向过程传递参数有啥传递和啥传递两种方法,其中啥是VB默认的参数传递方式?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了向过程传递参数有啥传递和啥传递两种方法,其中啥是VB默认的参数传递方式?相关的知识,希望对你有一定的参考价值。
在VB中向过程传递参数的方法有两种:按值传递和按地址传递。VB在调用过程时,通过使用参数传递的方式实现调用过程与被调用过程之间的数据通信。参数传递实际上就是借助形参(在Sub或Function定义语句中)和实参(在调用程序中)的“结合”来实现。
按值传递:1)当实参为常量或表达式时;2)实参是变量时,在形参之前设置关键字ByVal。
按地址传递:当实参为变量或数组时,形参之前设置关键字ByRef(或省略)表示要按地址传递。
VB默认的参数传递方式是按地址传递。 参考技术A 2种,传值和传址,下面简单介绍一下。
byref:缺省方式,按地址传,例如函数A调用函数B,按地址传递变量c作为参数,传递后如B在执行过程中改变c的值,则A中c的值也将改变为B执行后c的值。
byval:按值传。例如函数A调用函数B,按值传递变量c作为参数,传递后不管B在执行过程中是否改变c的值,A中c的值保持调用B之前的值不变 参考技术B 按值传递和按地址传递
默认前者:按值传递
Python的函数参数传递
首先还是应该科普下函数参数传递机制,传值和传引用是什么意思?
函数参数传递机制问题在本质上是调用函数(过程)和被调用函数(过程)在调用发生时进行通信的方法问题。基本的参数传递机制有两种:值传递和引用传递。
值传递(passl-by-value)过程中,被调函数的形式参数作为被调函数的局部变量处理,即在堆栈中开辟了内存空间以存放由主调函数放进来的实参的值,从而成为了实参的一个副本。值传递的特点是被调函数对形式参数的任何操作都是作为局部变量进行,不会影响主调函数的实参变量的值。
引用传递(pass-by-reference)过程中,被调函数的形式参数虽然也作为局部变量在堆栈中开辟了内存空间,但是这时存放的是由主调函数放进来的实参变量的地址。被调函数对形参的任何操作都被处理成间接寻址,即通过堆栈中存放的地址访问主调函数中的实参变量。正因为如此,被调函数对形参做的任何操作都影响了主调函数中的实参变量。
在python中实际又是怎么样的呢?
先看一个简单的例子
from ctypes import *
import os.path
import sys
def test(c):
print "test before "
print id(c)
c+=2
print "test after +"
print id(c)
return c
def printIt(t):
for i in range(len(t)):
print t[i]
if __name__=="__main__":
a=2
print "main before invoke test"
print id(a)
n=test(a)
print "main afterf invoke test"
print a
print id(a)
运行后结果如下:
>>>
main before invoke test
test before
test after +
main afterf invoke test
39601564
id函数可以获得对象的内存地址.很明显从上面例子可以看出,将a变量作为参数传递给了test函数,传递了a的一个引用,把a的地址传递过去了,所以在函数内获取的变量C的地址跟变量a的地址是一样的,但是在函数内,对C进行赋值运算,C的值从2变成了4,实际上2和4所占的内存空间都还是存在的,赋值运算后,C指向4所在的内存。而a仍然指向2所在的内存,所以后面打印a,其值还是2.
如果还不能理解,先看下面例子
>>> a=1
>>> b=1
>>> id(a)
>>> id(b)
>>> a=2
>>> id(a)
a和b都是int类型的值,值都是1,而且内存地址都是一样的,这已经表明了在python中,可以有多个引用指向同一个内存(画了一个很挫的图,见谅),在给a赋值为2后,再次查看a的内存地址,都已经变化了
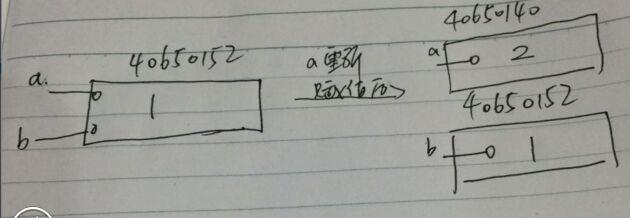
而基于最前面的例子,大概可以这样描述:

那python函数传参就是传引用?然后传参的值在被调函数内被修改也不影响主调函数的实参变量的值?再来看个例子。
from ctypes import *
import os.path
import sys
def test(list2):
print "test before "
print id(list2)
list2[1]=30
print "test after +"
print id(list2)
return list2
def printIt(t):
for i in range(len(t)):
print t[i]
if __name__=="__main__":
list1=["loleina",25,\'female\']
print "main before invoke test"
print id(list1)
list3=test(list1)
print "main afterf invoke test"
print list1
print id(list1)
实际值为:
>>>
main before invoke test
test before
test after +
main afterf invoke test
[\'loleina\', 30, \'female\']
发现一样的传值,而第二个变量居然变化,为啥呢?
实际上是因为python中的序列:列表是一个可变的对象,就基于list1=[1,2] list1[0]=[0]这样前后的查看list1的内存地址,是一样的。
>>> list1=[1,2]
>>> id(list1)
>>> list1[0]=[0]
>>> list1
[[0], 2]
>>> id(list1)
字典也是可变对象:
>>> def fun2(num1,l1,d1):
... num1=123
... l1[0]=123
... d1[\'a\']=123
... print("inside:","num1=%f,l1=%s,d1=%s"%(num1,l1,d1))
...
>>> num=111
>>> l=[1,1,1]
>>> d={\'a\':111,\'b\':0}
>>> print("before:","num=%f,l=%s,d=%s"%(num,l,d))
before: num=111.000000,l=[1, 1, 1],d={\'a\': 111, \'b\': 0}
>>> fun2(num,l,d)
inside: num1=123.000000,l1=[123, 1, 1],d1={\'a\': 123, \'b\': 0}
>>> print("after:","num=%f,l=%s,d=%s"%(num,l,d))
after: num=111.000000,l=[123, 1, 1],d={\'a\': 123, \'b\': 0}
结论:python不允许程序员选择采用传值还是传引用。Python参数传递采用的肯定是“传对象引用”的方式。这种方式相当于传值和传引用的一种综合。如果函数收到的是一个可变对象(比如字典或者列表)的引用,就能修改对象的原始值--相当于通过“传引用”来传递对象。如果函数收到的是一个不可变对象(比如数字、字符或者元组)的引用,就不能直接修改原始对象--相当于通过“传值\'来传递对象。
以上是关于向过程传递参数有啥传递和啥传递两种方法,其中啥是VB默认的参数传递方式?的主要内容,如果未能解决你的问题,请参考以下文章
Activity通过构造方法和普通方法向Fragment传递参数