The show must go on: Fundamental data plane connectivity services for dependable SDNs
Posted Ptolemy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了The show must go on: Fundamental data plane connectivity services for dependable SDNs相关的知识,希望对你有一定的参考价值。
摘要
软件定义网络(SDN)架构提出了一个问题,即如何处理通过控制平面的间接定向不够快或不可能的情况。为了提供高可用性、连接性、灵活性,可靠的SDNs还必须在数据平面上支持基本功能。特别是,SDNs应实现带内网络遍历的功能,例如在存在链路故障时查找故障转移路径。本文提出了三种基本不同的机制:简单的无状态机制、基于包标记的高效机制和基于交换机动态状态的机制。我们将展示如何在今天的SDN中实现这些机制,并讨论不同的应用程序。
1. 介绍
1.1. 动机
软件定义网络(SDN)体系结构区分由转发交换机组成的数据平面和由一个或多个软件控制器组成的控制平面。将数据平面元素的控制外包给软件控制器,简化了网络管理,并引入了新的可扩展性和优化机会,例如,在流量工程方面。
然而,通过控制平面的间接定向在通信开销和延迟方面都会付出代价。事实上,与网络中的直接反应相比,控制平面中对数据平面事件的反应时间可能要慢几个数量级:特别是对于故障的恢复,缓慢的反应是有问题的。更糟糕的是,通过控制平面的间接寻址甚至可能是不可能的:控制器可能是暂时或永久无法访问的,例如,由于网络分区、计算机崩溃,甚至是由于恶意攻击。
这在今天是有问题的,因为计算机网络已经成为一个关键的基础设施,应该提供高可用性。在过去的几年里,研究人员和实践者在设计更可靠和可用的SDN控制平面方面做了很多工作。在这些设计中,冗余(也可能是地理分布的)控制器以协调的方式管理网络。
尽管这些都有助于提高控制平面的性能,但单靠冗余控制器并不能保证SDN的可用性。首先,通过控制器的重定向所引起的额外延迟可能仍然太高,即使控制器在附近。此外,如果在带内实现,即使是在分布式控制平面上,我们也面临一个bootstrap(v.独自创立;靠一己之力做成;附属于;与…相联系)问题:交换机和控制器之间的通信信道必须通过数据平面建立和维护。
因此,本文认为,高可用和可靠的软件定义网络需要在数据平面上提供基本的连接服务。特别是,数据平面应提供带内网络遍历或故障安全路由的功能:故障后计算备用路径的能力(也称为故障转移)。此外,它应该支持连接性检查。
1.2 带内(inband)机制的挑战
我们不是第一个观察到带内机制好处的人[12-14]。事实上,许多现代计算机网络已经包含了支持本地快速故障转移机制实现的原语:直接处理数据平面中故障的机制。
例如,在数据中心,使用等成本多路径(ECMP)路由自动故障转移到另一条最短路径;在广域网中,基于多协议标签交换(MPLS)的网络使用快速重路由来处理数据平面故障。在sdn上下文(context)中,最新的OpenFlow版本引入了条件规则,其转发行为取决于交换机的本地状态。未来的OpenFlow版本可能会包含更多的功能,甚至支持维护动态网络状态,例如参见p4和openstate上下文中的计划。
然而,实现网络遍历或计算故障转移路径是一项挑战,即使可以定义OpenFlow本地快速故障转移规则。主要有两个原因:
1)OpenFlow故障转移规则必须提前计算和安装,即不知道实际故障。
