sql语句 group by和order by
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了sql语句 group by和order by相关的知识,希望对你有一定的参考价值。
表1: 客户 客户类型 所属业务员 name1 a wang name2 a wang name3 a wang name4 a li name5 b li name6 a li name7 b li sql语句? 表2: 所属业务员 客户类型 客户数 li a 2 li b 2 wang a 3 统计出来的表2按所属业务员的客户总数排序(li:4;wang:3)
参考技术A selects1.所属业务员,
s1.客户类型,
s1.客户数
from
(
select
所属业务员,客户类型,count(客户)
客户数
from
表1
group
by
所属业务员,客户类型
order
by
所属业务员,客户类型
)
s1,
(
--
计算每个业务员负责的客户总数,仅用于排序不显示在结果集中
select
所属业务员,count(客户)
客户总数
from
表1
group
by
所属业务员
)
s2
where
s1.所属业务员
=
s2.所属业务员
order
by
s2.客户总数
desc,
s1.客户类型,
s1.客户数
sql中order by和group by的区别
order by 和 group by 的区别:
1,order by 从英文里理解就是行的排序方式,默认的为升序。 order by 后面必须列出排序的字段名,可以是多个字段名。
2,group by 从英文里理解就是分组。必须有“聚合函数”来配合才能使用,使用时至少需要一个分组标志字段。
3,在使用group by的语句中,只能select用于分类的列(表达式),或聚合函数。where条件用于group by之前,having用于group by 之后对结果进行筛选。
扩展资料:
一、order by用法: 排序查询、asc升序、desc降序
示例:
1.select * from 学生表
2.order by 年龄
3.查询学生表信息、按年龄的升序(默认、可缺省、从低到高)排列显示也可以多条件排序、 比如 order by 年龄,成绩 desc
4.按年龄升序排列后、再按成绩降序排列。二、group by用法: 分组查询、having 只能用于group by子句、作用于组内,having条件子句可以直接跟函数表达式。使用group by 子句的查询语句需要使用聚合函数。
示例:
1.select 学号,SUM(成绩) from 选课表 group by 学号 按学号分组、查询每个学号的总成绩
2.select 学号,AVG(成绩) from 选课表
3.group by 学号
4.having AVG(成绩)>(select AVG(成绩) from 选课表 where 课程号=‘001‘)
5.order by AVG(成绩) desc
6.查询平均成绩大于001课程平均成绩的学号、并按平均成绩的降序排列。
1、解释不同
order by是SQL语句中的关键字,用于对查询结果的排序。ORDER BY 语句用于对结果集进行排序,默认的为升序。
group by语句从英文的字面意义上理解就是“根据(by)一定的规则进行分组(Group)”。它的作用是通过一定的规则将一个数据集划分成若干个小的区域,然后针对若干个小区域进行数据处理。
2、字段不同
order by是按字段排序,后面必须列出排序的字段名,可以是多个字段名。
group by是按字段分类 ,必须有“聚合函数”来配合才能使用,使用时至少需要一个分组标志字段。
3、sql命令格式优先顺序不同
group By关键字先对指定的分组条件将筛选得到的视图进行分组,将分组视图后不满足条件的记录筛选掉。
order By语句最后对视图进行排序,最终的结果就产生了。
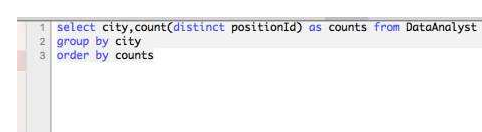
扩展资料
order by和group by的用法示例
1、select * from 学生表 order by 年龄
查询学生表信息、按年龄的升序(默认、可缺省、从低到高)排列显示。
2、select 学号,SUM(成绩) from 选课表 group by 学号
按学号分组、查询每个学号的总成绩。
3、select 学号,AVG(成绩) from 选课表 group by 学号 having AVG(成绩)>(select AVG(成绩) from 选课表 where 课程号=‘001‘) order by AVG(成绩) desc
查询平均成绩大于001课程平均成绩的学号、并按平均成绩的降序排列。
经常见sql语句中order by 1或者order by 2...order by N,有时候很莫名其妙.其实1表示第一个栏位,2表示第二栏位; 依此类推,当表中只有2个栏位时,oder by 3就会出错,这个跟order by 列名没有什么区别,不过在特殊情况下还是很有用的.
例如table1(p_code int,issue_date datetime,issue_num int)
p_code issue_date issue_num
101 2016-12-01 00:00:00.000 45
102 2016-12-01 00:00:00.000 89
102 2016-12-03 00:00:00.000 44
103 2016-12-03 00:00:00.000 44
101 2016-12-02 00:00:00.000 44
101 2016-12-03 00:00:00.000 44
101 2016-12-03 00:00:00.000 45
101 2016-12-03 00:00:00.000 44
101 2016-12-03 00:00:00.000 44
102 2016-12-03 00:00:00.000 47
101 2016-12-03 00:00:00.000 48
104 2016-12-03 00:00:00.000 86
101 2016-12-03 00:00:00.000 56
101 2016-12-03 00:00:00.000 29
101 2016-12-11 00:00:00.000 11
我想获取某个p_code过去(不含当天)10次的issue_num平均值,
可能我们会这么写
select top 10 p_code, avg(issue_num) as avgissue from table1
where issue_date<>(select convert(varchar(10),getdate(),120))
and p_code=‘101‘
group by p_code
order by issue_date desc
但是以上写法是错误,的,会提示 Column "table1.issue_date" is invalid in the ORDER BY clause because it is not contained in either an aggregate function or the GROUP BY clause.必须要求issue_date在group by中.
所以我们改成
select top 10 p_code, avg(issue_num) as avgissue from table1
where issue_date<>(select convert(varchar(10),getdate(),120))
and p_code=‘101‘
group by p_code,issue_date
order by issue_date desc
但是得到的结果却是(今天是2016.12.11)
p_code avgissue
101 44
101 44
101 45
显然以上不是我们想要的结果.
那么该如何结果这种问题呢,当然你可以再次进行avg()聚合运算,但是这里我们既然说oder by N,那么就用这个知识来解决.
语句如下.
select top 10 p_code, avg(issue_num) as avgissue from table1
where issue_date<>(select convert(varchar(10),getdate(),120))
and p_code=‘101‘
group by p_code
order by 2 desc
结果如下(今天是2016.12.11)
p_code avgissue
101 44
是不是很神奇呢!
当然作为码农,我们尽量用列名来解决,以便增加代码的可读性和易维护性.
以上是关于sql语句 group by和order by的主要内容,如果未能解决你的问题,请参考以下文章