求大神指教C语言中的位域
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了求大神指教C语言中的位域相关的知识,希望对你有一定的参考价值。
为什么以下的 sizeof(A) 和 sizeof(B)都是4呢?
struct A
int a:5;
int b:3;
struct B
int a:3;
int b:2;
int c:3;
这两个结构体在内存中又是如何存储的呢? 求指教
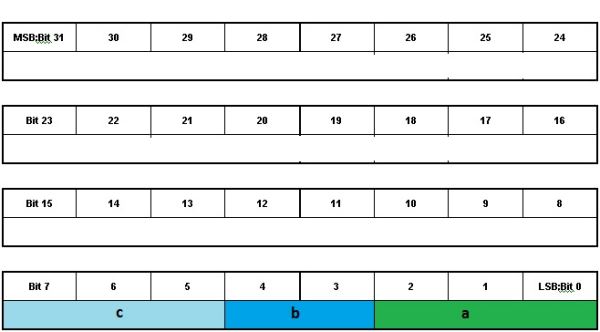
两个数据结构的位域都在整形(4字节)里分配, 如果不足一个整形的部分就按一个整形算
下面的图说明了位域在内存里的存储情况, 可以看到, 两种情况下位域都只占了一个字节, 不足一个整形(4字节), 所以就按一个整形算

如果我把struct A改为
struct A
char a:4;
char b:4;
short i:8;
long m;
这是sizeof(A)为什么又是8了啊。。
a, b 占1字节
i占2字节
m占4字节
所以这个结构一共占7字节。但sizeof()得到8是因为内存对齐。
32位计算机中,为了内存的存取速度, 一次会读取4个字节。 在储存数据时, 也会按照4字节一个单元把数据对其。
比如这个例子里, a,b在第1个字节, i在第2,3个字节, m放在第5~8个字节, 而不是4~7字节, 这样在读取m时只需要一次内存操作。(如果在4~7字节需要先读取1~4字节, 再读取5~8字节)
如果你把i和m的顺序换一下, sizeof结果会不一样, 也是这个原因
这两个数据结构都是用了整型的1字节8个比特,在大头字节序的CPU上,这个字节是整型的最低位字节,其他高位的3字节没有用到。在这个字节内部,按变量定义的顺序,从低位到高位依次存放。
struct A里,a在整型第一字节的低位5个比特,b在整型第一字节高位3个比特。struct B类似。追问
谢谢你的回答
大头字节序的CPU 指的是? 是小端机吗
譬如ARM是小头字节序,PowerPC是大头字节序。区别就是高位字节放在前还是放在后。
参考技术B 你搞错了把!应该是8和12把! 参考技术C
澄清 C 中的位域排序语义
【中文标题】澄清 C 中的位域排序语义【英文标题】:Clarification about Bit-field ordering semantics in C 【发布时间】:2013-09-06 07:22:50 【问题描述】:我很难理解 C99 标准草案 (N1256) 中关于位域 (6.7.2.1:10) 的一段的确切含义:
6.7.2.1 结构和联合说明符
[...]
语义
[...]
实现可以分配任何大到足以容纳位字段的可寻址存储单元。如果有足够的空间剩余,紧跟在结构中另一个位域之后的位域将被打包到同一单元的相邻位中。如果剩余空间不足,则将不适合的位域放入下一个单元还是与相邻单元重叠是实现定义的。 一个单元内的位域分配顺序(高位到低位或低位到高位)是实现定义的。未指定可寻址存储单元。
强调的句子将我的英语技能发挥到了极限:我不明白它是指一个单元内的单个位域,还是指单个位域内的位排序或其他东西。
我会试着用一个例子来说明我的疑问。假设无符号整数是 16 位,实现选择无符号整数作为可寻址存储单元(并且字节为 8 位宽),并且不会出现其他对齐或填充问题:
struct Foo
unsigned int x : 8;
unsigned int y : 8;
;
因此,假设x 和y 字段存储在同一个单元内,那么根据该语句定义的实现是什么?据我了解,这意味着在该 unsigned int 单元内,x 可以存储在低于y 的地址或反之亦然,但我不确定,因为直觉上我认为如果没有位域与两个底层存储单元重叠,声明顺序将对底层位域施加相同的顺序。
注意:我担心我在这里遗漏了一些微妙的术语(或者,更糟糕的是,一些技术术语),但我不明白是哪个。
任何指针表示赞赏。谢谢!
