python--pandas切片
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python--pandas切片相关的知识,希望对你有一定的参考价值。
参考技术A可以用中括号 [] 完成对数据框的切片。利用 列名 对列进行切片,利用 列的布尔序列 对行进行切片。
用 iloc 方法,使用行列的 位置 对数据框进行切片。支持布尔切片。
只传入一个参数时,表示对行进行切片。参数为整数返回序列,参数为列表返回数据框。正数表示正向切片,
负数表示反向切片。
使用 iloc 方法进行列切片时,需要行参数设置为 : ,表示选取所有的行。列切片方法与行切片相同。
同时设置行参数与列参数,使用 iloc 进行组合切片。
使用 loc 方法,用行列的 名字 对数据框进行切片,同时支持布尔索引。
传入一个参数时,只对行进行切片。
使用 loc 方法进行列切片时,行参数需要设置为 : ,表示选取所有行。列切片方法与行切片相同。
同时设置行参数和列参数,使用 loc 方法进行组合切片。
filter 方法与 loc 方法类似,都是基于索引名和列名进行切片。
python pandas groupby分组后的数据怎么用
pandas提供了一个灵活高效的groupby功能,它使你能以一种自然的方式对数据集进行切片、切块、摘要等操作。根据一个或多个键(可以是函数、数组或DataFrame列名)拆分pandas对象。计算分组摘要统计,如计数、平均值、标准差,或用户自定义函数。对DataFrame的列应用各种各样的函数。应用组内转换或其他运算,如规格化、线性回归、排名或选取子集等。计算透视表或交叉表。执行分位数分析以及其他分组分析。1、首先来看看下面这个非常简单的表格型数据集(以DataFrame的形式):
123456789101112
>>> import pandas as pd>>> df = pd.DataFrame('key1':['a', 'a', 'b', 'b', 'a'],... 'key2':['one', 'two', 'one', 'two', 'one'],... 'data1':np.random.randn(5),... 'data2':np.random.randn(5))>>> df data1 data2 key1 key20 -0.410673 0.519378 a one1 -2.120793 0.199074 a two2 0.642216 -0.143671 b one3 0.975133 -0.592994 b two4 -1.017495 -0.530459 a one
假设你想要按key1进行分组,并计算data1列的平均值,我们可以访问data1,并根据key1调用groupby:
123
>>> grouped = df['data1'].groupby(df['key1'])>>> grouped<pandas.core.groupby.SeriesGroupBy object at 0x04120D70>
变量grouped是一个GroupBy对象,它实际上还没有进行任何计算,只是含有一些有关分组键df['key1']的中间数据而已,然后我们可以调用GroupBy的mean方法来计算分组平均值:
12345
>>> grouped.mean()key1a -1.182987b 0.808674dtype: float64
说明:数据(Series)根据分组键进行了聚合,产生了一个新的Series,其索引为key1列中的唯一值。之所以结果中索引的名称为key1,是因为原始DataFrame的列df['key1']就叫这个名字。
2、如果我们一次传入多个数组,就会得到不同的结果:
12345678
>>> means = df['data1'].groupby([df['key1'], df['key2']]).mean()>>> meanskey1 key2a one -0.714084 two -2.120793b one 0.642216 two 0.975133dtype: float64
通过两个键对数据进行了分组,得到的Series具有一个层次化索引(由唯一的键对组成):
12345
>>> means.unstack()key2 one twokey1 a -0.714084 -2.120793b 0.642216 0.975133
在上面这些示例中,分组键均为Series。实际上,分组键可以是任何长度适当的数组:
12345678
>>> states = np.array(['Ohio', 'California', 'California', 'Ohio', 'Ohio'])>>> years = np.array([2005, 2005, 2006, 2005, 2006])>>> df['data1'].groupby([states, years]).mean()California 2005 -2.120793 2006 0.642216Ohio 2005 0.282230 2006 -1.017495dtype: float64
3、此外,你还可以将列名(可以是字符串、数字或其他Python对象)用作分组将:
123456789101112