2)故障转移规则只能取决于交换机的本地状态,即本地链路故障。本地重新路由决策可能不是最优的,特别是在网络其他部分出现额外故障的情况下。
1.3稳健带内遍历的例子
本地快速故障转移机制本质上必须能够执行故障保护路由的网络遍历:它应该查找从源到目标的路由,即使失败。这种稳健的带内网络遍历也可以是有用的数据平面服务,例如,检查网络连接。
理想情况下,网络遍历提供了最大程度的稳健性,在这种意义上,只要s和d属于同一物理连接的组件,则从s到d的任何包都将独立于链路故障的位置和数目到达其目的地。
目前对于在SDN中实现稳健的带内网络传输的可行性和效率知之甚少,本文将讨论这个主题。特别是,从其他类型的网络(如mpls)已知的稳健路由算法,有时不可能在没有附加功能的情况下,在交换机上实现,或效率低(例如,需要大的包头),因此无法扩展到大型网络。
1.4我们的贡献
本文研究了带内网络穿越的可行性和有效性,这是为了让SDN更加可靠,提供更先进的数据平面服务,所需的基本组成部分,例如稳健的路由和连接测试。
我们提出了一个全面的方法,探索概念上不同的解决方案,在管理费用和性能方面提供不同的权衡(tradeoff):
1) 无状态机制:
2) 标记机制
3) 有状态机制:
最后,我们讨论了稳健的带内网络遍历的应用,包括稳健的路由和有效的连接检查。
2. 背景和模型
2.1 SDN和OpenFlow
我们的工作是由软件定义的网络典型推动的,特别是OpenFlow,当今主要的SDN协议。本节提供了有关OpenFlow的必要背景知识(重点介绍常用的版本1.3)。OpenFlow基于match-action的概念:OpenFlow开关存储由match和action部分组成的规则(由控制器安装)。例如,一个action可以定义一个端口,匹配的数据包应该被转发到该端口,或者更改一个头字段(例如,添加或更改一个标签)。
新的流量入口既可以主动安装,也可以被动安装。在被动情况下,当一个流量包到达一个交换机时,如果没有匹配规则,将使用表未命中项。默认情况下,在表丢失时,数据包被转发到控制器。给定这样一个packetin事件,控制器将创建一个新规则并将新的flow条目推送到这个开关。然后,交换机将对数据包应用此规则。在主动式情况下,流量输入会提前推送到交换机。
每个OpenFlow开关存储一个或多个流表,每个表都包含一组规则(也称为流条目)。流表形成一条管道,流条目按优先级排序:到达交换机的数据包首先按照表0中优先级最高的规则进行检查:将数据包的字段与该规则的匹配字段进行比较,如果匹配,则执行一些指令(操作);然后,低优先级规则被选中。根据表0处理的结果,数据包可以发送到管道中的其他流量表。具体来说,指令可用于定义要访问的附加表(goto指令),修改要应用的操作集(通过追加、删除或修改操作),或立即对数据包应用某些操作。元数据字段可用于在表之间交换信息。可以通过推送和弹出标签和标签(例如MPLS和虚拟局域网(vlan)字段)从包中插入或删除头的一部分。、
一般来说,包可以与它的任何头字段匹配,并且可以通配符(wildcarded)和有时位屏蔽(bitmasked)(例如,元数据字段是可屏蔽的)。如果没有匹配的规则,则丢弃数据包。使用多个流表(与单个流表相比)可以简化管理并提高性能。
我们的稳健遍历算法利用了组表,特别是OpenFlow 1.3中引入的快速故障转移(FF)概念。组表由组条目组成,每个组条目包含一个或多个操作bucket。对于快速故障转移类型的组条目,每个bucket与特定端口(或组)关联,并且只能使用与活动端口(或组)关联的bucket。正如我们将看到的,我们可以利用这个机制来控制交换机的转发行为,这取决于端口的活跃度。对我们来说,另一个重要的组类型是选择组:选择组提供了将某个操作bucket链接到端口(或组)的可能性,并提供了不同的选择类型(例如,循环或全部)。
