机器学习里的kernel是指啥?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习里的kernel是指啥?相关的知识,希望对你有一定的参考价值。
参考技术A先给个定义:核函数K(kernel function)就是指K(x, y) = <f(x), f(y)>,其中x和y是n维的输入值,f(•) 是从n维到m维的映射(通常而言,m>>n)。<x, y>是x和y的内积(inner product),严格来说应该叫欧式空间的标准内积,也就是很多人常说的点积。kernel其实就是帮我们省去在高维空间里进行繁琐计算的“简便运算法”。甚至,它能解决无限维空间无法计算的问题!因为有时f(•)会把n维空间映射到无限维空间去,对此我们常常束手无策,除非是用kernel,尤其是RBF kernel(K(x,y) = exp(-||x-y||^2) )。在有kernel之前,做machine learning的典型的流程应该是:data --> features --> learning algorithm,但kernel给我们提供了一个alternative,那就是,我们不必定义从data到feature的映射函数,而是可以直接kernel(data) --> learning algorithm,也可以是data --> features --> kernel(features) --> learning algorithm。所以虽然我们看到kernel常被应用在SVM(SVM中的kernel应该是后一种用法,后文再说),但其实要用到内积的learning algorithm都可以使用kernel。“用到内积的learning algorithm”其实并不少见,不信你可以想一想最普通不过的linear classifier/regressor有没有一个步骤是计算特征向量(feature vectors)。简单说就是一些函数,这些函数在某些领域具有特定的功能,而且性能比较好,就称为核(函数)了,svm中有核(函数),卷积网络中的filter有时也称为核。初学SVM时常常可能对kernel有一个误读,那就是误以为是kernel使得低维空间的点投射到高位空间后实现了线性可分。其实不然。这是把kernel和feature space transformation混为了一谈。(这个错误其实很蠢,只要你把SVM从头到尾认真推导一遍就不会犯我这个错。)还是简单回顾一下吧。SVM就是 y = w\'•φ(x) + b,其中φ(x)是特征向量(feature vectors),并且是φ(x)使得数据从低维投射到高位空间后实现了线性可分。而kernel是在解对偶问题的最优化问题时,能够使φ(x)更方便地计算出来,特别是φ(x)维数很高的时候。
解释的是将低维空间中线性不可分的数据变换到高维空间找到一个线性可分的分类的过程,并不能与kernel trick等价,更不能与kernel等价。Kernel Trick只是解决这个变换到高维后如何避开维数影响进行有效率的计算的问题,本身并不是投射到高维的手段,Kernel Function(核函数)只是一个关于特征向量的函数,本质是变换后的空间中的内积,这个函数的构造和引入的初衷只是为了提高SVM在高维的计算效率。另外,总是滥用空间想象能力和类比能力试图理解classification和regression并不是一个很好的习惯。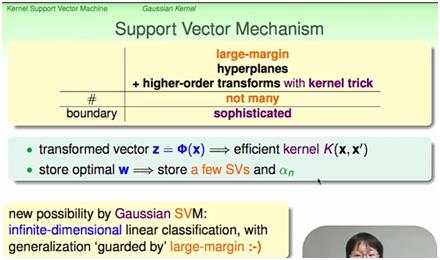
这个其实是一个数学上的叫法。数学上把比如乘起来这样的积分里面的g(x,y)叫成一个核函数。这东西最早是出现在积分方程里面的。然后因为你看到这个积分自然可以联系到所谓的希尔伯特空间(内积就是这样一个形式,L2空间里面内积就是这样一个积分,只不过这个希尔伯特空间里面的内积加了一个核函数,离散的时候你可以理解成加了一个正定矩阵),所以后面g(x,y)就和可能是你指的SVM里面的那个核函数联系在一起了,一般SVM里面写成K(x,y)(顺便SVM用的是RKHS,就是是再生核的希尔伯特空间,换言之内积可以把函数给换出来,我不知道这么说是不是有点不太明白)。实在弄不懂你看点泛函分析就明白了。其实这些东西在数学上都是相通的,就是说白了核心就是Mercer定理(学过泛函的肯定不会陌生)。你要是学过泛函的话去看看泛函书上面的这个定理,或者看这个:Mercer\'s theorem。当然SVM还加上了一大票的二次优化的内容就是了。
lstm序列指啥
参考技术A LSTM(Long Short-Term Memory)是长短期记忆网络,是一种时间递归神经网络,适合于处理和预测时间序列中间隔和延迟相对较长的重要事件。LSTM 已经在科技领域有了多种应用。基于 LSTM 的系统可以学习翻译语言、控制机器人、图像分析、文档摘要、语音识别图像识别、手写识别、控制聊天机器人、预测疾病、点击率和股票、合成音乐等等任务。
工作原理
LSTM区别于RNN的地方,主要就在于它在算法中加入了一个判断信息有用与否的"处理器",这个处理器作用的结构被称为cell。
一个cell当中被放置了三扇门,分别叫做输入门、遗忘门和输出门。一个信息进入LSTM的网络当中,可以根据规则来判断是否有用。只有符合算法认证的信息才会留下,不符的信息则通过遗忘门被遗忘。
说起来无非就是一进二出的工作原理,却可以在反复运算下解决神经网络中长期存在的大问题。目前已经证明,LSTM是解决长序依赖问题的有效技术,并且这种技术的普适性非常高,导致带来的可能性变化非常多。各研究者根据LSTM纷纷提出了自己的变量版本,这就让LSTM可以处理千变万化的垂直问题。
以上是关于机器学习里的kernel是指啥?的主要内容,如果未能解决你的问题,请参考以下文章