b站电脑如何关闭弹幕
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了b站电脑如何关闭弹幕相关的知识,希望对你有一定的参考价值。
参考技术A 退出全屏播放视频下方有 弹幕关闭开启按钮 参考技术B
01 首先运行打开哔哩哔哩电脑版,找到你喜欢的视频打开。任选,或是在排行榜后的搜索框中搜索你喜欢的视频关键词。

02 哔哩哔哩电脑版打开后没关闭的弹幕效果:虽然我们可以随时了解其他网友观看当时情节的想法,但是太多弹幕会影响观看,所以需要我们将视频的弹幕给关掉。
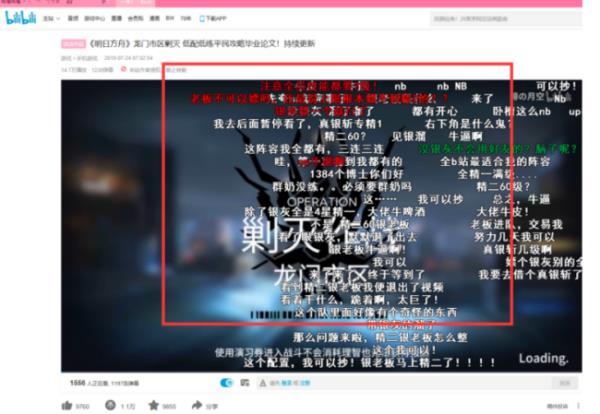
03 我们直接选择图中箭头指示的【弹】单击即可关闭了。
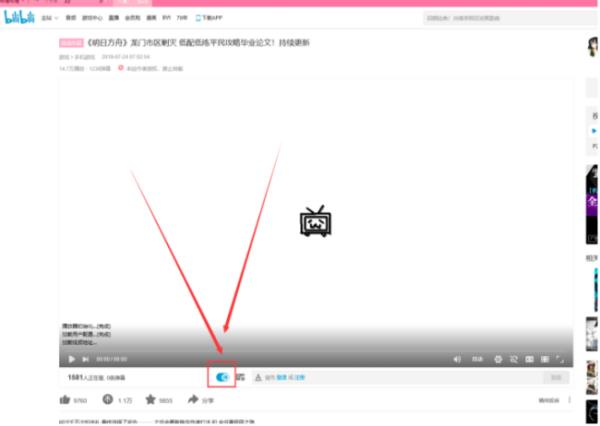
04 关闭后我们就可以看到当前界面非常清晰地显示了原页面,这个样子还是比较清爽的,如果大家想看弹幕还可以单击【弹】打开弹幕哦。
Python爬取分析B站动漫《柯南》弹幕,从数据中分析接下来的剧情
前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
作者:栗科技
一、爬取介绍
利用Chrome浏览器抓包可知,B站的弹幕文件以XML文档式进行储存,如下所示(共三千条实时弹幕)
其URL为:
http://comment.bilibili.com/183362119.xml数字183362119则代表该视频专属ID,通过改变数字即可得到相应的弹幕文件。打开第1集的视频,查看源码,如下图所示。
不难看出,CID则是对应着各个视频的ID,接下来用正则提取即可。
完整爬取代码如下
import requests
import re
from bs4 import BeautifulSoup as BS
import os
path=‘C:/Users/dell/Desktop/柯南‘
if os.path.exists(path)==False:
os.makedirs(path)
os.chdir(path)
def gethtml(url,header):
r=requests.get(url,headers=header)
r.encoding=‘utf-8‘
return r.text
def crawl_comments(r_text):
txt1=gethtml(url,header)
pat=‘"cid":(d+)‘
chapter_total=re.findall(pat,txt1)[1:-2]
count=1
for chapter in chapter_total:
url_base=‘http://comment.bilibili.com/{}.xml‘.format(chapter)
txt2=gethtml(url_base,header)
soup=BS(txt2,‘lxml‘)
all_d=soup.find_all(‘d‘)
with open(‘{}.txt‘.format(count),‘w‘,encoding=‘utf-8‘) as f:
for d in all_d:
f.write(d.get_text()+‘
‘)
print(‘第{}话弹幕写入完毕‘.format(count))
count+=1
if __name__==‘__main__‘:
url=‘https://www.bilibili.com/bangumi/play/ep321808‘
header={‘user-agent‘:‘Opera/12.80 (Windows NT 5.1; U; en) Presto/2.10.289 Version/12.02‘}
r_text=gethtml(url,header)
crawl_comments(r_text)最终的全部弹幕文件都在桌面的"柯南"文件下
注:这里共爬取到980个弹幕文件。【B站的柯南自941集后就跳到994集(大会员才能观看的)。虽然目前更新到1032话,但并没有1032集内容,如下图所示】
二、弹幕可视化
1.主要人物讨论总次数分析
(1)统计人数总次数
注: role.txt是主要人物名文件(需考虑到弹幕一般不会对人物的全名进行称呼,多数使用的是昵称,否则可能与实际情况相差较大。)
import jieba
import os
import pandas as pd
os.chdir(‘C:/Users/dell/Desktop‘)
jieba.load_userdict(‘role.txt‘)
role=[ i.replace(‘
‘,‘‘) for i in open(‘role.txt‘,‘r‘,encoding=‘utf-8‘).readlines()]
txt_all=os.listdir(‘./柯南/‘)
txt_all.sort(key=lambda x:int(x.split(‘.‘)[0])) #按集数排序
count=1
def role_count():
df = pd.DataFrame()
for chapter in txt_all:
names={}
data=[]
with open(‘./柯南/{}‘.format(chapter),‘r‘,encoding=‘utf-8‘) as f:
for line in f.readlines():
poss=jieba.cut(line)
for word in poss:
if word in role:
if names.get(word) is None:
names[word]=0
names[word]+=1
df_new = pd.DataFrame.from_dict(names,orient=‘index‘,columns=[‘{}‘.format(count)])
df = pd.concat([df,df_new],axis=1)
print(‘第{}集人物统计完毕‘.format(count))
count+=1
df.T.to_csv(‘role_count.csv‘,encoding=‘gb18030‘)(2)可视化
