UCI数据集怎么用?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了UCI数据集怎么用?相关的知识,希望对你有一定的参考价值。
用于数据挖掘测试的数据集去哪里找到?UCI里面的数据具体怎么用啊?各位好心人帮忙解答一下,谢谢!!
参考技术A uci 数据集 的说明 告诉了读者 数据的属性和类别,用户可以用自己的数据挖掘方法去将 uci数据集的分类,将结果与数据说明的结果对比。说明自己算法的正确性本回答被提问者采纳 参考技术B 网址见参考资料;里面有各种分类,你可以取你所需。
参考资料:http://archive.ics.uci.edu/ml/datasets.html
UCI 人口收入数据分析(python)
一、项目介绍
UCI上有许多免费的数据集可以拿来练习,可以在下面的网站找寻
http://archive.ics.uci.edu/ml/datasets.html
这次我使用的是人口收入调查,里面会有每个人的教育程度、每周工时、职业、性别等数据,并以50K为界线,分为收入大于50K和收入小于50K的人群。
首先利用pandas将数据抓下,由于数据是在网页上,直接抓网页就可以,并且用table的格式,以逗号区分列,由于原始数据没有列名称,所以需要为每列设定一个名称,下面为代码
import pandas as pd import sklearn file = pd.read_table(\'http://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.data\', sep=\',\', names=[\'age\', \'workclass\', \'fnlwgt\', \'education\', \'education_num\', \'marital_states\', \'occupation\', \'relationship\', \'race\', \'sex\', \'capital_gain\', \'capital_loss\', \'hours_per_week\', \'native_country\', \'income\'])
file为表名,接着利用file.head()查看前五行的数据

接着用file.info()查看表的信息,发现数据挺完整的,没有缺失数据,只是里面数据大部分都是object,必须要做处理才有办法计算(机器是无法对文字进行计算的,需要转成数字或是矩阵)

接着用hist来看几个int的分布
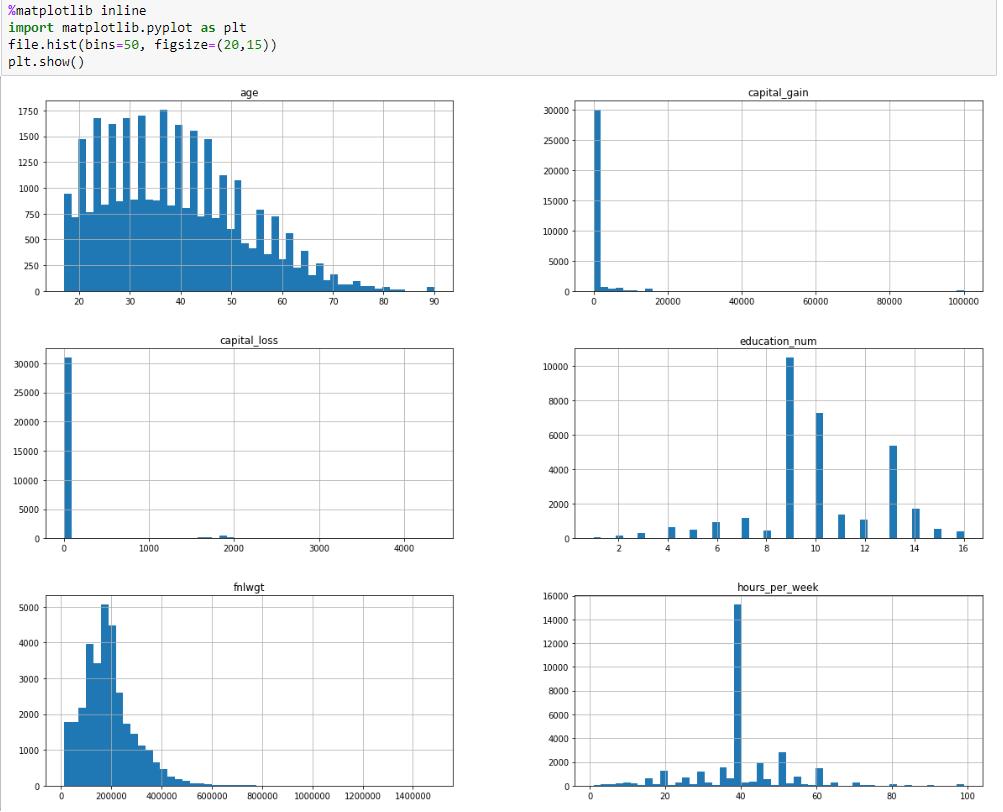
可以看到capital_gain和capital_loss的分布特别奇怪,绝大部分的数据都是0,其他的数据分布都还算是正常。
接着利用value_counts来查看各列的数据统计