2.2模型
对于一个可靠的SDN来说,稳健的带内网络遍历是基本组成部分,也是有用的数据平面网络服务。在本文中,我们探讨了实现非常健壮的带内网络遍历的可行性和安全性:我们认为是否能容忍任意数量的链路故障,意味着这个遍历机制稳健性的高低( We say that a traversal mechanism is maximally robust if it tolerates an arbitrary number of link failures):每当可能时,总是找到源和目的地之间的路由,即,只要底层网络连接好
为了在OpenFlow中实现健壮的遍历,我们巧妙地使用了OpenFlow本地快速故障转移机制。但是,为健壮的遍历计算这样的本地故障转移表不是普通的,因为在发生故障之前需要分配转发规则,并且这些规则只能依赖于本地活动性信息。
我们有时会用G0表示初始网络(在故障发生之前),用G1表示故障之后的剩余“子图”。如何在不知道实际故障情况(即G1)的情况下实现健壮的遍历和计算G0的故障转移表是一个算法问题。
正如我们将在本文中展示的,在今天的OpenFlow协议中实现最大稳健遍历是可能的。然而,不同的技术会带来不同的侧重,可能是路由长度(就跳数而言,G1中最长的转发路径是多长?)、规则和表的复杂性(每个节点需要多少额外的表和规则来实现健壮遍历机制?)或是标签复杂度(标签需要多少页眉空间?)。
在下面,n将表示网络交换机的总数(在G0和G1中相同),E将表示一组链路(总数:m= |E|),并且Δ将指G0中的最大节点度。我们将使用下标,例如,Δi,表示给定的节点Vi的相应值,并假定节点的端口由1到Δi索引。
3. 无状态稳健带内网络遍历
我们首先观察到一个简单而稳健的网络遍历可以在OpenFlow中使用(伪)随机游动来实现。随机游动很有吸引力,因为它们不需要存储或维护有关当前网络配置的信息,无论是在交换机上,还是在数据包中。
我们的方案的主要优点,此后称为RWalk,是它可以为任何链路故障提供一个替代路径(只要剩余的图是连接的)。我们可以使用快速故障转移和选择组类型特性在标准OpenFlow中实现RWalk。我们将bucket选择方法设置为随机。与快速故障转移类型FF类似,选择组类型提供了将操作bucket链接到端口(或组)的可能性,并且只有在该端口处于活动状态时才能选择bucket。当触发遍历的包到达交换机时,交换机从组表(参见表1)向其应用Gr 1。在这个组条目(选择类型)中,交换机将随机选择链接到实时交换机端口的存储桶。因此,在每个交换机上,遍历包被转发到随机的实时端口。
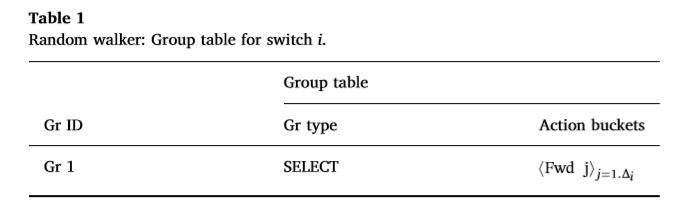
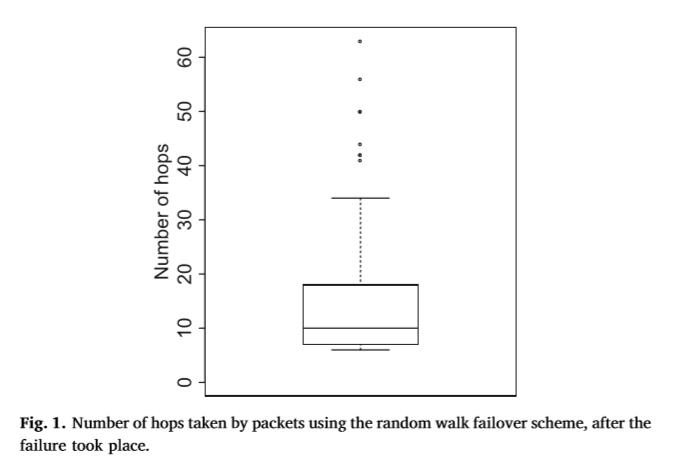
注意,实现遍历机制只需要一个组表条目。这一点很重要,因为交换机内存是一个关键资源。但是,路由长度相对较高,且受高方差影响,请参见图1中的定性结果:该图基于一个小的IGEN拓扑(Delaunay三角形),由连接到它们的20个交换机和主机组成,每个链路具有2 ms的延迟。使用pings,每次100包,我们分析在网络两端连接的两台主机之间的RTT,在故障发生前后(有一条链路沿着主机之间的默认路径断开)。在故障之前,在主机之间使用最短路径(它由5个跳组成)。
这种差异激励了本文开发的更具确定性的故障转移方案。
4. 带目标的可预测遍历
