2020-05-26:Springboot 连接oracle数据库配置
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2020-05-26:Springboot 连接oracle数据库配置相关的知识,希望对你有一定的参考价值。
参考技术A 1.在application.properties配置账号密码等信息
server.port=8080
server.servlet.context-path=/share-center-report
spring.thymeleaf.prefix=classpath:/templates/
spring.datasource.type=com.alibaba.druid.pool.DruidDataSource
spring.datasource.druid.driver-class-name=oracle.jdbc.driver.OracleDriver
spring.datasource.url=
spring.datasource.username=
spring.datasource.password=
2.引入依赖
<dependency>
<groupId>com.oracle</groupId>
<artifactId>ojdbc6</artifactId>
<version>11.2.0.1</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.10</version>
</dependency>
3.在启动类配置扫描mapper
@MapperScan("com.example.demo1.mapper")
4.编写demo测试
public interface testMapper
@Select("select * from test_data")
List<TestVo> test();
/ 自定义realm程序 /
public class MyRealm extends AuthorizingRealm
@Resource
private testMapper testMapper;
@Override
protected AuthorizationInfo doGetAuthorizationInfo(PrincipalCollection principalCollection)
System.out.println("授权");
return null;
Linux高性能服务器—子线程使用poll处理连接 I/O事件
将 acceptor 上的连接建立事件和已建立连接的 I/O 事件分离,形成所谓的主 - 从 reactor 模式。
主 - 从 reactor 模式
主 - 从这个模式的核心思想是,主反应堆线程只负责分发 Acceptor 连接建立,已连接套接字上的 I/O 事件交给 sub-reactor 负责分发。其中 sub-reactor 的数量,可以根据 CPU 的核数来灵活设置。
多个反应堆线程同时在工作,这大大增强了 I/O 分发处理的效率,并且同一个套接字事件分发只会出现在一个反应堆线程中,这会大大减少并发处理的锁开销。