【问题讨论】:
你说的还有更多... 无法保证unsigned x : 1 会修改哪个位,是最低位还是最高位。所以如果sizeof(unsigned int) == 4,x可以保存在第1位或第32位。
Representing individual bits in C 的可能重复项
【参考方案1】:
我真的看不出有什么不清楚的地方
一个单元内位域的分配顺序(高位到 低阶或低阶到高阶)是实现定义的。
它讨论的是位域的分配,而不是域内的位。因此,除了非位域成员之外,您无法确定可寻址单元内的位域是按什么顺序排序的。
否则,位域本身的表示保证与基础类型“相同”,分为值位和符号位(如果适用)。
本质上,它表示包含位域的存储单元的解剖结构是实现定义的,您不应尝试通过其他方式(union 左右)访问这些位,因为这会使您的代码非便携式。
【讨论】:
正如我在问题中所暗示的那样,我担心我会错过一些关于位域的东西(我希望这只是一些术语上的混淆,但从我得到的答案中我想我有以便更好地了解技术方面)。我从来没有不得不使用位域,但可能在不久的将来我会需要它们,因此我试图直接从标准中掌握细节。您的解释非常清楚 (+1),但我仍然需要花时间将其与标准文本联系起来。 @LorenzoDonati,是的,它的语义不是那么容易掌握,我同意。尽可能避免使用位域,因为它们通常不能实现太多目的。如果您对以压缩形式可移植地操作位感兴趣,那么在uint64_t 等无符号类型上使用位计算可能更可取。对于不同类型平台之间的二进制数据兼容性,位域也没有多大帮助。
我意识到我需要花更多时间在这个主题上,但在我看来,标准对位域的保证仍然相当少。一切似乎都是由实现定义的。我现在不确定,但我想我需要对一些外部专用 I/O 接口卡的硬件寄存器的访问进行编程。我认为位域可以减轻(但未知的)任务(所以我先发制人),但它似乎不能便携。不管怎样,谢谢!如果在接下来的几天内没有更详细的解释出现,我会接受你的回答。
所以除了非位域成员,你不能确定可寻址单元内的位域是按什么顺序排序的。:你不能确保一般。如果实现是已知的,那么您可以确定,因为顺序是实现定义的。【参考方案2】:
我的看法是,C99 规范正在讨论位字段的位字节序,以及它们如何在“单元”(字节字等)中排序。如果你开始转换结构,基本上你是靠自己的。
例子
bit ex1 ex2 ex3
D7 x3 y0 x0
D6 x2 y1 x1
D5 x1 y2 x2
D4 x0 y3 x3
D3 y3 x0 y0
D2 y2 x1 y1
D1 y1 x2 y2
D0 y0 x3 y3
以上三种不同的方案用于对字节“单元”中的两个 4 位字段进行排序。就 C99 标准而言,它们都是合法的。
【讨论】:
【参考方案3】:Gibbon1 的回答是正确的,但我认为示例代码对这类问题很有帮助。
#include <stdio.h>
int main(void)
union
unsigned int x;
struct
unsigned int a : 1;
unsigned int b : 10;
unsigned int c : 20;
unsigned int d : 1;
bits;
u;
u.x = 0x00000000;
u.bits.a = 1;
printf("After changing a: 0x%08x\n", u.x);
u.x = 0x00000000;
u.bits.b = 1;
printf("After changing b: 0x%08x\n", u.x);
u.x = 0x00000000;
u.bits.c = 1;
printf("After changing c: 0x%08x\n", u.x);
u.x = 0x00000000;
u.bits.d = 1;
printf("After changing d: 0x%08x\n", u.x);
return 0;
在使用 MinGW 的 GCC 的 little-endian x86-64 CPU 上,输出为:
更改a后:0x00000001
改变b后:0x00000002
改c后:0x00000800
改d后:0x80000000
由于这是一个联合,无符号整数(x)和位域结构(a/b/c/d)占用同一个存储单元。 [the] 位域的分配顺序决定了 u.bits.a 是指 x 的最低有效位还是 x 的最高有效位。通常,在 little-endian 机器上:
u.bits.a == (u.x & 0x00000001)
u.bits.b == (u.x & 0x000007fe) >> 1
u.bits.c == (u.x & 0xeffff800) >> 11
u.bits.d == (u.x & 0x80000000) >> 31
在大端机器上:
u.bits.a == (u.x & 0x80000000) >> 31
u.bits.b == (u.x & 0x7fe00000) >> 21
u.bits.c == (u.x & 0x001ffffe) >> 1
u.bits.d == (u.x & 0x00000001)
该标准的意思是,C 编程语言不需要任何特定的字节序——大字节序和小字节序机器可以按照最适合其寻址方案的顺序放置数据。
【讨论】:
以上是关于求大神指教C语言中的位域的主要内容,如果未能解决你的问题,请参考以下文章
C语言,数组输入遇到问题求大神指教:哪里错了,如何改正,为啥会出现这种情况?