第一次作业:深入Linux源码分析其进程模型
Posted marsur
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第一次作业:深入Linux源码分析其进程模型相关的知识,希望对你有一定的参考价值。
一、进程
1.进程的概念
(1)进程:Process,是计算机中的程序关于某数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位,是操作系统结构的基础。
(2)进程由程序、数据和进程控制块PCB组成。当系统创建一个进程时,实际上是建立一个PCB。当进程消失时,实际上是撤销PCB。在进程活动的整个生命周期内,系统通过PCB对进程进行管理和调度。
2.查看进程状态
(1)ps指令(常用组合:aux、ef、eFH、-eo、axo)
(2)示例
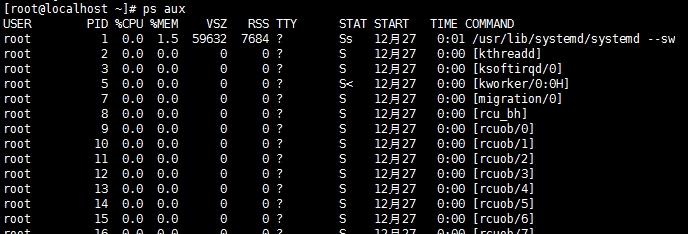
# ps aux:显示所有与终端有无关联的进程信息
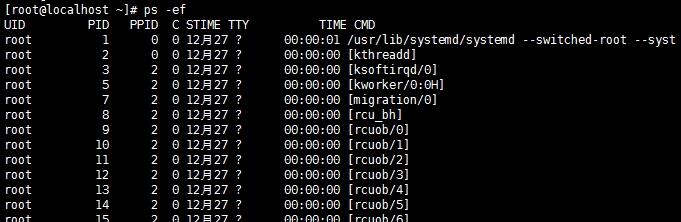
# ps -ef:以完整格式显示所有的进程信息
二、进程的组织
在Linux中,每个进程都有自己的task_struct结构。在2.4.0版中,系统拥有的进程取决于物理内存的大小。因此进程数可能达到成千上万个。为了对系统中的很多进程及处于不同状态的进程进行管理,Linux采用了以下几种组织方式来管理进程:
1.哈希表
哈希表是进行快速查找的一种有效的组织方式,在include/linux/sched.h中定义如下:
struct task_struct* pidhash[PIDHASH_SZ];
linux用一个宏pid_hashfn()将PID转换成表的索引,通过pid_hashfn()可以把进程的PID均匀的散列在哈希表中。
给定一个进程号PID寻找其对应的PCB的查找函数如下:
static inline struct task_struct * find_task_by_pid(int pid){
struct task_struct *p, **htable = &pidhash[pid_hashfn()];
for(p = *htable; p && p->pid != pid; p = pidhash->next)
return p;
}
2.进程链表
用双向循环链表将进程联系起来,定义如下:
struct task_struct{
struct list_head tasks;
char comm[TASK_COM_LEN];//可执行程序的名字带路径
}
每个进程task_struct结构中的prev_task和next_task成员用来实现这种链表,链表的头和尾都是init_task(即0号进程),这个进程永远不会被撤销地被静态分配在内核数据段中。
通过宏for_each_task可以方便地搜索所有进程:
#define for_each_task(p)
for(p=&init_task;(p=p->next_task)!=&init_task;)
3.就绪队列
把所有可运行状态的进程组成的一个双向链表叫做就绪队列,该队列通过task_struct结构中的两个指针run_list链表来维护:
struct task_struct{
struct list_head run_list;
,,,
}
就绪队列的定义及相关操作在/kernel/sched.c文件中:
static LIST_HEAD(runqueue_head);//定义就绪队列的头指针为runqueue_head
static inline void add_to_runqueue(struct task_struct *p){
list_add_tail(&p->run_list, &runqueue_head);
nr_running++;
}
static inline void move_last_runqueue(struct task_struct *p){