像是雇主的话有三分之二的人都是在私企工作,第二多的是自由业,剩下的部分在国企,还有大约1800个是不名的
从这边我们可以推断,这个数据集里虽然没有数据缺失,但是有非常多的0和?这种数据,估计是没问出结果就填了个东西,而这些填充数据会严重影响到时候的分析结果。

剩下的列就不一一展示了,可以看到有些列分布平均,像是职业,最多的也不超过20%,而且前面几名的人数相差不大,这边也可以发现每一列大约都有1800左右的填充数据。
接着我们需要去做相关性的分析,为什么要做相关性分析呢?因为我们想要找出列跟列之间是否有某种关联,还有每个列跟我们要预测的结果(income)是否有关联。
由于关联性是用数字去计算的,但是这个数据集里面大部分的列都是文字,需要先转成可以计算的数字。
这边要注意的是,大部分的文字列数据并没有连续性,所以不能直接转成数字(数字是有连续性的),需要转成矩阵,这边可以用dummies这个功能将文字列转为矩阵列

可以看到原本的workclass这一列,被拆分成了workclass_?, workclass_Federal-gov, workclass_Local-gov等,0代表不是,1代表是,也由于这样的拆分,原本的15列现在变成了110列。
这个时候我们先看看有哪些列跟我们的结果有正相关吧,我们利用corr这个功能来对每一列跟结果列做相关分析

由结果可以看到,相关性最强的是已婚人士,再过来是家庭里的丈夫,再过来是受教育的长度,年纪,工作时长,男性。而职业里公司高管是相关性最强的,再过来是专业人员,这边有点意外的是本科毕业的比硕士、博士毕业的相关性更强,种族是白人,下面是负相关最强的几个

可以看到未婚人士是负相关最强的,正好跟前面的已婚做对比,再过来是小孩,女性等,可以看到这个数据集里影响收入最主要的因素是家庭、性别、教育程度和职业。
到这边我们可以了解收入较高的用户画像是受高等教育已婚的美国中年白人,而收入较低的是没结过婚高中毕业的黑人女性
接着我们想了解收入最高的两个职业都是由什么样的人
先是看高管,可以发现高管大部分都是本科毕业居多,然后工作时间长,有很大一部分是自己开公司,然后也是已婚白人男性。

再来是专业人士,可以发现专业人士跟受教育程度相关性非常大,并且大部分工作单位是政府单位,重点是在专业人士里女性比男性的比例高,而且国籍正相关最强的不是美国而是印度和中国的亚洲女性。
可以分析出专业人士用户画像为已婚的高学历亚洲女性,并为政府工作。

接着我们想看中国籍的美国人大概都是怎么样的人,可以发现非常学历非常极端,不是博士毕业就是没读书,专业人士居多,然后竟然大部分是已婚配偶缺席这种特殊的婚姻状态,其实我也搞不太懂为什么。

以上就是一些简单的用户画像分析,由于数据源是1994年的调查,距今已经20多年了,随着时代变迁,现在的用户画像跟以前应该会有很大的不同,不过也可以借由这些数据来了解当时美国的一些生活情况。
以上是关于UCI数据集怎么用?的主要内容,如果未能解决你的问题,请参考以下文章
机器学习计/算机视觉数据集UCI Machine Learning Repository
R语言图形用户界面数据挖掘包Rattle:加载UCI糖尿病数据集并启动Rattle图形用户界面数据集变量重命名,为数据集结果变量添加标签数据划分(训练集测试集验证集)随机数设置
基于UCI数据集Condition Based Maintenance of Naval Propulsion Plants的随机森林回归