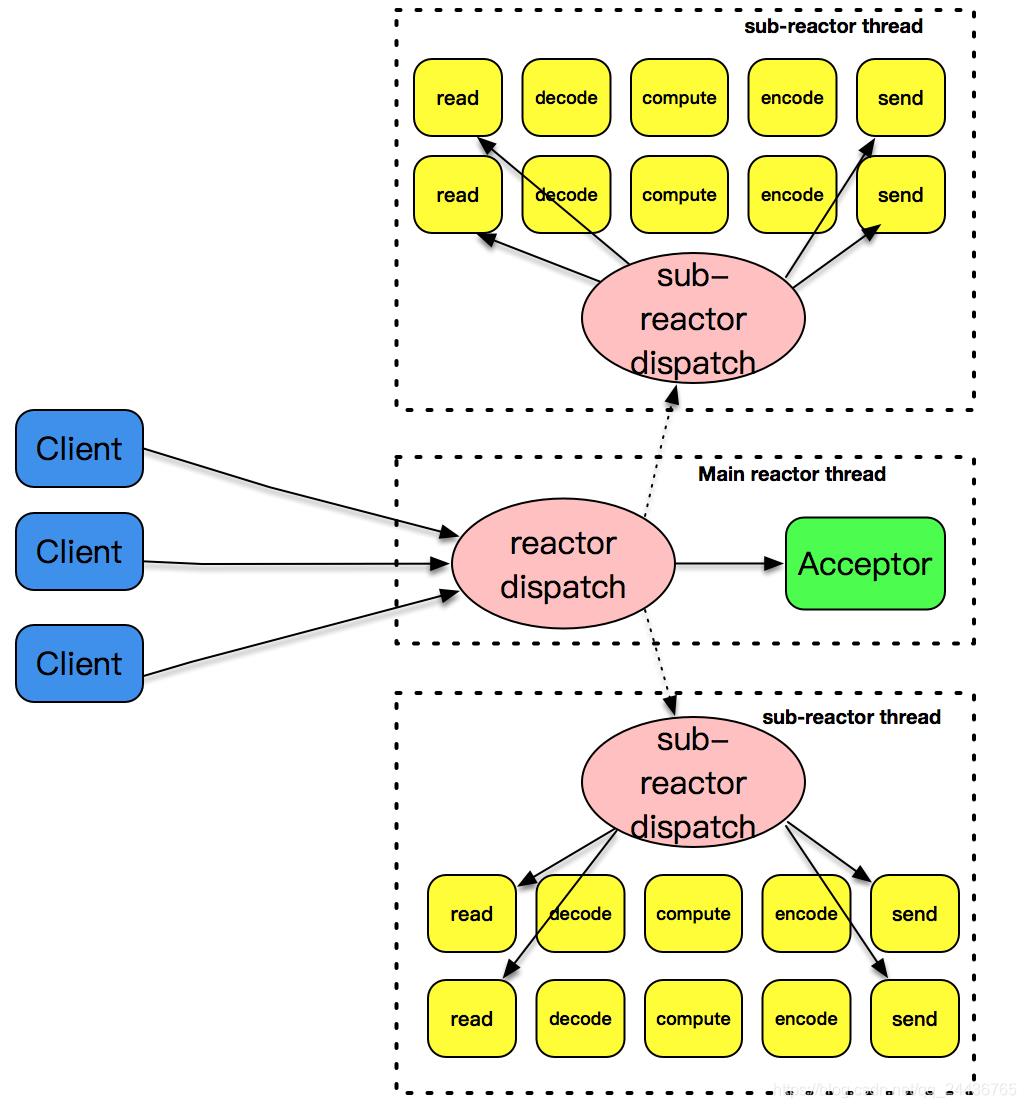
来解释一下这张图,我们的主反应堆线程一直在感知连接建立的事件,如果有连接成功建立,主反应堆线程通过 accept 方法获取已连接套接字,接下来会按照一定的算法选取一个从反应堆线程,并把已连接套接字加入到选择好的从反应堆线程中。
主反应堆线程唯一的工作,就是调用 accept 获取已连接套接字,以及将已连接套接字加入到从反应堆线程中。不过,这里还有一个小问题,主反应堆线程和从反应堆线程,是两个不同的线程,如何把已连接套接字加入到另外一个线程中呢?这是高性能网络程序框架要解决的问题,在后面,将会给出这个问题的答案。
主 - 从 reactor+worker threads 模式
如果说主 - 从 reactor 模式解决了 I/O 分发的高效率问题,那么 work threads 就解决了业务逻辑和 I/O 分发之间的耦合问题。把这两个策略组装在一起,就是实战中普遍采用的模式。大名鼎鼎的 Netty,就是把这种模式发挥到极致的一种实现。不过要注意 Netty 里面提到的 worker 线程,其实就是我们这里说的从 reactor 线程,并不是处理具体业务逻辑的 worker 线程。
下面贴的一段代码就是常见的 Netty 初始化代码,这里 Boss Group 就是 acceptor 主反应堆,workerGroup 就是从反应堆。而处理业务逻辑的线程,通常都是通过使用 Netty 的程序开发者进行设计和定制,一般来说,业务逻辑线程需要从 workerGroup 线程中分离,以便支持更高的并发度。
public final class TelnetServer {
static final int PORT = Integer.parseInt(System.getProperty("port", SSL? "8992" : "8023"));
public static void main(String[] args) throws Exception {
//产生一个reactor线程,只负责accetpor的对应处理
EventLoopGroup bossGroup = new NioEventLoopGroup(1);
//产生一个reactor线程,负责处理已连接套接字的I/O事件分发
EventLoopGroup workerGroup = new NioEventLoopGroup(1);
try {
//标准的Netty初始,通过serverbootstrap完成线程池、channel以及对应的handler设置,注意这里讲bossGroup和workerGroup作为参数设置
ServerBootstrap b = new ServerBootstrap();
b.group(bossGroup, workerGroup)
.channel(NioServerSocketChannel.class)
.handler(new LoggingHandler(LogLevel.INFO))
.childHandler(new TelnetServerInitializer(sslCtx));