>>> df.groupby('key1').mean() data1 data2key1 a -1.182987 0.062665b 0.808674 -0.368333>>> df.groupby(['key1', 'key2']).mean() data1 data2key1 key2 a one -0.714084 -0.005540 two -2.120793 0.199074b one 0.642216 -0.143671 two 0.975133 -0.592994
说明:在执行df.groupby('key1').mean()时,结果中没有key2列。这是因为df['key2']不是数值数据,所以被从结果中排除了。默认情况下,所有数值列都会被聚合,虽然有时可能会被过滤为一个子集。
无论你准备拿groupby做什么,都有可能会用到GroupBy的size方法,它可以返回一个含有分组大小的Series:
1234567
>>> df.groupby(['key1', 'key2']).size()key1 key2a one 2 two 1b one 1 two 1dtype: int64
注意:分组键中的任何缺失值都会被排除在结果之外。
4、对分组进行迭代
GroupBy对象支持迭代,可以产生一组二元元组(由分组名和数据块组成)。看看下面这个简单的数据集:
12345678910111213
>>> for name, group in df.groupby('key1'):... print(name)... print(group)...a data1 data2 key1 key20 -0.410673 0.519378 a one1 -2.120793 0.199074 a two4 -1.017495 -0.530459 a oneb data1 data2 key1 key22 0.642216 -0.143671 b one3 0.975133 -0.592994 b two
对于多重键的情况,元组的第一个元素将会是由键值组成的元组:
1234567891011121314151617
>>> for (k1, k2), group in df.groupby(['key1', 'key2']):... print k1, k2... print group...a one data1 data2 key1 key20 -0.410673 0.519378 a one4 -1.017495 -0.530459 a onea two data1 data2 key1 key21 -2.120793 0.199074 a twob one data1 data2 key1 key22 0.642216 -0.143671 b oneb two data1 data2 key1 key23 0.975133 -0.592994 b two
当然,你可以对这些数据片段做任何操作。有一个你可能会觉得有用的运算:将这些数据片段做成一个字典:
1234567891011121314
>>> pieces = dict(list(df.groupby('key1')))>>> pieces['b'] data1 data2 key1 key22 0.642216 -0.143671 b one3 0.975133 -0.592994 b two>>> df.groupby('key1')<pandas.core.groupby.DataFrameGroupBy object at 0x0413AE30>>>> list(df.groupby('key1'))[('a', data1 data2 key1 key20 -0.410673 0.519378 a one1 -2.120793 0.199074 a two4 -1.017495 -0.530459 a one), ('b', data1 data2 key1 key22 0.642216 -0.143671 b one3 0.975133 -0.592994 b two)]
groupby默认是在axis=0上进行分组的,通过设置也可以在其他任何轴上进行分组。那上面例子中的df来说,我们可以根据dtype对列进行分组:
12345678910111213141516171819
>>> df.dtypesdata1 float64data2 float64key1 objectkey2 objectdtype: object>>> grouped = df.groupby(df.dtypes, axis=1)>>> dict(list(grouped))dtype('O'): key1 key20 a one1 a two2 b one3 b two4 a one, dtype('float64'): data1 data20 -0.410673 0.5193781 -2.120793 0.1990742 0.642216 -0.1436713 0.975133 -0.5929944 -1.017495 -0.530459
1234567891011121314
>>> grouped<pandas.core.groupby.DataFrameGroupBy object at 0x041288F0>>>> list(grouped)[(dtype('float64'), data1 data20 -0.410673 0.5193781 -2.120793 0.1990742 0.642216 -0.1436713 0.975133 -0.5929944 -1.017495 -0.530459), (dtype('O'), key1 key20 a one1 a two2 b one3 b two4 a one)]
