Spark依赖包加载顺序
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark依赖包加载顺序相关的知识,希望对你有一定的参考价值。
参考技术A 在流式计算中对于修改数值的操作或者在 mappartion/foreachPartition 中自定义数据持久化到非主键约束的平台时,就会出现灾难性后果。一旦出现数据倾斜,启动备用线程执行当前任务,就会出现数据加倍等脏数据。所以在以上场景,无法保证操作幂等性的前提下,不要开启推测执行。
spark 依赖包加载顺序总结:
默认情况下,spark 优先使用 / etc/spark/conf/classpath.txt 里自带的依赖包;
若是找不到则查找用户通过 --jar 提交的依赖包 (位于 driver、executor 的 classpath 里);
若是两个路径下都有相同名字的依赖包(版本不同),则抛出 linked exception 用户解决冲突;
使用 --spark.driver,executor.userClassPathFirst = true 优先启用用户提供的依赖包;
使用 --spark.driver,executor.extraClassPath = conflict-jar 来解决同名冲突的包依赖;
Spark ALS应用BLAS加速
文章目录
Spark ALS应用BLAS加速
1. 环境
| 软件 | 说明 | 版本 |
|---|---|---|
| Win10 | 宿主机 | 8G内存,179G SSD |
| VMware Workstation | 虚拟化软件 | V11 |
| Spark | 2.2.2 | |
| Hadoop | 2.6.5 | |
| Maven | windows 上maven用于编译Spark2.2.2 | 3.3.9 |
| Intellij IDEA | Windows上编译测试包 | 2016.3 |
| ubuntu | WMware 虚拟机系统 | Ubuntu 16.04.5 LTS |
| 集群 | 一主三从,node200(主), node201~node203 |
2. 问题引入
- 在使用Spark1.6集群,进行Spark ALS算法测试时,发现其推荐运行的很慢;
- 同时在推荐或建模时,出现如下的提示:
Feb 25, 2019 10:07:05 PM com.github.fommil.netlib.BLAS <clinit>
WARNING: Failed to load implementation from: com.github.fommil.netlib.NativeSystemBLAS
Feb 25, 2019 10:07:05 PM com.github.fommil.netlib.BLAS <clinit>
WARNING: Failed to load implementation from: com.github.fommil.netlib.NativeRefBLAS
com.github.fommil.netlib.F2jBLAS
3. 参考:
此篇博客参考如下链接:
- Use Native BLAS/LAPACK in Apache Spark
- How to configure high performance BLAS/LAPACK for Breeze on Amazon EMR, EC2
- netlib-java#linux
- building spark
- spark mllib guide
4. 思路:
4.1 简单测试:
参考 2 中的代码,并添加可以打印当前使用的Classpath路径功能的代码,全部代码可以 fansy1990/als_blas 中进行checkout。
下载完代码后,直接导入到IntelliJ IDEA中,并编译打包,得到als_blas-1.0-SNAPSHOT.jar,然后即可执行:
./spark-submit --class demo.TestBLAS --master local[1] /root/als_blas-1.0-SNAPSHOT.jar 3000
执行命令后,得到如下所示信息。
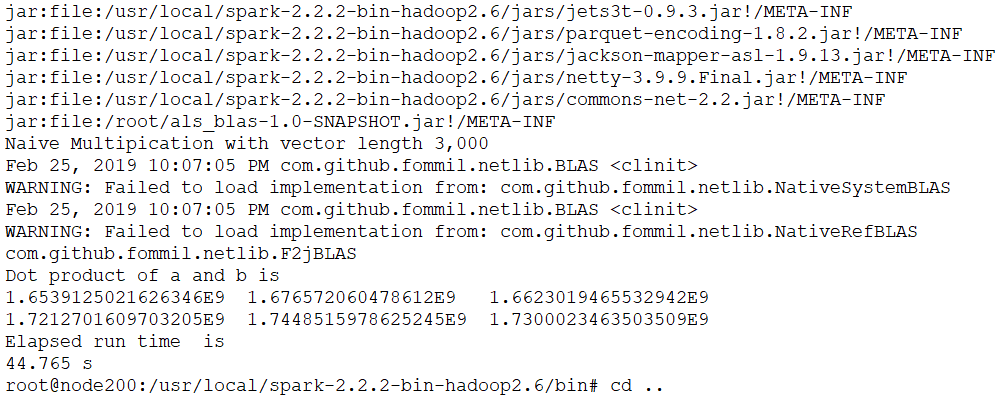
在图中可以看到:
- 其使用的Classpath是Spark安装目录下的jars路径下面的jar包;
- 代码并没有使用NativeSystemBLAS或NativeRefBLAS;
- 代码测试耗时44.765秒。
4.2 使用Native BLAS需要添加的Jar包
方式1:在Intellij IDEA 中添加依赖找到
- 在IDEA工程中直接运行demo.TestBLAS object,即可看到当前使用的Classpath;
- 通过在IDEA工程的pom.xml文件中加入
<dependency>
<groupId>com.github.fommil.netlib</groupId>
<artifactId>all</artifactId>
<version>1.1.2</version>
<type>pom</type>
</dependency>
依赖后,重新运行,可以发现其加载多了几个Jar包,如下:
jniloader-1.1.jar
netlib-native_ref-win-i686-1.1-natives.jar
netlib-native_system-win-i686-1.1-natives.jar
native_system-java-1.1.jar
native_ref-java-1.1.jar
netlib-native_ref-linux-armhf-1.1-natives.jar
netlib-native_system-linux-armhf-1.1-natives.jar
netlib-native_ref-linux-i686-1.1-natives.jar
netlib-native_system-linux-i686-1.1-natives.jar
netlib-native_ref-osx-x86_64-1.1-natives.jar
netlib-native_system-osx-x86_64-1.1-natives.jar
netlib-native_ref-win-x86_64-1.1-natives.jar
netlib-native_system-win-x86_64-1.1-natives.jar
netlib-native_ref-linux-x86_64-1.1-natives.jar
netlib-native_system-linux-x86_64-1.1-natives.jar
此Jar包即是所需的Jar包。
方式2: 自行指定参数编译Spark源码
下载Spark源码,并编译,编译时使用如下命令及参数:
C:\\"Program Files"\\apache-maven-3.6.0-bin\\apache-maven-3.3.9\\bin\\mvn \\
-Pnetlib-lgpl \\
-Pyarn \\
-Phive\\
-Phive-thriftserver \\
-DskipTests \\
clean package
其中,-netlib-lgpl就是使用Native BLAS必须加入的参数。
如下所示,即为编译完成后结果。

