Scrapy爬虫框架第一讲(Linux环境)
Posted 518894-lu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Scrapy爬虫框架第一讲(Linux环境)相关的知识,希望对你有一定的参考价值。
1、What is Scrapy?

答:Scrapy是一个使用python语言(基于Twistec框架)编写的开源网络爬虫框架,其结构清晰、模块之间的耦合程度低,具有较强的扩张性,能满足各种需求。(前面我们介绍了使用requests、beautifulsoup、selenium等相当于你写作文题,主要针对的是个人爬虫;而Scrapy框架的出现给了我们一个方便灵活爬虫程序架构,我们只需针对其中的组件做更改,即可实现一个完美的网络爬虫,相当于你做填空题!)
基于Scrapy的使用方便性,下面所有的Scrapy程序我们都会在Linux系统下运行
2、Scrapy框架的安装(这里我使用的是vmware虚拟机+ubuntu16.04镜像环境)
打开终端:sudo apt-get install python-dev python-pip libxml2-dev libxslt1-dev zlib1g-dev libffi-dev libssl-dev(安装一些依赖包)
如果你没安装python3请执行:sudo apt-get install python3 python3-dev
这里小伙伴们可以先创建一个虚拟环境:pip3 install virtualenv 再进行scrapy 的安装(之后你写的所有程序都会在虚拟环境中运行)
基于我使用的是ubuntu16.04版本,系统自带了python2.7.14 和python3.5.2两个版本
下面小伙们让我们先来解决一个多版本的共存问题吧
当你输入python时系统会自动指向python2,而我们的所有程序是基于python3 的,这也是以后的主流。(我们要的是输入python,系统直接链接到python3)

下面我们来解决这个问题:sudo su (输入你设置等待用户密码进入超级用户权限)---接着请看图:
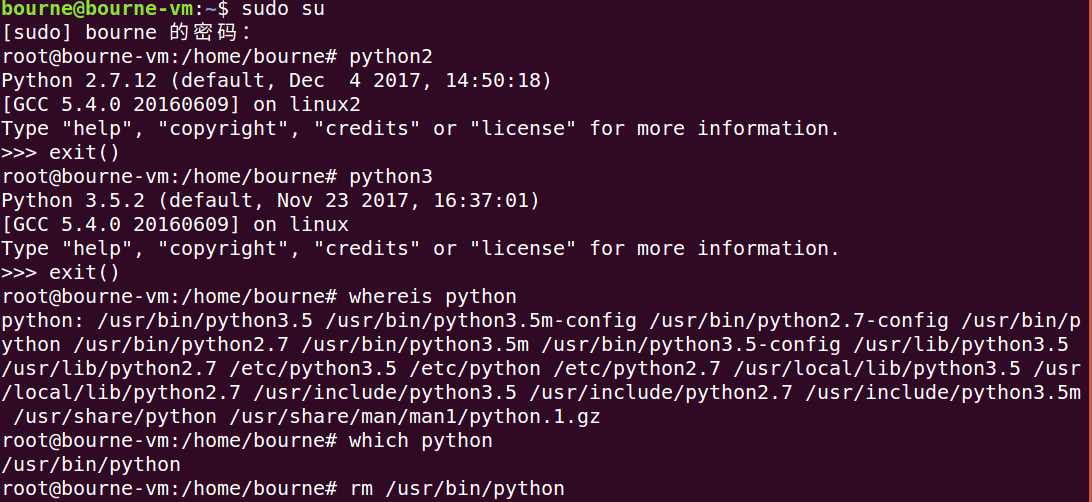
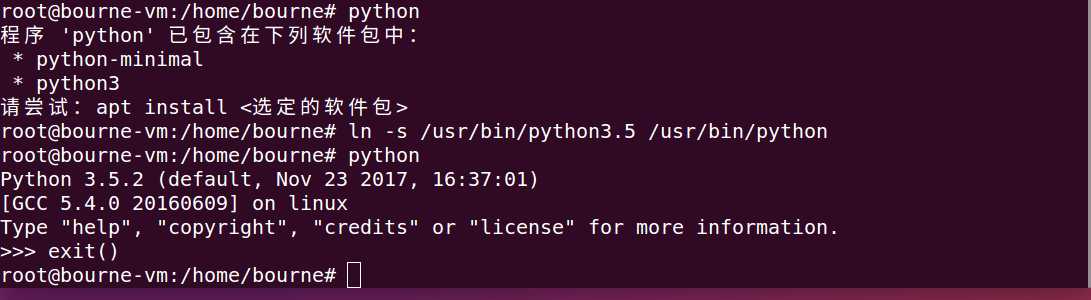
分析:(linux命令小伙伴们我们以后再谈)
当我们键入python2 系统自动指向python2环境,python3同样如此
whereis python 找出了python的所有可执行文件的路径
which python 找出了当我们键入python时执行的文件路径
我们使用rm 首先删除了该路径,接着使用 ln -s 参数1 参数2 (将参数1 指向 参数2 这里相当于生成了软链接原理和超链接一样,当你键入python时系统自动指向了软连接 python3的可执行文件的路径并执行文件),这样我们成功的达到了预想目的
3、如何解决同时使用多个python版本和同时使用多个库版本的问题
答:安装virtualenv虚拟环境
打开终端:sudo pip3 install virtualenv
如果出现以下错误请使用 vi /usr/bin/pip3 更改配置文件(这是因为原来我们是python2的pip当你升级后系统没改配置文件,小伙伴们不要紧张,我们自己修改即可)

这里涉及到linux下强大的文本编辑器vim的使用我们下次专门讲解
更改配置文件如下:
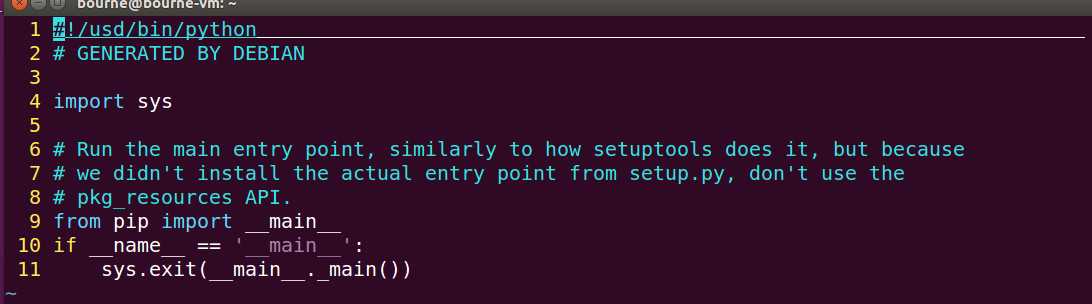
再次键入:sudo pip3 install virtualenv (成功)
接着:

创建名叫course-python3.5-env 的python3.5虚拟环境:如上图
激活与推出虚拟环境 source 与 deactivate 命令

最后我们按照前述,首先激活虚拟环境,然后安装Scrapy即可
验证:终端键入:scrapy --version查看安装的scapy版本,不报错即可!
以后我们所有的scrapy爬虫项目都在虚拟环境下运行了!
以上是关于Scrapy爬虫框架第一讲(Linux环境)的主要内容,如果未能解决你的问题,请参考以下文章