5、选取一个或一组列
对于由DataFrame产生的GroupBy对象,如果用一个(单个字符串)或一组(字符串数组)列名对其进行索引,就能实现选取部分列进行聚合的目的,即:
123456
>>> df.groupby('key1')['data1']<pandas.core.groupby.SeriesGroupBy object at 0x06615FD0>>>> df.groupby('key1')['data2']<pandas.core.groupby.SeriesGroupBy object at 0x06615CB0>>>> df.groupby('key1')[['data2']]<pandas.core.groupby.DataFrameGroupBy object at 0x06615F10>
和以下代码是等效的:
123456
>>> df['data1'].groupby([df['key1']])<pandas.core.groupby.SeriesGroupBy object at 0x06615FD0>>>> df[['data2']].groupby([df['key1']])<pandas.core.groupby.DataFrameGroupBy object at 0x06615F10>>>> df['data2'].groupby([df['key1']])<pandas.core.groupby.SeriesGroupBy object at 0x06615E30>
尤其对于大数据集,很可能只需要对部分列进行聚合。例如,在前面那个数据集中,如果只需计算data2列的平均值并以DataFrame形式得到结果,代码如下:
1234567891011121314
>>> df.groupby(['key1', 'key2'])[['data2']].mean() data2key1 key2 a one -0.005540 two 0.199074b one -0.143671 two -0.592994>>> df.groupby(['key1', 'key2'])['data2'].mean()key1 key2a one -0.005540 two 0.199074b one -0.143671 two -0.592994Name: data2, dtype: float64
这种索引操作所返回的对象是一个已分组的DataFrame(如果传入的是列表或数组)或已分组的Series(如果传入的是标量形式的单个列明):
12345678910
>>> s_grouped = df.groupby(['key1', 'key2'])['data2']>>> s_grouped<pandas.core.groupby.SeriesGroupBy object at 0x06615B10>>>> s_grouped.mean()key1 key2a one -0.005540 two 0.199074b one -0.143671 two -0.592994Name: data2, dtype: float64
6、通过字典或Series进行分组
除数组以外,分组信息还可以其他形式存在,来看一个DataFrame示例:
123456789101112
>>> people = pd.DataFrame(np.random.randn(5, 5),... columns=['a', 'b', 'c', 'd', 'e'],... index=['Joe', 'Steve', 'Wes', 'Jim', 'Travis']... )>>> people a b c d eJoe 0.306336 -0.139431 0.210028 -1.489001 -0.172998Steve 0.998335 0.494229 0.337624 -1.222726 -0.402655Wes 1.415329 0.450839 -1.052199 0.731721 0.317225Jim 0.550551 3.201369 0.669713 0.725751 0.577687Travis -2.013278 -2.010304 0.117713 -0.545000 -1.228323>>> people.ix[2:3, ['b', 'c']] = np.nan
假设已知列的分组关系,并希望根据分组计算列的总计:
123456
>>> mapping = 'a':'red', 'b':'red', 'c':'blue',... 'd':'blue', 'e':'red', 'f':'orange'>>> mapping'a': 'red', 'c': 'blue', 'b': 'red', 'e': 'red', 'd': 'blue', 'f': 'orange'>>> type(mapping)<type 'dict'>
现在,只需将这个字典传给groupby即可:
12345678910
>>> by_column = people.groupby(mapping, axis=1)>>> by_column<pandas.core.groupby.DataFrameGroupBy object at 0x066150F0>>>> by_column.sum() blue redJoe -1.278973 -0.006092Steve -0.885102 1.089908Wes 0.731721 1.732554Jim 1.395465 4.329606Travis -0.427287 -5.251905