list_del(&p->run_list);
list_add_tail(&p->run_list, &runqueue_head);
}
三、进程的状态转换
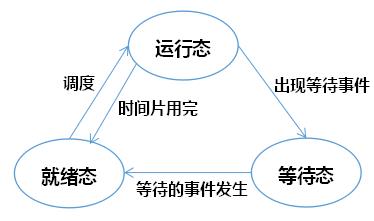
1.三种基本状态
(1)运行态(running):进程正在处理机上运行。
(2)就绪态(ready):进程具备运行条件,等待系统分配处理器以便运行。
(3)等待态(blocked):不具备运行条件,正在等待某个事件的完成。
2.四种状态转换
(1)运行态→等待态:当进程请求某一资源(如外设)的使用和分配或等待某一事件的发生(如I/O操作的完成)时,它就从运行状态转换为等待状态。
(2)等待态→就绪态:当进程等待的事件到来时(如I/O操作结束或中断结束),中断处理程序必须把相应进程的状态由等待状态转换为就绪状态。
(3)运行态→就绪态:处于运行状态的进程在时间片用完后,不得不让出处理机,从而进程由运行状态转换为就绪状态。
(4)就绪态→运行态:处于就绪状态的进程被调度后,获得处理机资源(分派处理机时间片),于是进程由就绪状态转换为运行状态。
3.状态转换图
(1)三态模型
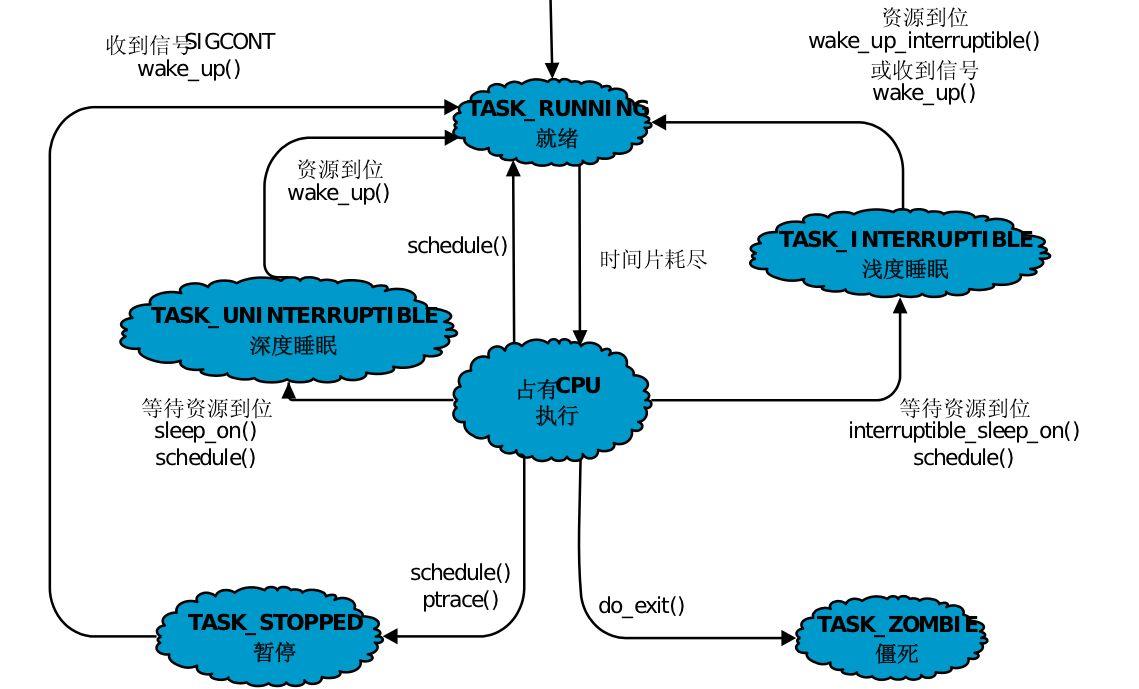
(2)多态模型
四、进程的调度
1.调度方式
(1)非剥夺调度方式(非抢占方式):实现简单,系统开销小,适用于大多数的批处理系统,但它不能用于分时系统和大多数的实时系统。
(2)剥夺调度方式(抢占方式):要遵循一定的原则,主要有:优先级、短进程优先和时间片原则。
2.调度算法
(1)先来先服务(FCFS first come first serve):属于不可剥夺算法。算法每次从后备作业队列中选择最先进入该队列的一个或几个作业进行处理。
特点:算法简单,效率低,对长作业有利,对短作业不利。
(2)短作业优先(SJF short job first):算法从后备队列中选择一个或若干个估计运行时间最短的作业处理。直到完成作业或发生某事件而阻塞时,才释放处理机。
缺点:(1)对长作业不利,造成“饥饿”现象(2)未考虑作业紧迫程度(3)由于运行时间是估计所得,所以并不一定能做到短作业优先。
(3)优先级:可分为(1)非剥夺式(2)剥夺式;其中优先级可分为:(1)静态优先级(2)动态优先级
(4)高响应比优先:响应比=(等待时间+处理时间)/处理时间=1+等待时间/处理时间
(5)时间片轮转
五、CFS调度器
1.设计思想:根据各个进程的权重分配运行时间
2.虚拟运行时间
vruntime = (调度周期 * 进程权重 / 所有进程总权重) * 1024 / 进程权重
=调度周期 * 1024 / 所有进程总权重
通过公式可知,所有进程的vruntime增长速度宏观上看是同时推进的,那么就可以用这个vruntime来选择运行的进程,vruntime值越小说明以前占用cpu的时间越短,受到了“不公平”的对待,因此下一个运行进程就是它。这样既能公平选择进程,又能保证高优先级进程获得较多的运行时间。
3.调度实体
调度实体sched_entity,代表一个调度单位,在组调度关闭的时候可以把他等同为进程。
每一个task_struct中都有一个sched_entity,进程的vruntime和权重都保存在这个结构中。所有的sched_entity以vruntime为key插入到红黑树中,同时缓存树的最左侧节点,也就是vruntime最小的节点,这样可以迅速选中vruntime最小的进程。
关系图如下:

4.主要代码
(1)创建进程
进程创建时CFS相关变量的初始化:
void wake_up_new_task(struct task_struct *p, unsigned long clone_flags)
{
.....
if (!p->sched_class->task_new || !current->se.on_rq) {
activate_task(rq, p, 0);
} else {
