深入源码分析Linux进程模型
Posted 林佳麒
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深入源码分析Linux进程模型相关的知识,希望对你有一定的参考价值。
1. 前言(实验内容)
- 操作系统是怎么组织进程的
- 进程状态如何转换(给出进程状态转换图)
- 进程是如何调度的
- 谈谈自己对该操作系统进程模型的看法
2.关于进程
(1)定义:
进程(Process)是计算机中的程序关于某数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位,是操作系统结构的基础。在早期面向进程设计的计算机结构中,进程是程序的基本执行实体;在当代面向线程设计的计算机结构中,进程是线程的容器。程序是指令、数据及其组织形式的描述,进程是程序的实体。进程的概念主要有两点:第一,进程是一个实体。每一个进程都有它自己的地址空间,一般情况下,包扩文本区域(text region)、数据区域(data region)和堆栈(stack region)。文本区域存储处理器执行的代码;数据区域存储变量和进程执行期间使用的动态分配的内存;堆栈区域存储着活动过程调用的指令和本地变量。第二,进程是一个“执行中的程序”。程序是一个没有生命的实体,只有处理器赋予程序生命时(操作系统执行之),它才能成为一个活动的实体,我们称其为进程。
(2)进程的特征:
- 动态性:进程的实质是程序在多道程序系统中的一次执行过程,进程是动态产生、消亡的;
- 并发性:任何进程都可以同其他进程一起并发执行;
- 独立性:进程是一个能独立运行的基本单位,同时也是系统分配资源和调度的独立单位;
- 异步性:由于进程间的相互制约,使得进程具有执行的间断性,即进程按各自独立的、不可预知的速度向前推进;
(3)进程与程序、线程的区别:
在面向进程设计的系统(如早期的UNIX,Linux 2.4及更早的版本)中,进程是程序的基本执行实体;在面向线程设计的系统(如当代多数操作系统、Linux 2.6及更新的版本)中,进程本身不是基本运行单位,而是线程的容器。简单地来说,进程与程序是动态与静止的区别,进程与程序是多对一的,同样,线程与进程也是多对一的。
3.1 操作系统是如何组织进程的
在Linux系统中, 进程在/linux/include/linux/sched.h 头文件中被定义为task_struct, 它是一个结构体, 一个它的实例化即为一个进程, task_struct由许多元素构成, 下面列举一些重要的元素进行分析。
- 标识符:与进程相关的唯一标识符,用来区别正在执行的进程和其他进程。
- 状态:描述进程的状态,因为进程有挂起,阻塞,运行等好几个状态,所以都有个标识符来记录进程的执行状态。
- 优先级:如果有好几个进程正在执行,就涉及到进程被执行的先后顺序的问题,这和进程优先级这个标识符有关。
- 程序计数器:程序中即将被执行的下一条指令的地址。
- 内存指针:程序代码和进程相关数据的指针。
- 上下文数据:进程执行时处理器的寄存器中的数据。
- I/O状态信息:包括显示的I/O请求,分配给进程的I/O设备和被进程使用的文件列表等。
- 记账信息:包括处理器的时间总和,记账号等等。
3.1 进程状态(STATE)
在task_struct结构体中, 定义进程的状态语句为
volatile long state; /* -1 unrunnable, 0 runnable, >0 stopped */valatile关键字的作用是确保本条指令不会因编译器的优化而省略, 且要求每次直接读值, 这样保证了对进程实时访问的稳定性。
进程在/linux/include/linux/sched.h 头文件中我们可以找到state的可能取值如下
/*
* Task state bitmask. NOTE! These bits are also
* encoded in fs/proc/array.c: get_task_state().
* We have two separate sets of flags: task->state
* is about runnability, while task->exit_state are
* the task exiting. Confusing, but this way
* modifying one set can‘t modify the other one by
* mistake.