尽管前一节中提出的随机网络遍历方案以其简单性和健壮性吸引人,但它可能会导致长且不可预测的遍历路径。更糟糕的是,来自同一个微流量的不同数据包可能会采用不同的路径,可能会引入许多数据包重新派生,这会对传输控制协议(TCP)的吞吐量产生负面影响。在下面的文章中,我们展示了通过在包标签中存储网络遍历信息可以实现更高效的遍历。
在下面,我们首先提出一个简单的深度优先搜索(dfs)的遍历方案,称为ineff-DFS。虽然它是确定性的,ineff-DFS的缺点是它需要很大的头空间(n是线性的,网络大小)。我们稍后将介绍一种更有效的头空间算法,即eff-DFS,只需要O(D·logn)的空间,其中D是网络的直径:且D通常很小。
Ineff-Dfs算法以深度优先的方式遍历网络,隐式地构造生成树。为此,对于每个节点vi,包头pkt.vi.par的某个部分被保留,用来存储vi的父p(vi):第一次从中接收包的节点(由新传入的端口指示)。还有一个保留的位置来存储pkt.vi.cur变量,该变量表示算法当前正在遍历的交换机的输出端口(图2)。
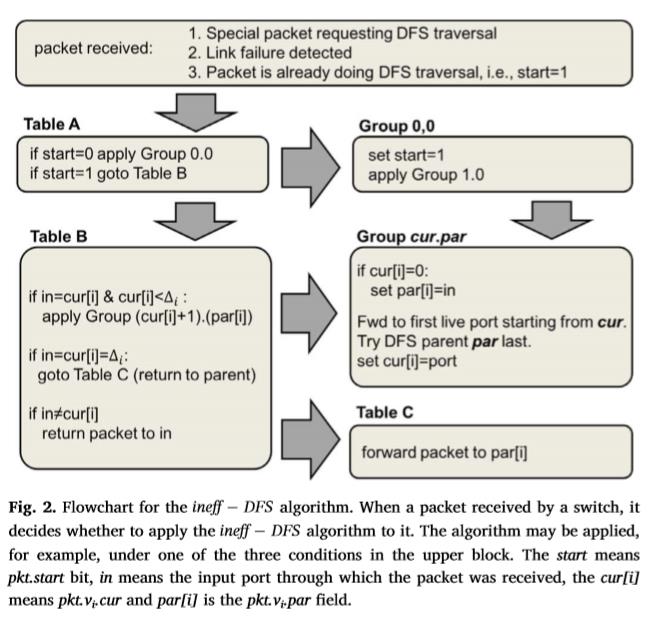
算法1中以伪代码的形式总结了ineff-DFS算法。这里,pkt start=0表示遍历尚未开始。(取决于用例,在后面看到,遍历可以根据请求明确地启动,或者是为现有的包触发一个失败的链接而触发的)。例如,一个开关可以被编程来匹配一个分组中的特定的“codeword”,然后发起遍历。或者,交换机可以使用常规路由规则,直到检测到传出端口的故障,这将触发遍历。

在接收到遍历触发包时,节点通过将pkt.start设置为1并尝试从下一个活动端口(从端口1开始)发送包(即,启动遍历)来启动算法。节点尝试将数据包转发给每个邻居,只有当所有邻居(连接到活动端口)都被遍历时,节点才会将数据包返回给其父节点。
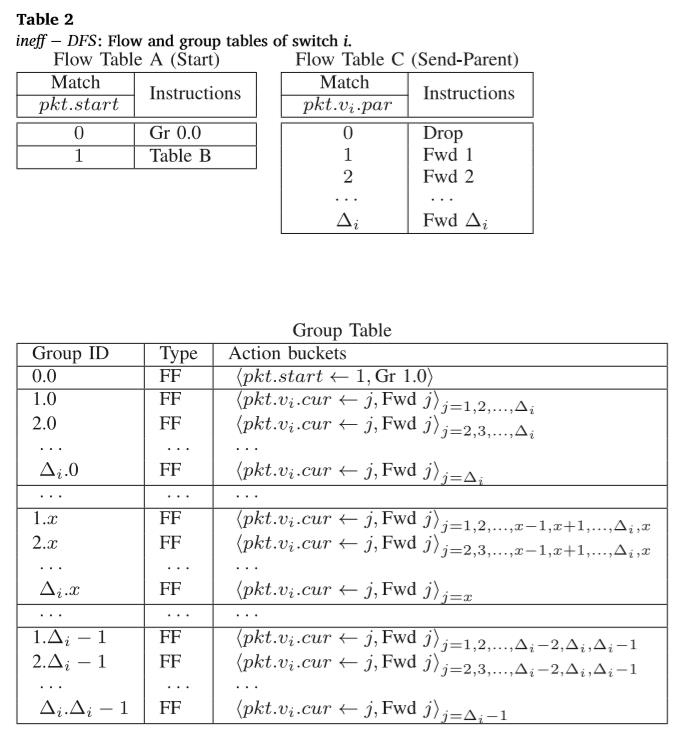
Ineff-Dfs的实现包括三个流量表和一个组表(见表2)。表A检查遍历是否已经开始,如果没有,则启动它。组表中的所有组都是快速故障转移类型,这意味着每个操作bucket都耦合到一个端口(在我们的情况下是转发端口),并且第一个具有工作端口的bucket应用于该数据包。
每个组Gr cur.par,cur∈[1,…Δi],par∈[0,…Δi-1],我试图找到下一个工作端口:它从端口cur开始,跳过父端口par,并仅在所有先前端口都失败时转发回父端口par。注意当pkt v par=Δi时的情况,将使用GR cur.0组处理。
一旦分组Gr 1.0转发了一个分组,它的pkt.start位将被设置为1,因此,当下一个交换机接收到它时,它将被传递到表B;表B将根据pkt.vi.cur和pkt.vi.par字段应用相应的分组。如果pkt.vi.cur为0,表B将把输入端口保存到pkt.vi.par字段。当遍历所有邻居时,使用表C将包返回给父节点。该算法的详细OpenFlow表如表2所示。
注意,遍历算法不包括触发机制,因为它取决于特定的应用程序。例如,在故障转移应用程序中,交换机可以使用附加的组表条目,该条目将首先尝试给定目的地的默认路由,如果该端口失败,则该条目中的下一个bucket将数据包发送到实际启动遍历算法的Gr 0.0条目。另一个应用程序可以通过发送带有特定预先定义的“codeword”的包来请求网络遍历(例如,对于某些数据/统计数据收集或连接检查)。一旦交换机匹配此codeword,它就可以通过将数据包发送到表A(即,如果匹配(codeword),然后转到表A)来启动遍历。
4.1更有效率的带目标遍历
