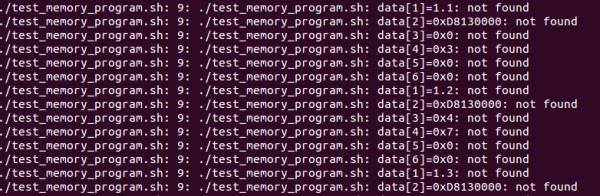

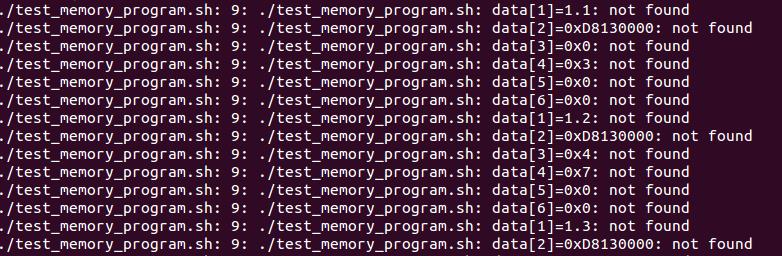

因为 ret 这个变量根本没赋值啊。ret=$ret:1 这句是对ret字符串做处理,如果字符串为空,是会出错的。需要先在循环里赋值,后面才能使用。
另外,not found是哪里来的?我没打印这些东西啊
嗯,明白了。关于not found,我也不知道怎么回事,输出就是这样的。也不知道是什么错误。
非常感谢您的解答啊,得好好的补补shell编程知识,呵呵。
对了,你用的是什么shell?
我试过,ret为空也不应该报错,有些shell如Ubuntu默认带的dash不支持数组,会报 Bad substitution 之类的错误。
将dash改为bash,参见我在下面这个问题的回答:http://zhidao.baidu.com/question/563952737?&oldq=1#answer-1414268701
cat file.txt | while read line
do
#处理每行内容 "$line"
done
或者:
while read line
do
#处理每行内容 "$line"
done <file.txt 参考技术B 用awk命令应该可以解决你的问题,不过你的问题再具体点就更好回答了本回答被提问者采纳
pyspark 获取一行中每一列的最新非空元素
【中文标题】pyspark 获取一行中每一列的最新非空元素【英文标题】:pyspark get latest non-null element of every column in one row 【发布时间】:2022-01-23 14:24:32 【问题描述】:让我用一个例子来解释我的问题: 我有一个数据框:
pd_1 = pd.DataFrame('day':[1,2,3,2,1,3],
'code': [10, 10, 20,20,30,30],
'A': [44, 55, 66,77,88,99],
'B':['a',None,'c',None,'d', None],
'C':[None,None,'12',None,None, None]
)
df_1 = sc.createDataFrame(pd_1)
df_1.show()
输出:
+---+----+---+----+----+
|day|code| A| B| C|
+---+----+---+----+----+
| 1| 10| 44| a|null|
| 2| 10| 55|null|null|
| 3| 20| 66| c| 12|
| 2| 20| 77|null|null|
| 1| 30| 88| d|null|
| 3| 30| 99|null|null|
+---+----+---+----+----+
我想要实现的是一个新的数据框,每一行对应一个code,并且对于每一列,我想要拥有最新的非空值(最高的day)。
在 pandas 中,我可以简单地做
pd_2 = pd_1.sort_values('day', ascending=True).groupby('code').last()
pd_2.reset_index()
得到
code day A B C
0 10 2 55 a None
1 20 3 66 c 12
2 30 3 99 d None
我的问题是,如何在 pyspark(最好是版本
到目前为止我尝试过的是:
from pyspark.sql import Window
import pyspark.sql.functions as F
w = Window.partitionBy('code').orderBy(F.desc('day')).rowsBetween(Window.unboundedPreceding, Window.unboundedFollowing)
## Update: after applying @Steven's idea to remove for loop:
df_1 = df_1 .select([F.collect_list(x).over(w).getItem(0).alias(x) for x in df_.columns])
##for x in df_1.columns:
## df_1 = df_1.withColumn(x, F.collect_list(x).over(w).getItem(0))
df_1 = df_1.distinct()
df_1.show()
输出
+---+----+---+---+----+
|day|code| A| B| C|
+---+----+---+---+----+
| 2| 10| 55| a|null|
| 3| 30| 99| d|null|
| 3| 20| 66| c| 12|
+---+----+---+---+----+
我不太满意,尤其是因为for loop。
【问题讨论】:
这能回答你的问题吗? How to select the item that has the greatest value in dataframe ? In Pyspark @Steven 谢谢。但我认为它会有同样的循环遍历所有列的问题:| 如果您的问题只是 for 循环,请将其更改为 select 中的列表理解 改进代码是个好主意:) 问题是最后一行将包含来自不同行的元素(使用相同的代码),而不仅仅是选择一行。我认为它不能使用单个row_number 函数来完成。但如果我错过了什么,请告诉我或写一个答案:)
【参考方案1】:
这是另一种使用数组函数和结构排序而不是窗口的方法:
from pyspark.sql import functions as F
other_cols = ["day", "A", "B", "C"]
df_1 = df_1.groupBy("code").agg(
F.collect_list(F.struct(*other_cols)).alias("values")
).selectExpr(
"code",
*[f"array_max(filter(values, x-> x.c is not null))['c'] as c" for c in other_cols]
)
df_1.show()
#+----+---+---+---+----+
#|code|day| A| B| C|
#+----+---+---+---+----+
#| 10| 2| 55| a|null|
#| 30| 3| 99| d|null|
#| 20| 3| 66| c| 12|
#+----+---+---+---+----+
【讨论】:
【参考方案2】:我认为您当前的解决方案非常好。如果您想要其他解决方案,可以尝试使用first/last 窗口函数:
from pyspark.sql import functions as F, Window
w = Window.partitionBy("code").orderBy(F.col("day").desc())
df2 = (
df.select(
"day",
"code",
F.row_number().over(w).alias("rwnb"),
*(
F.first(F.col(col), ignorenulls=True)
.over(w.rowsBetween(Window.unboundedPreceding, Window.unboundedFollowing))
.alias(col)
for col in ("A", "B", "C")
),
)
.where("rwnb = 1")
.drop("rwnb")
)
结果:
df2.show()
+---+----+---+---+----+
|day|code| A| B| C|
+---+----+---+---+----+
| 2| 10| 55| a|null|
| 3| 30| 99| d|null|
| 3| 20| 66| c| 12|
+---+----+---+---+----+
【讨论】:
以上是关于在shell编程中,怎样对每一行每一列的数据进行操作?的主要内容,如果未能解决你的问题,请参考以下文章