*/
define TASK_RUNNING 0
define TASK_INTERRUPTIBLE 1
define TASK_UNINTERRUPTIBLE 2
define TASK_STOPPED 4
define TASK_TRACED 8/* in tsk->exit_state */
define EXIT_ZOMBIE 16
define EXIT_DEAD 32/* in tsk->state again */
define TASK_NONINTERACTIVE 64
define TASK_DEAD 128
根据state后面的注释, 可以得到当state<0时,表示此进程是处于不可运行的状态, 当state=0时, 表示此进程正处于运行状态, 当state>0时, 表示此进程处于停止运行状态。
以下列举一些state的常用取值
| 状态 | 描述 |
| :---------------------- | :----------------------------------------------------------- |
| 0(TASK_RUNNING) | 进程处于正在运行或者准备运行的状态中 |
| 1(TASK_INTERRUPTIBLE) | 进程处于可中断睡眠状态, 可通过信号唤醒 |
| 2(TASK_UNINTERRUPTIBLE) | 进程处于不可中断睡眠状态, 不可通过信号进行唤醒 |
| 4( TASK_STOPPED) | 进程被停止执行 |
| 8( TASK_TRACED) | 进程被监视 |
| 16( EXIT_ZOMBIE) | 僵尸状态进程, 表示进程被终止, 但是其父程序还未获取其被终止的信息。 |
| 32(EXIT_DEAD) | 进程死亡, 此状态为进程的最终状态 |
3.2 进程标识符(PID)
c pid_t pid; /*进程的唯一表示*/ pid_t tgid; /*进程组的标识符*/
在Linux系统中,一个线程组中的所有线程使用和该线程组的领头线程(该组中的第一个轻量级进程)相同的PID,并被存放在tgid成员中。只有线程组的领头线程的pid成员才会被设置为与tgid相同的值。注意,getpid()系统调用返回的是当前进程的tgid值而不是pid值。(线程是程序运行的最小单位,进程是程序运行的基本单位。)
3.3 进程的标记(FLAGS)
unsigned int flags; /* per process flags, defined below */反应进程状态的信息,但不是运行状态,用于内核识别进程当前的状态,以备下一步操作
flags成员的可能取值如下,这些宏以PF(ProcessFlag)开头
3.4 进程之间的关系
/*
* pointers to (original) parent process, youngest child, younger sibling,
* older sibling, respectively. (p->father can be replaced with
* p->parent->pid)
*/
struct task_struct *real_parent; /* real parent process (when being debugged) */
struct task_struct *parent; /* parent process */
/*
* children/sibling forms the list of my children plus the
* tasks I‘m ptracing.
*/
struct list_head children; /* list of my children */
struct list_head sibling; /* linkage in my parent‘s children list */
struct task_struct *group_leader; /* threadgroup leader */在Linux系统中,所有进程之间都有着直接或间接地联系,每个进程都有其父进程,也可能有零个或多个子进程。拥有同一父进程的所有进程具有兄弟关系。
real_parent指向其父进程,如果创建它的父进程不再存在,则指向PID为1的init进程。 parent指向其父进程,当它终止时,必须向它的父进程发送信号。它的值通常与 real_parent相同。 children表示链表的头部,链表中的所有元素都是它的子进程(进程的子进程链表)。 sibling用于把当前进程插入到兄弟链表中(进程的兄弟链表)。 group_leader指向其所在进程组的领头进程。
3.5 进程调度
3.5.1 优先级
int prio, static_prio, normal_prio;
unsigned int rt_priority;
/*
prio: 用于保存动态优先级
static_prio: 用于保存静态优先级, 可以通过nice系统调用来修改
normal_prio: 它的值取决于静态优先级和调度策略