鉴于这个基本方案,我们现在提出一个更有效的遍历。我们提出了一种分布式的DFS类似遍历,其中允许分组执行DFS直至最大深度maxdist。假设maxdist至少是网络的直径(即,在g1中,发生故障之后),这样的遍历保证遍历所有节点。

算法的伪代码如算法2所示。数据包头包括由maxdist多个单元格组成的标记T,以及全局参数:pkt.start和pkt.dist。标记T的每个单元格由三个字段组成:T[·].ID,当前使用此单元格的节点的ID,T[·].par,在遍历中连接节点父节点的端口,以及T[·].cur,连接到当前正在遍历的节点的后续端口。注意,在这个方案中只需要分配maxdist单元。
pkt.start字段指示遍历过程是否已启动。它由第一个接收到触发遍历的包的节点设置。此节点称为遍历的根。pkt.dist字段跟踪数据包距遍历根的距离。
当交换机vi接收到数据包时,它首先检查pkt.start字段以检查遍历是否已开始,如果没有,则启动它:首先,交换机初始化全局参数pkt.start和pkt.dist。然后,它指示它将使用标记t中的第一个单元格,将其到父节点的端口设置为0(根节点没有父节点)。并将t[pkt.dist].cur和输出端口设置为1(即遍历从端口1开始的后续端口)。
然后我们检查交换机设置的输出端口是否正常工作,或者是否连接到其父端口。在这两种情况下,交换机都将尝试下一个端口(而在第25行循环)。如果所有潜在端口(从out到Δi,交换机vi的最后一个端口)都已尝试,则交换机已完成对其所有后续端口的遍历,并将数据包返回给父端口。在将数据包返回到父级之前,交换机通过将t[pkt.dist].id字段设置为0并将当前路径长度减少1(第32、33行),从标记t中移除自身。当一个包被发送到下一个后继包时,到根的距离增加(第35行)。
如果交换机接收已经执行遍历的分组(即pkt.start是1),则它检查分组从根的距离是否达到其最大值,或者是否在最后一个单元t[pkt.dist]之前已经出现在T的某个地方(参见第9行)。条件的第一部分意味着数据包已经达到了从根的最大允许距离,而第二部分意味着交换机已经在当前的遍历路径中,而不是在最后的位置。在这两种情况下,数据包都会返回到接收它的端口。
接下来,交换机检查它是否第一次收到这个数据包,在这种情况下,它初始化t[pkt.dist]单元,并使用其字段保存连接到交换机父节点的端口(第13行)。然后,在第16行和第17行,交换机将输出端口设置为需要遍历的下一个后续端口,并将该端口保存在t[pkt.dist].cur字段中。如果下一个端口大于Δi,这意味着遍历了所有后续端口,并将数据包发送到父端口(第19-24行)。注意,当根需要返回包到它的父节点(它不存在)时,这意味着遍历被结束,并且包应该被丢弃(第21行和第31行)。
在OpenFlow中实现eff-DFS遍历是非常重要的。总的来说,有流动表和分组表。为了使组表表示更紧凑,我们使用以下符号来表示k个操作bucket的序列:<action(j)>j= j1, j2,,,jk。也就是说,在序列中的每个bucket中,j 替换为序列中的下一个编号j1, j1,,,jk。组ID的格式为cur.par,其中cur是数据包中T[pkt.dist].cur的值,即当前遍历的端口,par是T[pkt.dist].par的值。该算法的详细OpenFlow表如表3所示。
表A检查遍历过程是否已经启动,如果没有,则从GROUP表调用GRr0.0来启动它。Gr 0.0初始化数据包中所需的字段,并调用Gr1.0(即链接它),后者将尝试将数据包转发到下一个工作端口,从端口1开始。表B和C在算法2中的第9行实现了该条件。表E实现了第19-24行,即将数据包发送到其父级。第29-33行用于使用组 Δi+1.par中的组表将消息发送到父级。在这种情况下,父端口之前的端口失败