Series也有同样的功能,它可以被看做一个固定大小的映射。对于上面那个例子,如果用Series作为分组键,则pandas会检查Series以确保其索引跟分组轴是对齐的:
12345678910111213141516
>>> map_series = pd.Series(mapping)>>> map_seriesa redb redc blued bluee redf orangedtype: object>>> people.groupby(map_series, axis=1).count() blue redJoe 2 3Steve 2 3Wes 1 2Jim 2 3Travis 2 3
7、通过函数进行分组
相较于字典或Series,Python函数在定义分组映射关系时可以更有创意且更为抽象。任何被当做分组键的函数都会在各个索引值上被调用一次,其返回值就会被用作分组名称。
具体点说,以DataFrame为例,其索引值为人的名字。假设你希望根据人名的长度进行分组,虽然可以求取一个字符串长度数组,但其实仅仅传入len函数即可:
12345
>> people.groupby(len).sum() a b c d e3 2.272216 3.061938 0.879741 -0.031529 0.7219145 0.998335 0.494229 0.337624 -1.222726 -0.4026556 -2.013278 -2.010304 0.117713 -0.545000 -1.228323
将函数跟数组、列表、字典、Series混合使用也不是问题,因为任何东西最终都会被转换为数组:
1234567
>>> key_list = ['one', 'one', 'one', 'two', 'two']>>> people.groupby([len, key_list]).min() a b c d e3 one 0.306336 -0.139431 0.210028 -1.489001 -0.172998 two 0.550551 3.201369 0.669713 0.725751 0.5776875 one 0.998335 0.494229 0.337624 -1.222726 -0.4026556 two -2.013278 -2.010304 0.117713 -0.545000 -1.228323
8、根据索引级别分组
层次化索引数据集最方便的地方在于它能够根据索引级别进行聚合。要实现该目的,通过level关键字传入级别编号或名称即可:
12345678910111213141516171819
>>> columns = pd.MultiIndex.from_arrays([['US', 'US', 'US', 'JP', 'JP'],... [1, 3, 5, 1, 3]], names=['cty', 'tenor'])>>> columnsMultiIndex[US 1, 3, 5, JP 1, 3]>>> hier_df = pd.DataFrame(np.random.randn(4, 5), columns=columns)>>> hier_dfcty US JP tenor 1 3 5 1 30 -0.166600 0.248159 -0.082408 -0.710841 -0.0971311 -1.762270 0.687458 1.235950 -1.407513 1.3040552 1.089944 0.258175 -0.749688 -0.851948 1.6877683 -0.378311 -0.078268 0.247147 -0.018829 0.744540>>> hier_df.groupby(level='cty', axis=1).count()cty JP US0 2 31 2 32 2 33 2 3 参考技术A
1、Python内置的None值在对象数组中也可以作为NA。

2、pandas项目中还在不断优化内部细节以更好处理缺失数据,像用户API功能,例如pandas.isnull,去除了许多恼人的细节。

3、过滤掉缺失数据的办法有很多种。你可以通过pandas.isnull或布尔索引的手工方法,但dropna可能会更实用一些。对于一个Series,dropna返回一个仅含非空数据和索引值的Series。

4、而对于DataFrame对象,事情就有点复杂了。你可能希望丢弃全NA或含有NA的行或列。dropna默认丢弃任何含有缺失值的行。

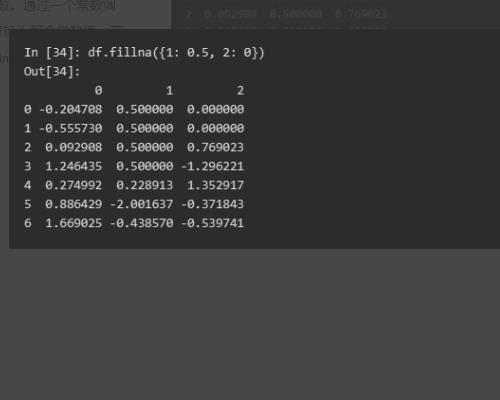
5、可能不想滤除缺失数据(有可能会丢弃跟它有关的其他数据),而是希望通过其他方式填补那些“空洞”。对于大多数情况而言,fillna方法是最主要的函数。通过一个常数调用fillna就会将缺失值替换为那个常数值,若是通过一个字典调用fillna,就可以实现对不同的列填充不同的值。
以上是关于python--pandas切片的主要内容,如果未能解决你的问题,请参考以下文章
如何对不同长度的 Python Pandas groupby 对象进行切片?
在 Python Pandas 中使用 DatetimeIndex 切片 MultIndex 帧时出现 1.1.0 以上的 InvalidIndexError