priort_priority: 用于保存实时优先级
*/3.5.2 调度策略
unsigned int policy;
cpumask_t cpus_allowed;
/*
policy: 表示进程的调度策略
cpus_allowed: 用于控制进程可以在哪个处理器上运行
*/policy表示进程调度策略, 目前主要有以下五种策略
/*
* Scheduling policies
*/
#define SCHED_NORMAL 0 //按优先级进行调度
#define SCHED_FIFO 1 //先进先出的调度算法
#define SCHED_RR 2 //时间片轮转的调度算法
#define SCHED_BATCH 3 //用于非交互的处理机消耗型的进程
#define SCHED_IDLE 5//系统负载很低时的调度算法
字段 描述 所在调度器类 SCHED_NORMAL (也叫SCHED_OTHER)用于普通进程,通过CFS调度器实现。SCHED_BATCH用于非交互的处理器消耗型进程。SCHED_IDLE是在系统负载很低时使用 CFS SCHED_FIFO 先入先出调度算法(实时调度策略),相同优先级的任务先到先服务,高优先级的任务可以抢占低优先级的任务 RT SCHED_RR 轮流调度算法(实时调度策略),后 者提供 Roound-Robin 语义,采用时间片,相同优先级的任务当用完时间片会被放到队列尾部,以保证公平性,同样,高优先级的任务可以抢占低优先级的任务。不同要求的实时任务可以根据需要用sched_setscheduler()API 设置策略 RT SCHED_BATCH SCHED_NORMAL普通进程策略的分化版本。采用分时策略,根据动态优先级(可用nice()API设置),分配 CPU 运算资源。注意:这类进程比上述两类实时进程优先级低,换言之,在有实时进程存在时,实时进程优先调度。但针对吞吐量优化 CFS SCHED_IDLE 优先级最低,在系统空闲时才跑这类进程(如利用闲散计算机资源跑地外文明搜索,蛋白质结构分析等任务,是此调度策略的适用者) CFS
3.6 进程的地址空间
进程都拥有自己的资源,这些资源指的就是进程的地址空间,每个进程都有着自己的地址空间,在task_struct中,有关进程地址空间的定义如下:
struct mm_struct *mm, *active_mm;
/*
mm: 进程所拥有的用户空间内存描述符,内核线程无的mm为NULL
active_mm: active_mm指向进程运行时所使用的内存描述符, 对于普通进程而言,这两个指针变量的值相同。但是内核线程kernel thread是没有进程地址空间的,所以内核线程的tsk->mm域是空(NULL)。但是内核必须知道用户空间包含了什么,因此它的active_mm成员被初始化为前一个运行进程的active_mm值。
*/如果当前内核线程被调度之前运行的也是另外一个内核线程时候,那么其mm和avtive_mm都是NULL
以上即为操作系统是怎么组织进程的一些分析, 有了这些作为基础, 我们就可以进行下一步的分析
4.进程状态之间是如何转换的
关于linux进程状态(STATE)的定义, 取值以及描述都在进程状态中进行了详细的分析, 这里就不做过多的赘述。
下面给出进程的各种状态之间是如何进行互相转换的关系图:
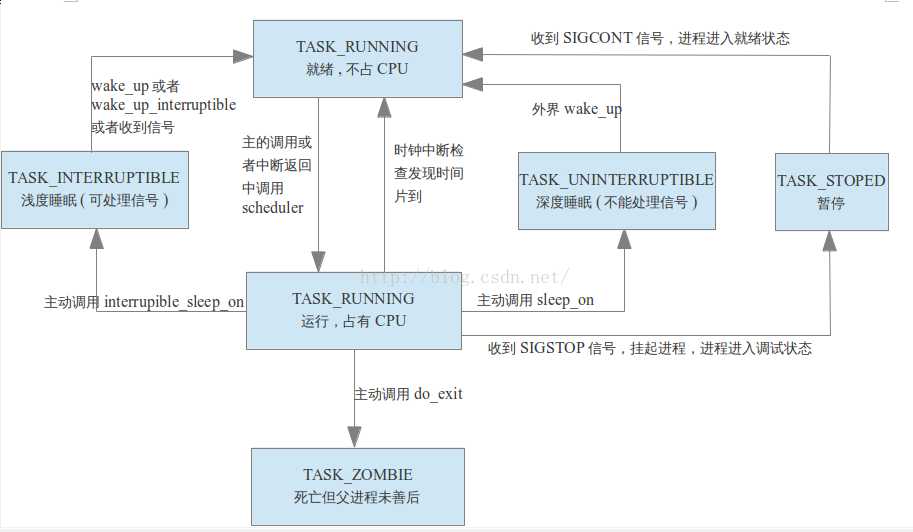
5.进程是如何进行调度的
5.1 与进程调度有关的数据结构
在了解进程是如何进行调度之前, 我们需要先了解一些与进程调度有关的数据结构。
5.1.1 可运行队列(runqueue)
在/kernel/sched.c文件下, 可运行队列被定义为struct rq, 每一个CPU都会拥有一个struct rq, 它主要被用来存储一些基本的用于调度的信息, 包括及时调度和CFS调度。在Linux kernel 2.6中, struct rq是一个非常重要的数据结构, 接下来我们介绍一下它的部分重要字段:
/* 选取出部分字段做注释 */
//runqueue的自旋锁,当对runqueue进行操作的时候,需要对其加锁。由于每个CPU都有一个runqueue,这样会大大减少竞争的机会
spinlock_t lock;
// 此变量是用来记录active array中最早用完时间片的时间
unsigned long expired_timestamp;
//记录该CPU上就绪进程总数,是active array和expired array进程总数和
unsigned long nr_running;
// 记录该CPU运行以来发生的进程切换次数
unsigned long long nr_switches;
// 记录该CPU不可中断状态进程的个数
unsigned long nr_uninterruptible;
// 这部分是rq的最最最重要的部分, 我将在下面仔细分析它们
struct prio_array *active, *expired, arrays[2];5.1.2 优先级数组(prio_array)
