将两条sql的查询结果拼接在一起显示
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了将两条sql的查询结果拼接在一起显示相关的知识,希望对你有一定的参考价值。
sql语句1:
(SELECT mc ,COUNT(hz_id) AS day_zy_avg, COUNT(hz_id) AS mouth_zy_avg FROM h_zyxx hz RIGHT JOIN h_kes hk
on hk.id = hz.ks_id and hz.cybz = 0 and hz.zyrq>='2009-1-1' and hz.zyrq<='2009-12-30' GROUP BY hk.mc) ;
sql语句2:
(SELECT mc ,COUNT(hz_id) AS day_cy_avg, COUNT(hz_id) AS mouth_cy_avg FROM h_zyxx hz RIGHT JOIN h_kes hk
on hk.id = hz.ks_id and hz.cybz = 1 and hz.cyrq>='2009-1-1' and hz.cyrq<='2009-12-30' GROUP BY hk.mc)
想达到的效果
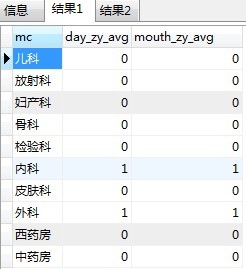
拼接代码如下:
select * from
(
select * from a)a1,
select * from b)a2,
)a3
延展阅读:
SQL简介
SQL语言,是结构化查询语言(Structured Query Language)的简称。SQL语言是一种数据库查询和程序设计语言,用于存取数据以及查询、更新和管理关系数据库系统;同时也是数据库脚本文件的扩展名。
简单介绍
SQL语言,是结构化查询语言(Structured Query Language)的简称。SQL语言是一种数据库查询和程序设计语言,用于存取数据以及查询、更新和管理关系数据库系统;同时也是数据库脚本文件的扩展名。SQL语言是高级的非过程化编程语言,允许用户在高层数据结构上工作。它不要求用户指定对数据的存放方法,也不需要用户了解具体的数据存放方式,所以具有完全不同底层结构的不同数据库系统可以使用相同的结构化查询语言作为数据输入与管理的接口。SQL语言语句可以嵌套,这使他具有极大的灵活性和强大的功能。
应用信息
结构化查询语言SQL(STRUCTURED QUERY LANGUAGE)是最重要的关系数据库操作语言,并且它的影响已经超出数据库领域,得到其他领域的重视和采用,如人工智能领域的数据检索,第四代软件开发工具中嵌入SQL的语言等。
编辑本段支持标准
SQL 是1986年10 月由美国国家标准局(ANSI)通过的数据库语言美国标准,接着,国际标准化组织(ISO)颁布了SQL正式国际标准。1989年4月,ISO提出了具有完整性特征的SQL89标准,1992年11月又公布了SQL92标准,在此标准中,把数据库分为三个级别:基本集、标准集和完全集。
select T1.mc,T1.day_zy_avg,T1.mouth_zy_avg,T2.day_zy_avg,T2.mouth_zy_avg
from
(SELECT mc ,COUNT(hz_id) AS day_zy_avg, COUNT(hz_id) AS mouth_zy_avg FROM h_zyxx hz RIGHT JOIN h_kes hk
on hk.id = hz.ks_id and hz.cybz = 0 and hz.zyrq>='2009-1-1' and hz.zyrq<='2009-12-30' GROUP BY hk.mc) as T1
join
(SELECT mc ,COUNT(hz_id) AS day_cy_avg, COUNT(hz_id) AS mouth_cy_avg FROM h_zyxx hz RIGHT JOIN h_kes hk
on hk.id = hz.ks_id and hz.cybz = 1 and hz.cyrq>='2009-1-1' and hz.cyrq<='2009-12-30' GROUP BY hk.mc) as T2
on T1.mc = T2.mc本回答被提问者和网友采纳 参考技术B SELECT
mc ,
SUM( CASE WHEN hz.cybz = 0 THEN 1 ELSE 0 END ) AS day_zy_avg,
SUM( CASE WHEN hz.cybz = 0 THEN 1 ELSE 0 END ) AS mouth_zy_avg ,
SUM( CASE WHEN hz.cybz = 1 THEN 1 ELSE 0 END ) AS day_cy_avg,
SUM( CASE WHEN hz.cybz = 1 THEN 1 ELSE 0 END ) AS mouth_cy_avg
FROM
h_zyxx hz
RIGHT JOIN h_kes hk
on hk.id = hz.ks_id
and hz.cyrq>='2009-1-1'
and hz.cyrq<='2009-12-30'
GROUP BY hk.mc
根据你目前的 sql , CASE WHEN 这么折腾一下, 就好了。 参考技术C 通过在表里同名连接两个表 参考技术D 在oracle里面可以使用decode方法来解决。
Mysql查询将查询的结果进行更新
用sql语句将 两条sql语句查出来的数据 进行更新update set 表 set 字段 in 第一条sql语句(351条数据) where id in (第二条sql语句(351条数据)) -------这种格式执行不成功,请教大家 这条更新语句 该咋写呢