每个组Gr cur.par,cur∈[1,…Δi],par∈[0,…Δi-1],都试图找到下一个工作端口:它从端口cur开始并跳过父端口par。如果所有端口都失败了,额外的bucket Gr Δi+1.par将把包转发回父par。注意,在父级为0的情况下,没有额外的存储桶:遍历的根没有父级。
4.2 备选方案:迭代深度DFS
很容易将我们的方法扩展到头空间高效的“广度优先”遍历,或者更具体地说:迭代深度DFS(IDDFS)遍历。基本思想是逐个增加最大距离。我们以maxdist = 1开始DFS算法:只探索遍历根的1跳邻域。一旦数据包返回到根目录,而不是丢弃它(DFS方案的默认行为),根目录将增加maxdist并重新启动DFS遍历。这次将遍历根的2跳邻域。以同样的方式,我们继续将maxdist增加到网络G1(故障后的结果网络)的直径。最终,当节点被发现时,整个网络将被遍历。
5. 带状态的短路径
我们已经证明,使用标记将状态存储在包头中的可能性对于克服随机游走方案的一些缺点是有用的。在本节中,我们将进一步探讨利用状态信息进行遍历的可能性。特别是,我们展示了,也许令人惊讶的是,在OpenFlow遍历中,使用包标记并不是引入状态的唯一方法。实际上,使用标准的OpenFlow协议可以在交换机上实现简单的状态机,我们将相应的状态称为带内寄存器。此外,我们还提出了一种有趣且新颖的机制,使用mac地址对路径进行编码,以完全透明的方式将状态存储在连接到网络的主机中。我们将此状态称为基于主机的寄存器。例如,可以利用这种状态来存储最近在网络遍历期间发现的最短路径。
5.1 带内寄存器
我们的OpenFlow带内寄存器实现了多个(小)计数器,这些计数器存储在交换机中,在处理不同的数据包时支持获取和增量操作。在下面,我们将使用术语register和counter互换。在OpenFlow管道中处理数据包时,可以读取和更新带内寄存器。带内寄存器可以使用带有循环桶选择策略log2k组的组表(OpenFlow 1.3的可选功能)来实现,每个组包含2个操作bucket(见表4)。每个组代表计数器的一个位,即,对于从0到k-1计数的计数器,我们需要log2k位(组)。通过应用所有log k组Gr x来获取计数器,计数器的值将写入数据包的标记pkt.cnt.x(x∈[1,…,log k])。
为了在获取之后保留计数器的值,需要执行以下步骤。获取计数器后,它的所有位都将被刷新(由于组的循环类型),因此,我们现在需要再次刷新它们,以便使计数器返回其原始值。这可以通过再次应用所有组Gr x(x∈[1,…,log k])来实现。
现在让我们描述如何为带内寄存器设置新值。假设获取的计数器值按位存储在数据包的字段pkt.cnt.x中,所需的计数器值存储在元数据new.x中,其中x∈[1,…,log k]。现在我们创建一个表,它匹配pkt.cnt.x和new.x的所有可能组合(这将需要k的平方条目)。该操作将由应用组Gr y组成,其中y∈{ i|pkt.cnt.i = new.i }。后者是正确的,因为第一次提取已经反映了位y的值,因此我们需要另一个flip来使计数器的位y等于new.y。
此实现使用log2k位来匹配flow表(flow表用于保留或设置计数器值),每个条目最多需要log k操作。