//开启两个reactor线程无限循环处理
b.bind(PORT).sync().channel().closeFuture().sync();
} finally {
bossGroup.shutdownGracefully();
workerGroup.shutdownGracefully();
}
}
}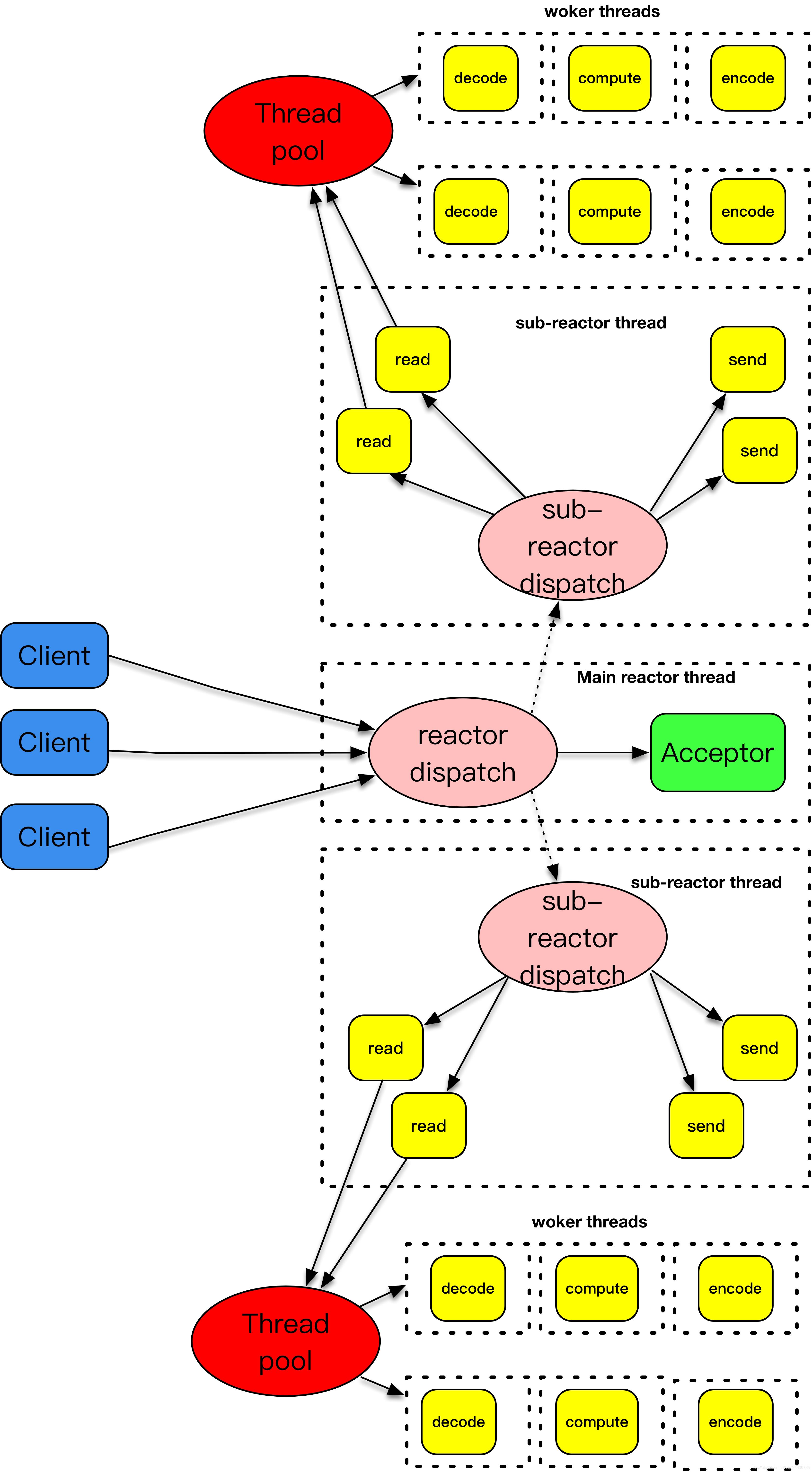
这张图解释了主 - 从反应堆下加上 worker 线程池的处理模式。主 - 从反应堆跟上面介绍的做法是一样的。和上面不一样的是,这里将 decode、compute、encode 等 CPU 密集型的工作从 I/O 线程中拿走,这些工作交给 worker 线程池来处理,而且这些工作拆分成了一个个子任务进行。encode 之后完成的结果再由 sub-reactor 的 I/O 线程发送出去。
样例程序
#include "lib/acceptor.h"
#include "lib/common.h"
#include "lib/event_loop.h"
#include "lib/tcp_server.h"
char rot13_char(char c) {
if ((c >= 'a' && c <= 'm') || (c >= 'A' && c <= 'M'))
return c + 13;
else if ((c >= 'n' && c <= 'z') || (c >= 'N' && c <= 'Z'))
return c - 13;
else
return c;
}
//连接建立之后的callback
int onConnectionCompleted(struct tcp_connection *tcpConnection) {
printf("connection completed\\n");
return 0;
}
//数据读到buffer之后的callback
int onMessage(struct buffer *input, struct tcp_connection *tcpConnection) {
printf("get message from tcp connection %s\\n", tcpConnection->name);
printf("%s", input->data);
struct buffer *output = buffer_new();
int size = buffer_readable_size(input);
for (int i = 0; i < size; i++) {
buffer_append_char(output, rot13_char(buffer_read_char(input)));
}
tcp_connection_send_buffer(tcpConnection, output);
return 0;
}
//数据通过buffer写完之后的callback
int onWriteCompleted(struct tcp_connection *tcpConnection) {