有时候我们会不小心对一个大表进行了 update,比如说写错了 where 条件......
此时,如果 kill 掉 update 线程,那回滚 undo log 需要不少时间。如果放置不管,也不知道 update 会持续多久。
那我们能知道 update 的进度么?
实验
我们先创建一个测试数据库:

快速创建一些数据:

连续执行同样的 SQL 数次,就可以快速构造千万级别的数据:

查看一下总的行数:

我们来释放一个大的 update:

然后另起一个 session,观察 performance_schema 中的信息:
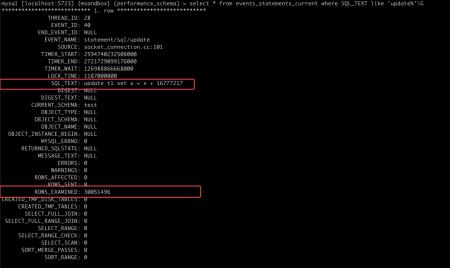
可以看到,performance_schema 会列出当前 SQL 从引擎获取的行数。
等 SQL 结束后,我们看一下 update 从引擎总共获取了多少行:
可以看到该 update 从引擎总共获取的行数是表大小的两倍,那我们可以估算:update 的进度 = (rows_examined) / (2 * 表行数)
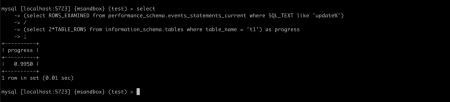
💡小贴士
information_schema.tables 中,提供了对表行数的估算,比起使用 select count(1) 的成本低很多,几乎可以忽略不计。
那么是不是所有的 update,从引擎中获取的行数都会是表大小的两倍呢?这个还是要分情况讨论的,上面的 SQL 更新了主键,如果只更新内容而不更新主键呢?我们来试验一下:
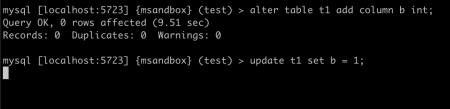
等待 update 结束,查看 row_examined,发现其刚好是表大小:
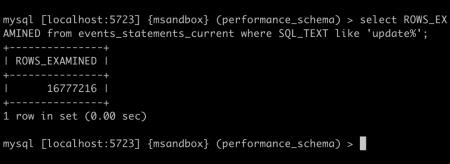
那我们怎么准确的这个倍数呢?
一种方法是靠经验:update 语句的 where 中会扫描多少行,是否修改主键,是否修改唯一键,以这些条件来估算系数。
另一种方法就是在同样结构的较小的表上试验一下,获取倍数。
这样,我们就能准确估算一个大型 update 的进度了。
参考技术A update a set aa = '1' where ab = ( select ab from b);测试过了 可以通过
但是这个语句只有在 b表中只有一条记录的时候是准确的
如果b表中有多条记录 那你得在子查询中查询指定的某一个 ab 列的值 才是准确的!追问
我用了存储过程,你这种只适合简单的更新,还有 你后面ab如果是多个值怎么办?
update a set aa = '1' where ab in ( select ab from b);
你后面等于号必须改成IN
以上是关于将两条sql的查询结果拼接在一起显示的主要内容,如果未能解决你的问题,请参考以下文章