PyTorch中的Conv2d使用
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PyTorch中的Conv2d使用相关的知识,希望对你有一定的参考价值。
参考技术A 在这里记录一下PyTorch中常用的 Conv2d 的使用,卷积神经网络可以说是做视觉算法的必使用的组件, Conv2d的官方文档
Conv2d函数的参数为:
各个参数含义如下:
. in_channels(int)-Number of channels in the input image
. out_channels(int)-Number of channels produced by the convolution
. kernel_size(int or tuple)-Size of the convolving kernel
. stride(int or tuple,optional)-Stride of the convolution Default:1
. padding(int or tuple,optional)-Zero-padding added to both sides of the input.Default:0
. padding_mode(string,optional)-zeros
. dilation(int or tuple,optional)-Spacing between kernel elements.Default:1
. groups(int,optional)-Number of blocked connections from input channels to output channels.Default:1
. bias(bool,optional)-if True.adds a learnable bias to the output.Default:True
这里着重介绍如下的几个概念:
stride: 顾明思义就是 步长 的意思,每次移动的步幅。
zero-padding: 图像四周填0
dilation: 控制kernel点之间的空间距离,可以理解为卷积间隔的大小这个在空洞卷积中非常有用。
groups: 分组卷积 - Convolution 层的参数中有一个group参数,其意思就是将对应的输入通道和输出通道进行分组,默认值为1,也就是说默认输出输入的所有通道各位一组。如输入数据大小为90x100x100x32,通道数32,要经过一个3x3x48的卷积,group默认是1,就是全连接的卷积层。
如果group是2,那么对应要将输入的32个通道分成2个16的通道,将输出的48个通道分成2个24的通道。对输出的2个24的通道,第一个24通道与输入的第一个16通道进行全卷积,第二个24通道与输入的第二个16通道进行全卷积。
极端情况下,输入输出通道数相同,比如24,group大小也为24,那么每个输出卷积核,只与输入的对应的通道进行卷积。
输入输出格式:
. N是batch的大小
. C是通道数量
. H是输入的高度
. W是输入的宽度
其中N和C-in、C-out是人为指定,H,W是原始输入,H-out,W-out是通过公式计算出来的,公式如下:
使用PyTorch中的KFAC优化更深层的网络
Optimizing deeper networks
with KFAC in PyTorch.
使用PyTorch中的KFAC优化更深层的网络
Optimization becomes less effective in first order methods like Adam as batch-size and depth increases. Second order methods like KFAC (an approximate natural gradient method) are a bit more expensive, but are much less affected by depth. For a difficult problem this translates to savings in wall-clock time.
像Adam这样的一阶方法,随着batch的大小和深度的增加,变得不那么有效了。像KFAC(一种近似自然梯度的方法)这样的二阶方法稍微贵一点,但受深度的影响要小得多。对于一个困难的问题,这意味着时钟时间的节约。
I’ve recently experimented with KFAC in PyTorch. Its imperative style of programming made it easier to prototype optimization algorithms than graph-based approach of TensorFlow. For a fully connected network, an existing optimizer can be augmented with KFAC preconditioning in just a few lines of PyTorch, see “Implementation” below.
Consider the following autoencoder on MNIST
我最近在PyTorch上用KFAC做实验。它的命令式编程风格使得原型优化算法比用基于图形的TensorFlow更容易实现。对于一个全连接网络,现有的优化器可以通过几行PyTorch用KFAC实现预处理,参见下面的“实现”。
考虑一下MNIST上的自编码器。
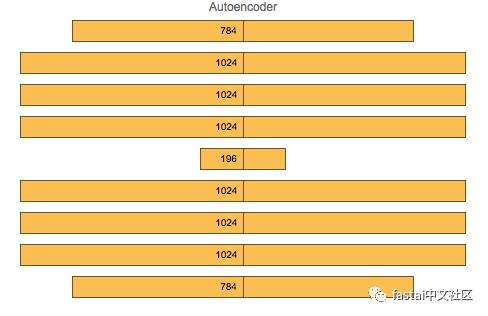
Table 1: Made up data we are using for this example
Optimizing this architecture using batch of size 10k, the advantage of KFAC is stark, 100x less iterations and 25x less wall-clock time than Adam to reach the test loss minimum.
使用10k大小的批次优化此架构,KFAC的优点是明显的,比Adam100倍更少的迭代次数和25倍更少的时钟时间,达到了测试损失的最小值。
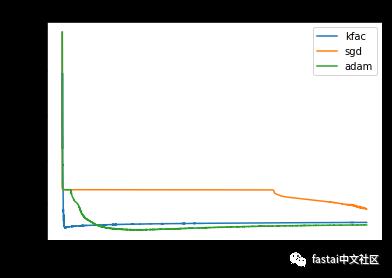
Graph 1: Test loss of three different methods
Derivation
Traditional derivation of KFAC (Martens, Grosse, Ba) is motivated by information geometry. Below I give an alternative derivation — KFAC-style update is simply the Newton-step for a deep linear neural network.
推导
传统的KFAC推导(Martens,Grosse,Ba)是出于信息几何学。下面我给的另一种推导 —KFAC风格更新紧紧是深度线性神经网络的牛顿迭代步。
To more derivation concrete, consider optimizing a deep fully-connected linear autoencoder. Without loss of generality, we can write our predictions Y as a function of parameter matrix W as follows:
对于更具体的推导,考虑优化一个深度全连接线性自编码器。 不失一般性,我们可以将我们的预测结果Y写为参数矩阵W的函数,如下所示:

Given labels \hat{Y} we can write our prediction error e and loss J:
鉴于标签\{Y的预测值}我们可以得出预测误差e和损耗J:

To minimize J, we differentiate with respect to W and get the following for our gradient and SGD update rule:
为了最小化J,我们对W求导,并得到下式推导出梯度和随机梯度下降更新规则:

Note that quantity “Be” in equation above is equal to the backprop matrix you get in a reverse-mode AD algorithm. It is the “grad_output” quantity passed into PyTorch backward() method.
To get the Hessian, we differentiate our gradient G again to get the result in terms of Kronecker product:
注意,上面公式中的数量“Be”等于你在逆向模式AD算法中得到的反向传播矩阵。这是传递给PyTorch backward()方法的“grad_output”数量。
要获得Hessian,我们再次对梯度G求导,以获得Kronecker乘积的结果:

Dividing by the Hessian and rearranging, our Newton-update step becomes this
通过除以Hessian并重排,我们的牛顿更新迭代步变成了如下所示:

Matrices on each side of G are known as whitening matrices. The first matrix is the backprop whitening matrix, while the second matrix is the activation whitening matrix.
G每一边上的矩阵称为白化矩阵。 第一个矩阵是反向传播白化矩阵,而第二个矩阵是激活白化矩阵。
Note that matrix B is not directly available during backprop, and using “grad_output” in its place will get use Bee’B’ instead of BB’. That’s not a problem since we can generate any “e” by selecting target labels accordingly. Some choices for e:
Padded identity matrix so that ee’ is identity. Then Bee’B’=BB’ exactly
IID gaussian values. Then, Bee’B’=BB’ in expectation
Detailed derivation is here
注意,矩阵B不能在反向传播期直接使用,在其位置上使用grad_output 将会用Bee'B’替代BB。这不是问题,因为我们可以通过选择相应的目标标签来生成任何“e”。e的一些选择:
填充单位矩阵,使ee’是单一的。
然后正好Bee'B' = BB
独立同分布的高斯值。然后,Bee'B ' = BB的期望
详细的推导在这里
Implementation
Basic implementation has three parts:
capture: compute gradients and save forward/backprop values
invert: compute whitening matrices
kfac: apply whitening matrices during gradient computation
Steps “capture” and “kfac” can be accomplished with a version of Addmm that has a custom “backwards” method:
实施
基本实现分为三部分:
捕获:计算梯度和保存前向/反向传播值
转置:计算白化矩阵
kfac:在梯度计算中应用白化矩阵
步骤“捕捉”和“kfac”可以用一个具有自定义“向后”方法的Addmm版本完成:
Table 2: kfac.py hosted with by GitHub
The body of training loop then looks like this
训练循环的主体,然后是这样的
Table 3: view raw kfac.py hosted with by GitHub
Full implementation can be seen in appendix
完整的实现见附录
Note
The difference between Adam and KFAC shrunk to about 5x improvement in wall-clock time when I tweaked the experiment to make it more amenable to SGD
Replace sigmoid activations with ReLU
Add weight normalization
Use batch size 128 for Adam
注意
我调整实验使kfac更易控制SGD时,Adam和kfac之间的差异缩小到了5倍时钟时间的改进。
用ReLU代替Sigmoid激活
添加权重正则化
为Adam使用128大小的batch
appendix
KFAC
https://arxiv.org/abs/1503.05671
Description of experiment is here
https://github.com/yaroslavvb/kfac_pytorch/blob/master/deep_autoencoder.ipynb
Table 2
https://gist.github.com/yaroslavvb2/2d92df19af84298c87416fc6b510d88a/raw/a701c6af981deffd5e973241c305efdd0772f0ca/kfac.py
Table 3
https://gist.github.com/yaroslavvb2/383dd9620476733de6eef5762282e4d4/raw/7f76fcff3c17311c89339e7bc435fedd0aed8378/optimizer_step.py
Full implementation is here
https://github.com/yaroslavvb/kfac_pytorch/blob/master/kfac_pytorch.py
以上是关于PyTorch中的Conv2d使用的主要内容,如果未能解决你的问题,请参考以下文章
Pytorch一文搞懂nn.Conv2d的groups参数的作用
Pytorch一文搞懂nn.Conv2d的groups参数的作用