printf("write completed\\n");
return 0;
}
//连接关闭之后的callback
int onConnectionClosed(struct tcp_connection *tcpConnection) {
printf("connection closed\\n");
return 0;
}
int main(int c, char **v) {
//主线程event_loop
struct event_loop *eventLoop = event_loop_init();
//初始化acceptor
struct acceptor *acceptor = acceptor_init(SERV_PORT);
//初始tcp_server,可以指定线程数目,这里线程是4,说明是一个acceptor线程,4个I/O线程,没一个I/O线程
//tcp_server自己带一个event_loop
struct TCPserver *tcpServer = tcp_server_init(eventLoop, acceptor, onConnectionCompleted, onMessage,
onWriteCompleted, onConnectionClosed, 4);
tcp_server_start(tcpServer);
// main thread for acceptor
event_loop_run(eventLoop);
}你可能会问,这么简单就完成了主、从线程的配置?这其实是设计框架需要考虑的地方,一个框架不仅要考虑性能、扩展性,也需要考虑可用性。可用性部分就是程序开发者如何使用框架。如果我是一个开发者,我肯定关心框架的使用方式是不是足够方便,配置是不是足够灵活等。
像这里,可以根据需求灵活地配置主、从反应堆线程,就是一个易用性的体现。当然,因为时间有限,我没有考虑 woker 线程的部分,这部分其实应该是应用程序自己来设计考虑。网络编程框架通过回调函数暴露了交互的接口,这里应用程序开发者完全可以在 onMessage 方法里面获取一个子线程来处理 encode、compute 和 encode 的工作,像下面的示范代码一样。
//数据读到buffer之后的callback
int onMessage(struct buffer *input, struct tcp_connection *tcpConnection) {
printf("get message from tcp connection %s\\n", tcpConnection->name);
printf("%s", input->data);
//取出一个线程来负责decode、compute和encode
struct buffer *output = thread_handle(input);
//处理完之后再通过reactor I/O线程发送数据
tcp_connection_send_buffer(tcpConnection, output);
return以上是关于2020-05-26:Springboot 连接oracle数据库配置的主要内容,如果未能解决你的问题,请参考以下文章