/*
* Let the scheduling class do new task startup
* management (if any):
*/
p->sched_class->task_new(rq, p);
inc_nr_running(rq);
}
check_preempt_curr(rq, p, 0);
.....
}
Linux创建进程使用fork或者clone或者vfork等系统调用,最终都会到do_fork。
如果没有设置CLONE_STOPPED,则会进入wake_up_new_task函数。
(2)唤醒进程
static int try_to_wake_up(struct task_struct *p, unsigned int state, int sync)
{
int cpu, orig_cpu, this_cpu, success = 0;
unsigned long flags;
struct rq *rq;
rq = task_rq_lock(p, &flags);
if (p->se.on_rq)
goto out_running;
update_rq_clock(rq);
activate_task(rq, p, 1);
success = 1;
out_running:
check_preempt_curr(rq, p, sync);
p->state = TASK_RUNNING;
out:
current->se.last_wakeup = current->se.sum_exec_runtime;
task_rq_unlock(rq, &flags);
return success;
}
update_rq_clock就是更新cfs_rq的时钟,保持与系统时间同步。
重点是activate_task,它将进程加入红黑树并且对vruntime做一些调整,然后用check_preempt_curr检查是否构成抢占条件,如果可以抢占则设置TIF_NEED_RESCHED标识。
(3)进程调度
asmlinkage void __sched schedule(void)
{
struct task_struct *prev, *next;
unsigned long *switch_count;
struct rq *rq;
int cpu;
need_resched:
preempt_disable(); //在这里面被抢占可能出现问题,先禁止它
cpu = smp_processor_id();
rq = cpu_rq(cpu);
rcu_qsctr_inc(cpu);
prev = rq->curr;
switch_count = &prev->nivcsw;
release_kernel_lock(prev);
need_resched_nonpreemptible:
spin_lock_irq(&rq->lock);
update_rq_clock(rq);
clear_tsk_need_resched(prev); //清除需要调度的位
/*state==0是TASK_RUNNING,不等于0就是准备睡眠,正常情况下应该将它移出运行队列
但是还要检查下是否有信号过来,如果有信号并且进程处于可中断睡眠就唤醒它
对于需要睡眠的进程,这里调用deactive_task将其移出队列并且on_rq也被清零*/
if (prev->state && !(preempt_count() & PREEMPT_ACTIVE)) {
if (unlikely(signal_pending_state(prev->state, prev)))
prev->state = TASK_RUNNING;
else
deactivate_task(rq, prev, 1);
switch_count = &prev->nvcsw;
}
if (unlikely(!rq->nr_running))
idle_balance(cpu, rq);
