理解 RabbitMQ 工作流程
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了理解 RabbitMQ 工作流程相关的知识,希望对你有一定的参考价值。
参考技术A RabbitMQ 是基于 AMQP(Advanced Message Queue Protocol 高级消息队列协议)协议实现的消息队列中间件,协议的基本模型结构如下图:从图中可以看出 AMQP 协议主要包含如下几个部分:
结合上边的内容,我们可以大致的描述出 RabbitMQ 的工作流程:生产者(Producer)与消费者(Consumer)和 RabbitMQ 服务(Broker)建立连接, 然后生产者发布消息(Message)同时需要携带交换机(Exchange) 名称以及路由规则(Routing Key),这样消息会到达指定的交换机,然后交换机根据路由规则匹配对应的 Binding,最终将消息发送到匹配的消息队列(Quene),最后 RabbitMQ 服务将队列中的消息投递给订阅了该队列的消费者(消费者也可以主动拉取消息)。
前边我们已经了解到,一个 Exchange 可以绑定多个 Queue, Exchange 接收生产者发送的消息,然后将消息按照路由规则投放到指定的 Queue 中。接下来我们需要了解这个路由规则具体是什么样的,它是如何决定 Exchange 将消息发送到那个 Queue。
Binding 代表一个 Exchange 和一个 Queue 的绑定关系,这个绑定关系上可以附件一个参数 Routing Key,Exchange 会根据发送消息时携带的 Routing Key 去和该 Exchange 所有相关的 Binding 匹配,如果匹配到了,就将消息发送给 Binding 中绑定的 Queue。
上边是一个相对通用的流程,可以帮助我们理解交换机的工作原理,当然也存在一些特殊的情况后边会提到。
在 RabbitMQ 中,Exchange 主要分为: Fanout Excahnge 、 Direct Exchange 、 Topic Exchange 、 Default Exchange 、 Headers Exchange ,同时 Routing Key 结合不同类型的 Exchange 使用时,用法也有所不同。
使用 Fanout Exchange 时,会忽略 Routing Key,所以我们也就没必要在绑定 Exchange 和 Queue,以及发送消息时去设置 Routing Key 了,Exchange 直接将消息发送到和它绑定的所有 Queue 中,省略了 Routing Key 匹配的环节。
在 RabbitMQ 中默认使用的是 Direct Exchange,Exchange 和 Queue 绑定时需要指定 Routing Key,发送消息时也需要携带 Routing Key,这样 Exchange 收到消息后就可以根据 Routing Key 匹配到对应的 Binding,进而将消息发送到目标队列里。注意这里的 Routing Key 是需要精确匹配的。
Topic Exchange 和 Direct Exchange 的用法很类似,区别在于 Topic Exchange 中的 Routing Key 是支持模糊匹配的。提供了两个通配符:
这样绑定 Exchange 绑定 Queue1、Queue2、Queue3 时指定 Routing Key 分别为 *.red.# 、 #.blue.# 、 green.* ,这样发送消息是如果携带的 Routing Key 为 green.red ,最终可以匹配到 Queue1、Queue3。
Default Exchange 是一种特殊的 Direct Exchange,使用它时,我们只需要创建一个 Queue 即可,RabbitMQ 服务会自动将 Queue 和一个名称为空的默认的 Exchange 绑定,同时将 Routing Key 指定为 Queue 的名称。这种 Exchange 简化了使用步骤,但也不够灵活,不好做实际的业务划分,可以用来完成一些简单的需求。
Headers Exchange 不使用 Routing Key 来匹配目标 Queue,而是绑定 Exchange 和 Queue 时需要指定额外的 Arguments 参数,发送消息时携带上对应的参数来实现匹配。这种 Exchange 用的比较少,了解即可。
一般情况下使用 Fanout Excahnge 、 Direct Exchange 就能满足业务需求了。
python采用pika库使用rabbitmq --工作队列
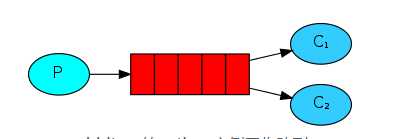
消息也可以理解为任务,消息发送者可以理解为任务分配者,消息接收者可以理解为工作者,当工作者接收到一个任务,还没完成的时候,任务分配者又发一个任务过来,那就忙不过来了,于是就需要多个工作者来共同处理这些任务,这些工作者,就称为工作队列。
RabbitMQ会默认把p发的消息依次分发给各个消费者(c),跟负载均衡差不多
先启动消息生产者,然后再分别启动3个消费者,通过生产者多发送几条消息,你会发现,这几条消息会被依次分配到各个消费者身上


1 import pika 2 import sys 3 4 credentials = pika.PlainCredentials(‘admin‘, ‘passwd‘) 5 connection = pika.BlockingConnection(pika.ConnectionParameters( 6 ‘ip‘,credentials=credentials)) 7 channel = connection.channel() 8 9 channel.exchange_declare(exchange=‘logs‘,exchange_type=‘fanout‘) 10 11 message = ‘ ‘.join(sys.argv[1:]) or "info: Hello World!" 12 13 channel.basic_publish(exchange=‘logs‘, 14 routing_key=‘‘, 15 body=message) 16 print(" [x] Sent %r" % message) 17 connection.close()
1 import pika 2 3 credentials = pika.PlainCredentials(‘admin‘, ‘passwd‘) 4 connection = pika.BlockingConnection(pika.ConnectionParameters( 5 ‘ip‘,credentials=credentials)) 6 channel = connection.channel() 7 8 9 channel.exchange_declare(exchange=‘logs‘, exchange_type=‘fanout‘) 10 11 result = channel.queue_declare(exclusive=True) # 不指定queue名字,rabbit会随机分配一个名字,exclusive=True会在使用此queue的消费者断开后,自动将queue删除 12 queue_name = result.method.queue 13 14 15 channel.queue_bind(exchange=‘logs‘, queue=queue_name) 16 17 print(‘ [*] Waiting for logs. To exit press CTRL+C‘) 18 19 20 def callback(ch, method, properties, body): 21 print(" [x] %r" % body) 22 23 24 channel.basic_consume(callback, queue=queue_name,no_ack=True) 25 26 channel.start_consuming()
以上是关于理解 RabbitMQ 工作流程的主要内容,如果未能解决你的问题,请参考以下文章