请注意,寄存器实现(获取和设置)需要两次访问组表,与flow表交错;但是,常见的OpenFlow开关仅在flow表管道的末端支持组表访问。我们可以通过使每个包在交换机中被处理两次来克服这个限制。这可以通过物理互连两个交换机端口(即,创建物理环回)来实现,或者如果设置了包中的某个位,则通过请求相邻交换机返回包来实现。此外,我们预计,未来OpenFlow交换机将支持更多的灵活的组表访问和更多的现场行动。
5.2. 基于主机的寄存器
接下来,我们提出了一个有趣的在网络中存储状态的替代方案:基于主机的寄存器。基于主机的寄存器利用主机的arp缓存来存储每个目的地的信息(例如,在遍历期间学习到的有效路由路径),这些信息是根据mac地址编码的。该解决方案对主机(和IP层)完全透明。
通过向主机发送一条(无偿的)ARP应答消息来写入寄存器,其中指定(目的地)主机作为源IP,寄存器值作为源MAC(src_mac)。由于寄存器值被设置为目的地MAC(dst_mac),并且可以由OpenFlow交换机使用,因此对每个发送的包自动执行寄存器的读取。
接下来,我们将描述如何使用这些寄存器来存储和跟踪路径。首先,我们展示如何将短路径聚合并打包成arp回复消息。稍后,我们将展示如何遵循DST Mac字段中编码的路径。为了简单起见,我们假设16端口节点的最大长度为12的路径,可表示为48位。
5.2.1 基于主机的寄存器的聚合路径
为了聚合基于主机的寄存器的路径,路径上的每个节点都将in端口附加到当前路径数组,从而允许反向重放路径。如表5所述,追加操作根据当前存储为VLAN标记的跳数执行:它包括将src mac复制到元数据字段(使用openflow 1.5 copy field操作)、将4位设置为in port的4位编码,并将元数据复制回src mac。
5.2.2 转发路径储存于基于主机的寄存器
当主机将数据包发送到某个目标主机(由其IP表示)时,数据包将路径保存为DST_MAC。为了跟随路径,路径上的每个节点提取当前端口并转发到此端口。如表6所述,每个跃点的提取是反向执行的(与聚合顺序相反),vlan标记用于指示dst_mac中要视为下一个跃点端口的当前效果集。
6.应用
6.1 故障转移路径
6.1.1 使用普通遍历
6.1.2 改进版本:带内寄存器的生成树
6.1.3 带内和主机寄存器的最短路径
6.2 连接查询
6.2.1 一次性查询
6.2.2 连接性服务
7.相关工作
8.结论
以上是关于The show must go on: Fundamental data plane connectivity services for dependable SDNs的主要内容,如果未能解决你的问题,请参考以下文章
Spark is not running in local mode, therefore the checkpoint directory must not be on the local……(代码
我的OpenGL学习进阶之旅解决着色器编译错误:#version directive must occur on the first line of the shader
我的OpenGL学习进阶之旅解决着色器编译错误:#version directive must occur on the first line of the shader
AS使用lombok注解报错:Annotation processors must be explicitly declared now. The following dependencies on
codeforces Wunder Fund Round 2016 (Div. 1 + Div. 2 combined) B Guess the Permutation