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams[‘font.sans-serif‘]=[‘kaiti‘]
plt.style.use(‘ggplot‘)
df=pd.read_csv(‘role_count.csv‘,encoding=‘gbk‘)
df=df.fillna(0).set_index(‘episode‘)
plt.figure(figsize=(10,5))
role_sum=df.sum().to_frame().sort_values(by=0,ascending=False)
g=sns.barplot(role_sum.index,role_sum[0],palette=‘Set3‘,alpha=0.8)
index=np.arange(len(role_sum))
for name,count in zip(index,role_sum[0]):
g.text(name,count+50,int(count),ha=‘center‘,va=‘bottom‘,)
plt.title(‘B站名侦探柯南弹幕——主要人物讨论总次数分布‘)
plt.ylabel(‘讨论次数‘)
plt.show()
虽说是万年小学生,柯南还是有变回新一的时候,且剧情也并不只是"找犯人—抓犯人"。接下来从数据的角度来,扒扒一些精彩剧情集数。
2.柯南变回新一集数统计
考虑到部分集数中新一是在回忆中出现的,为减少偏差,将讨论的阈值设为250次,绘制如下分布图
其讨论次数结果及剧集名如下表所示
有兴趣的朋友可以码一下,除235集外,均是柯南变回新一的集数。
相关代码如下:
df=pd.read_csv(‘role_count.csv‘,encoding=‘gbk‘)
df=df.fillna(0).set_index(‘episode‘)
xinyi=df[df[‘新一‘]>=250][‘新一‘].to_frame()
print(xinyi) #新一登场集数
plt.figure(figsize=(10,5))
plt.plot(df.index,df[‘新一‘],label=‘新一‘,color=‘blue‘,alpha=0.6)
plt.annotate(‘集数:50,讨论次数:309‘,
xy=(50,309),
xytext=(40,330),
arrowprops=dict(color=‘red‘,headwidth=8,headlength=8)
)
plt.annotate(‘集数:206,讨论次数:263‘,
xy=(206,263),
xytext=(195,280),
arrowprops=dict(color=‘red‘,headwidth=8,headlength=8)
)
plt.annotate(‘集数:571,讨论次数:290‘,
xy=(571,290),
xytext=(585,310),
arrowprops=dict(color=‘red‘,headwidth=8,headlength=8)
)
plt.hlines(xmin=df.index.min(),xmax=df.index.max(),y=250,linestyles=‘--‘,colors=‘red‘)
plt.legend(loc=‘best‘,frameon=False)
plt.xlabel(‘集数‘)
plt.ylabel(‘讨论次数‘)
plt.title(‘工藤新一讨论次数分布图‘)
plt.show()以讨论次数最多的572集,绘制词云图(剔除了高频词"新一",防止遗漏其他信息)如下所示:
从图中可看出,出现频率较高地词有整容、服部、声音、爱情等。(看来凶手是整成了新一的模样进行犯罪的,还有新兰的感情戏在里面,值得一看)
3.主线集数内容分析
主线剧情主要是围绕着组织成员(琴酒、伏特加、贝尔摩德)展开,绘制分布图如下:
plt.figure(figsize=(10,5))
names=[‘琴酒‘,‘伏特加‘,‘贝姐‘]
colors=[‘#090707‘,‘#004e66‘,‘#EC7357‘]
alphas=[0.8,0.7,0.6]
for name,color,alpha in zip(names,colors,alphas):
plt.plot(df.index,df[name],label=name,color=color,alpha=alpha)
plt.legend(loc=‘best‘,frameon=False)
plt.annotate(‘集数:{},讨论次数:{}‘.
format(df[‘贝姐‘].idxmax(),int(df[‘贝姐‘].max())),
xy=(df[‘贝姐‘].idxmax(),df[‘贝姐‘].max()),
xytext=(df[‘贝姐‘].idxmax()+30,df[‘贝姐‘].max()),
arrowprops=dict(color=‘red‘,headwidth=8,headlength=8)
)
plt.xlabel(‘集数‘)
plt.ylabel(‘讨论次数‘)
plt.title(‘酒厂成员讨论次数分布图‘)
plt.hlines(xmin=df.index.min(),xmax=df.index.max(),y=200,linestyles=‘--‘,colors=‘red‘)
plt.ylim(0,400)
#输出主线剧集
mainline=set(list(df[df[‘贝姐‘]>=200].index)+list(df[df[‘琴酒‘]>=200].index)) #伏特加可忽略不计
print(mainline)
从上图分析可知,组织成员的行动基本一致,其中贝姐(贝尔摩德)的人气在三人中是较高的,特别是在375集(与黑暗组织直面对决系列),讨论次数高达379。此外,统计其讨论次数大于200次的集数,结果如下:
以讨论次数最高的375集为内容,绘制词云图(剔除了高频词"贝姐",防止遗漏其他信息)如下
从图中可知,天使、琴酒、干妈、心疼、狙击手等词汇出现频率较高。从词频较低的败北主线中可以看出,这次酒厂行动应该是失败告终。
以上是关于b站电脑如何关闭弹幕的主要内容,如果未能解决你的问题,请参考以下文章