14、match all 等查询类型,多条件组合查询和利用filter进行查询的优化
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了14、match all 等查询类型,多条件组合查询和利用filter进行查询的优化相关的知识,希望对你有一定的参考价值。
参考技术A 主要内容:match all 等查询类型,多条件组合查询和利用filter进行查询的优化,还简单介绍了排序以及字符串排序查询所有:
匹配相关field的文本:
将一段搜索的文本使用到多个field上,例如 搜索test_field和test_field1上的匹配test的document
可以放在query和filter里面,例子:查询年龄大于35岁的员工
会将搜索词作为整个词到倒排索引中查询
指定多个term的搜索词:
title匹配xiaomi或者huawei的document
多条件的话,在query下加bool,然后在bool下可以加以下四种条件:
must,must_not,should,filter
每个子查询都会计算一个document针对它的相关度分数,然后bool综合所有分数,合并为一个分数,当然filter是不会计算分数的
当我们不关心检索词频率TF(Term Frequency)对搜索结果排序的影响时,可以使用constant_score将查询语句query或者过滤语句filter包装起来。
如果用上面命令的格式构建查询,查询对象会将所有的条件绑定到一起存储到缓存中;因此如果我们查询人名相同但是出生年份不同的运动员,ElasticSearch无法重用上面查询命令中的任何信息。因此,我们来试着优化一下查询。由于一千个人可能会有一千个人名,所以人名不太适合缓存起来;但是年份比较适合:
我们使用了一个filtered类型的查询对象,查询对象将query元素和filter元素都包含进去了。第一次运行该查询命令后,ElasticSearch就会把filter缓存起来,如果再有查询用到了一样的filter,就会直接用到缓存。就这样,ElasticSearch不必多次加载同样的信息。
一般用在那种特别复杂庞大的搜索下,比如你一下子写了上百行的搜索,这个时候可以先用validate api去验证一下,搜索是否合法
如果对一个string field进行排序,结果往往不准确,因为分词后是多个单词,再排序就不是我们想要的结果了
通常解决方案是,将一个string field建立两次索引,一个分词,用来进行搜索;一个不分词,用来进行排序
创建示例索引
插入数据
开始查询,使用title.raw进行分词,title进行查询
参考的文章:
Elasticsearch查询性能优化 - https://www.jianshu.com/p/6b5ddb594b1b
相关拓展:
为什么Elasticsearch查询变得这么慢了? 大数据 铭毅天下(公众号同名)-CSDN博客 https://blog.csdn.net/laoyang360/article/details/83048087
多表查询之子查
1:子查询是将一个查询语句嵌套在另一个查询语句中。 2:内层查询语句的查询结果,可以为外层查询语句提供查询条件。 3:子查询中可以包含 IN,NOT IN,ANY,ALL,EXISTS 和 NOT EXISTS 等关键字 4:还可以包含比较运算符: =、!=、>、<等
还是以之前emp 与dep表格为例:
dep表格:

emp:表格
1 带in关键字子查询
先提供一个不带IN 的 关键字查询,用之前学的内连接查询如下:

用带in的关键字进行子查询
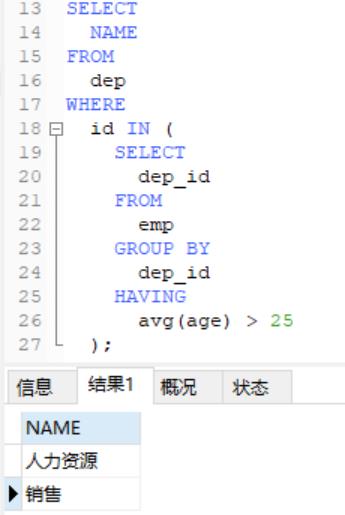
查看不足2人的部门名:

以上是关于14、match all 等查询类型,多条件组合查询和利用filter进行查询的优化的主要内容,如果未能解决你的问题,请参考以下文章