Linux kernel 2.6版本中, 在rq中多加了两个按优先级排序的数组active array和expired array 。
这两个队列的结构是struct prio_array, 它被定义在/kernel/sched.c中, 其数据结构为:
struct prio_array {
unsigned int nr_active; //
DECLARE_BITMAP(bitmap, MAX_PRIO+1); /* include 1 bit for delimiter */
/*开辟MAX_PRIO + 1个bit的空间, 当某一个优先级的task正处于TASK_RUNNING状态时, 其优先级对应的二进制位将会被标记为1, 因此当你需要找此时需要运行的最高的优先级时, 只需要找到bitmap的哪一位被标记为1了即可*/
struct list_head queue[MAX_PRIO]; // 每一个优先级都有一个list头
};Active array表示的是CPU选择执行的运行进程队列, 在这个队列里的进程都有时间片剩余, *active指针总是指向它。
Expired array则是用来存放在Active array中使用完时间片的进程, *expired指针总是指向它。
一旦在active array里面的某一个普通进程的时间片使用完了, 调度器将重新计算该进程的时间片与优先级, 并将它从active array中删除, 插入到expired array中的相应的优先级队列中 。
当active array内的所有task都用完了时间片, 这时只需要将*active与*expired这两个指针交换下, 即可切换运行队列。
5.2 调度算法(O(1)算法)
5.2.1 介绍O(1)算法
何为O(1)算法: 该算法总能够在有限的时间内选出优先级最高的进程然后执行, 而不管系统中有多少个可运行的进程, 因此命名为O(1)算法。
5.2.2 O(1)算法的原理
在前面我们提到了两个按优先级排序的数组active array和expired array, 这两个数组是实现O(1)算法的关键所在。
O(1)调度算法每次都是选取在active array数组中且优先级最高的进程来运行。
那么该算法如何找到优先级最高的进程呢? 大家还记得前面prio_array内的DECLARE_BITMAP(bitmap, MAX_PRIO+1);字段吗?这里它就发挥出作用了(详情看代码注释), 这里只要找到bitmap内哪一个位被设置为了1, 即可得到当前系统所运行的task的优先级(idx, 通过sehed_find_first_bit()方法实现), 接下来找到idx所对应的进程链表(queue), queue内的所有进程都是目前可运行的并且拥有最高优先级的进程, 接着依次执行这些进程,。
该过程定义在schedule函数中, 主要代码如下:
struct task_struct *prev, *next;
struct list_head *queue;
struct prio_array *array;
int idx;
prev = current;
array = rq->active;
idx = sehed_find_first_bit(array->bitmap); //找到位图中第一个不为0的位的序号
queue = array->queue + idx; //得到对应的队列链表头
next = list_entry(queue->next, struct task_struct, run_list); //得到进程描述符
if (prev != next) //如果选出的进程和当前进程不是同一个,则交换上下文
context_switch();
6. 对该操作系统进程模型的看法
很多年前就有人说Linux必定会取代Windows,已经过去这么多年了,就我所知道的是使用Windows越来越多,放弃Linux的也越来越多。很简单,从桌面端来说,我认为Linux是不能战胜Windows的,Windows是由有积极进取心的商业公司生产出来的,漂亮、迷人、方便。而Linux不是技术不行,而是这种东西做出来,基本上没有人欣赏,旁人很难理解的。但Linux有它的优点,就凭这个我支持。可它不做改变的话,就只能保持着这个状态,在一堆狂热的职业或业余的程序员中间流传着。
7. 参考资料
- https://blog.csdn.net/bit_clearoff/article/details/54292300
- https://blog.csdn.net/qq_29503203/article/details/54618275
- https://blog.csdn.net/gatieme/article/details/51383272
- https://blog.csdn.net/bullbat/article/details/7160246
- Linux kernel 2.6 源码下载链接
以上是关于深入源码分析Linux进程模型的主要内容,如果未能解决你的问题,请参考以下文章