prev->sched_class->put_prev_task(rq, prev);
next = pick_next_task(rq, prev);
if (likely(prev != next)) {
sched_info_switch(prev, next);
rq->nr_switches++;
rq->curr = next;
++*switch_count;
//完成进程切换
context_switch(rq, prev, next); /* unlocks the rq */
/*
* the context switch might have flipped the stack from under
* us, hence refresh the local variables.
*/
cpu = smp_processor_id();
rq = cpu_rq(cpu);
} else
spin_unlock_irq(&rq->lock);
if (unlikely(reacquire_kernel_lock(current) < 0))
goto need_resched_nonpreemptible;
preempt_enable_no_resched();
//这里新进程也可能有TIF_NEED_RESCHED标志,如果新进程也需要调度则再调度一次
if (unlikely(test_thread_flag(TIF_NEED_RESCHED)))
goto need_resched;
}
(4)时钟中断
时钟中断在time_init_hook中初始化,中断函数为timer_interrupt。
entity_tick函数:更新状态信息,检测是否满足抢占条件。
static void
entity_tick(struct cfs_rq *cfs_rq, struct sched_entity *curr, int queued)
{
/*
* Update run-time statistics of the \'current\'.
*/
update_curr(cfs_rq);
//....无关代码
if (cfs_rq->nr_running > 1 || !sched_feat(WAKEUP_PREEMPT))
check_preempt_tick(cfs_rq, curr);
}
5.CFS小结
CFS还有一个重要特点,即调度粒度小。CFS之前的调度器中,除了进程调用了某些阻塞函数而主动参与调度之外,每个进程都只有在用完了时间片或者属于自己的时间配额之后才被抢占。而CFS则在每次tick都进行检查,如果当前进程不再处于红黑树的左边,就被抢占。在高负载的服务器上,通过调整调度粒度能够获得更好的调度性能。
六、对Linux进程模型的看法
普通进程的调度策略和非实时进程相比较为麻烦,因为它不能简单地只看优先级,必须公平的占有CPU,否则容易出现进程饥饿,造成用户响应慢的问题。因此,Linux在发展历程中不断对调度器进行改善,希望寻找一个最接近于完美的调度策略来公平快速地调度进程。CFS是Linux内核2.6.23版本开始采用的进程调度器,核心思想是“完全公平”,它将所有的进程都统一对待,实现了所有进程的公平调度。虽然CFS性能优越,避免了上一代调度器O(1)带来的很多问题,但以Linux精益求精的精神来看,我相信今后将会出现一个更优秀的调度器来取代CFS,满足更多的需求。
七、参考资料
1.http://blog.51cto.com/xuding/1741861 Linux进程管理
2.https://blog.csdn.net/qwe6112071/article/details/70473905 操作系统之进程的状态和转换详解
3.https://blog.csdn.net/yusiguyuan/article/details/39404399 linux内核CFS进程调度策略
以上是关于第一次作业:深入Linux源码分析其进程模型的主要内容,如果未能解决你的问题,请参考以下文章