4.3 使用新编译的Spark测试是否加载Native BLAS
- 确认node201上是否有blas库,如下:
root@node201:~# update-alternatives --config libblas.so
update-alternatives: error: no alternatives for libblas.so
root@node201:~# update-alternatives --config libblas.so.3
There is only one alternative in link group libblas.so.3 (providing /usr/lib/libblas.so.3): /usr/lib/libblas/libblas.so.3
Nothing to configure.
可以看到有一个系统默认的库。
- 拷贝编译好的安装包到node201,并在其下运行:
./spark-submit --class demo.TestBLAS \\
--master local[1] \\
/root/als_blas-1.0-SNAPSHOT.jar \\
3000
运行后,可以看到如下信息:

从上面的信息可以看出:
- 其加载了本地的BLAS库
- 虽然加载了本地的BLAS库,但是还是很慢
- 尝试安装openblas
apt-get install libatlas3-base libopenblas-base
安装完成后,进行验证,如下:
root@node201:/opt/spark-2.2.2/bin# update-alternatives --config libblas.so
update-alternatives: error: no alternatives for libblas.so
root@node201:/opt/spark-2.2.2/bin# update-alternatives --config libblas.so.3
There are 3 choices for the alternative libblas.so.3 (providing /usr/lib/libblas.so.3).
Selection Path Priority Status
------------------------------------------------------------
* 0 /usr/lib/openblas-base/libblas.so.3 40 auto mode
1 /usr/lib/atlas-base/atlas/libblas.so.3 35 manual mode
2 /usr/lib/libblas/libblas.so.3 10 manual mode
3 /usr/lib/openblas-base/libblas.so.3 40 manual mode
Press <enter> to keep the current choice[*], or type selection number:
出现如上所示信息,即说明安装成功。
- 再次运行测试,如下:

说明:
- 使用自行编译的Spark能加载安装的openblas;
- 同时效率有了10x的提升!
5. 修改官网提供的安装包,使其加载BLAS
5.1 使用 --jars 参数
既然对比发现官网和自己编译打包的Spark安装包里面的Classpath只有几个不同的jar包,可以考虑把这些jar包加入到执行参数中,如下:
./spark-submit --class demo.TestBLAS \\
--master local[1] \\
--jars /root/jars/jniloader-1.1.jar,/root/jars/netlib-native_ref-win-x86_64-1.1-natives.jar,/root/jars/native_ref-java-1.1.jar,/root/jars/netlib-native_system-linux-armhf-1.1-natives.jar,/root/jars/native_system-java-1.1.jar,/root/jars/netlib-native_system-linux-i686-1.1-natives.jar,/root/jars/netlib-native_ref-linux-armhf-1.1-natives.jar,/root/jars/netlib-native_system-linux-x86_64-1.1-natives.jar,/root/jars/netlib-native_ref-linux-i686-1.1-natives.jar,/root/jars/netlib-native_system-osx-x86_64-1.1-natives.jar,/root/jars/netlib-native_ref-linux-x86_64-1.1-natives.jar,/root/jars/netlib-native_system-win-i686-1.1-natives.jar,/root/jars/netlib-native_ref-osx-x86_64-1.1-natives.jar,/root/jars/netlib-native_system-win-x86_64-1.1-natives.jar,/root/jars/netlib-native_ref-win-i686-1.1-natives.jar \\
/root/als_blas-1.0-SNAPSHOT.jar \\
3000
但是,经测试此方法失败,[此方法的失败在 1 中有提及]。
5.2 直接拷贝相关Jar包到$SPARK_HOME/jars路径中;
拷贝相关包到官网安装包的jars路径下:
cp /root/jars/* $SPARK_HOME/jars
测试通过,说明:拷贝相关包到$SPARK_HOME/jars的方式可行 !
6. 测试ALS是否有加速
本文问题的引入是因为使用Spark1.6版本,但是测试环境使用的是Spark2.2.2版本,故此测试环境可能也会有影响,例如Spark2.2.2是有对ALS做了优化的,下面也有提及此点。
6.1 测试数据
测试数据使用 MovieLens 1m dataset, 该数据集有6000用户,4000电影。
6.2 使用集群配置
集群使用本机虚拟机,1主3从的配置,其集群具体配置如下:

6.3 测试是否有BLAS的加速
- 直接运行测试类,命令如下:
spark-submit --class demo.AlsTest \\
--deploy-mode cluster \\
/root/als_blas-1.1-SNAPSHOT.jar 3000
经过多次测试,发现:
- 耗时平均在1.2mins;

- 子节点出现没有使用Native BLAS的提示;

- 使用BLAS再次测试
(1)拷贝相关Jar包到所有集群节点的$SPARK_HOME/jars;
(2)在集群各个子节点安装openblas,参考上面的命令;
(3)再次运行,发现其耗时仍是1.2mins,同时也仍有没有使用Native BLAS的提示;
- 使用编译的Spark 进行测试;
- 耗时1.4mins,程序变得更慢;

- 在子节点没有出现未使用Native BLAS的提示,说明已经使用了BLAS库;
7. 总结
- 如果要使用Spark ALS算法,建议使用Spark2.x以上,效率更快;
- 如果只能使用Spark1.x,建议使用自行编译的Spark安装包,可以应用Native BLAS进行加速([有待验证!])
- 如果使用Spark2.x的自行编译的安装包,那么针对Spark中ALS算法,其推荐效率更低。这点其实在其源码中也有说明,如下所示。
private def recommendForAll(
rank: Int,
srcFeatures: RDD[(Int, Array[Double])],
dstFeatures: RDD[(Int, Array[Double])],
num: Int): RDD[(Int, Array[(Int, Double)])] =
val srcBlocks = blockify(srcFeatures)
val dstBlocks = blockify(dstFeatures)
val ratings = srcBlocks.cartesian(dstBlocks).flatMap case (srcIter, dstIter) =>
val m = srcIter.size
val n = math.min(dstIter.size, num)
val output = new Array[(Int, (Int, Double))](m * n)
var i = 0
val pq = new BoundedPriorityQueue[(Int, Double)](n)(Ordering.by(_._2))
srcIter.foreach case (srcId, srcFactor) =>
dstIter.foreach case (dstId, dstFactor) =>
// We use F2jBLAS which is faster than a call to native BLAS for vector dot product
val score = BLAS.f2jBLAS.ddot(rank, srcFactor, 1, dstFactor, 1)
pq += dstId -> score
pq.foreach case (dstId, score) =>
output(i) = (srcId, (dstId, score))
i += 1
pq.clear()
output.toSeq
ratings.topByKey(num)(Ordering.by(_._2))
以上是关于Spark依赖包加载顺序的主要内容,如果未能解决你的问题,请参考以下文章