第一篇数据分析项目实战:用户消费行为分析
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第一篇数据分析项目实战:用户消费行为分析相关的知识,希望对你有一定的参考价值。
参考技术A 本篇文章以模仿为主, 利用pandas进行数据处理 ,分析用户消费行为。数据来源CDNow网站的用户购买明细。一共有用户ID,购买日期,购买数量,购买金额四个字段。分析步骤
第一部分:数据类型的处理—字段的清洗
缺失值的处理、数据类型的转化
第二部分:按月数据分析
每月的消费总金额、每月的消费次数、每月的产品购买量、每月的消费人数
第三部分:用户个体消费数据分析
用户消费金额和消费次数的描述统计、用户消费金额和消费次数的散点图、用户消费金额的分布图(二八法则)、用户消费次数的分布图
、用户累计消费金额的占比
第四部分:用户消费行为分析
用户第一次消费时间、用户最后一次消费时间、新老客消费比、用户分层、用户购买周期、用户生命周期。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from datetime import datetime
%matplotlib inline
plt.style.use('ggplot')
加载包和数据,文件是txt,用read_table方法打开,因为原始数据不包含表头,所以需要赋予。字符串是空格分割,用\s+表示匹配任意空白符。
一般csv的数据分隔是以逗号的形式,但是这份来源于网上的数据比价特殊,它是通过多个空格来进行分隔
columns = ['user_id','order_dt','order_products','order_amount']
df = pd.read_table("CDNOW_master.txt",names = columns,sep = '\s+')
列字段的含义:
user_id:用户ID
order_dt:购买日期
order_products:购买产品数
order_amount:购买金额
消费行业或者是电商行业一般是通过订单数,订单额,购买日期,用户ID这四个字段来分析的。基本上这四个字段就可以进行很丰富的分析。
观察数据,判断数据是否正常识别。值得注意的是一个用户可能在一天内购买多次,用户ID为2的用户在1月12日买了两次,这个细节不要遗漏。
查看数据类型、数据是否存在空值;原数据没有空值,很干净的数据。接下来我们要将时间的数据类型转化。
当利用pandas进行数据处理的时候,经常会遇见数据类型的问题,当拿到数据的时候,首先要确定拿到的是正确的数据类型,如果数据类型不正确需要进行数据类型的转化,再进行数据处理。附: 常见pandas数据类型转化
用户平均每笔订单购买2.4个商品,标准差在2.3,稍稍具有波动性。中位数在2个商品,75分位数在3个商品,说明绝大部分订单的购买量都不多。最大值在99个,数字比较高。购买金额的情况差不多,大部分订单都集中在小额。
一般而言,消费类的数据分布,都是长尾形态。大部分用户都是小额,然而小部分用户贡献了收入的大头,俗称二八。
数据类型的转化
df['order_dt'] = pd.to_datetime(df.order_dt,format = '%Y%m%d') #Y四位数的日期部分,y表示两位数的日期部分
df['month'] = df.order_dt.values.astype('datetime64[M]')
到目前为止,我们已经把数据类型处理成我们想要的类型了。我们通过四个字段及衍生字段就可以进行后续的分析了。
接下来我们用之前清洗好的字段进行数据分析。从用户方向、订单方向、消费趋势等进行分析。
1、消费趋势的分析
每月的消费总金额
每月的消费次数
每月的产品购买量
每月的消费人数
目的:了解这批数据的波动形式。
01-每月消费总金额
grouped_month = df.groupby('month')
order_month_amount = grouped_month.order_amount.sum()
order_month_amount.head()
用groupby创建一个新的对象。这里要观察消费总金额,需要将order_amount求和
按月统计每个月的CD消费总金额。从图中可以看到,前几个月的销量非常高涨。数据比较异常。而后期的销量则很平稳。
前三个月的消费订单数在10000笔左右,后续月份的消费人数则在2500人左右。
每月的产品购买量一样呈现早期购买量多,后期平稳下降的趋势。为什么会呈现这个原因呢?我们假设是用户身上出了问题,早期时间段的用户中有异常值,第二假设是各类促销营销,但这里只有消费数据,所以无法判断。
04-每月的消费人数(去重)
方法一:df.groupby('month').user_id.apply(lambdax:len(x.drop_duplicates())).plot()
方法二:df.groupby('month').user_id.nunique().plot()
每月的消费人数小于每月的消费次数,但是区别不大。前三个月每月的消费人数在8000—10000之间,后续月份,平均消费人数在2000不到。一样是前期消费人数多,后期平稳下降的趋势。
数据透视表是更简单的方法,有了这个之后大家用里面的数据进行作图也是OK的,而且更加的快捷,所以pandas到后面的话解决一个问题会想到两到三个方法。具体看那个方便,那个简单。
之前我们维度都是月,来看的是趋势。有时候我们也需要看个体来看这个人的消费能力如何,这里划分了五个方向如下:
用户消费金额和消费次数的描述统计
用户消费金额和消费次数的散点图
用户消费金额的分布图(二八法则)
用户消费次数的分布图
用户累计消费金额的占比(百分之多少的用户占了百分之多少的消费额)
从用户角度看,每位用户平均购买7张CD,最多的用户购买了1033张。用户的平均消费金额(客单价)100元,标准差是240,结合分位数和最大值看,平均值才和75分位接近,肯定存在小部分的高额消费用户。
如果大家能够接触到消费、金融和钱相关的数据,基本上都符合二八法则,小部分的用户占了消费的大头
绘制用户的散点图,用户比较健康而且规律性很强。因为这是CD网站的销售数据,商品比较单一,金额和商品量的关系也因此呈线性,没几个离群点。
从上图直方图可知,大部分用户的消费能力确实不高,绝大部分呈现集中在很低的消费档次。高消费用户在图上几乎看不到,这也确实符合消费行为的行业规律。
虽然有极致干扰了我们的数据,但是大部分的用户还是集中在比较低的而消费档次。
到目前为止关于用户的消费行为有一个大概的了解
按用户消费金额进行升序排序,由图可知50%的用户仅贡献了15%的销售额度。而排名前5000的用户就贡献了60%的消费额。也就是说我们只要维护了这5000个用户就可以把业绩KPI完成60%,如果能把5000个用户运营的更好就可以占比70%—80%之间。
求月份的最小值,即用户消费行为中的第一次消费时间。所有用户的第一次消费都集中在前三个月.
观察用户的最后一次消费时间。用户最后一次消费比第一次消费分布广,大部分最后一次消费集中在前三个月,说明很多客户购买一次就不再进行购买。随着时间的增长,最后一次购买数也在递增,消费呈现流失上升的情况,用户忠诚度在慢慢下降。
user_id为1的用户第一次消费时间和最后一次消费时间为19970101,说明他只消费了一次
有一半的用户只消费了一次
order_products求的是消费产品数,把它替换成消费次数也是可以,但是因为我们这里消费次数是比较固定的,所以使用消费产品数的维度。
R表示客户最近一次交易时间的间隔,客户在最近一段时间内交易的金额。F表示客户在最近一段时间内交易的次数,F值越大,表示客户交易越频繁,反之则表示客户交易不够活跃。M表示客户在最近一段时间内交易的金额。M值越大,表示客户价值越高,反之则表示客户价值越低。
用户分层,这里使用平均数
M不同层次客户的消费累计金额,重要保持客户的累计消费金额最高
不同层次用户的消费人数,之前重要保持客户的累计消费金额最高,这里重要保持客户的消费人数排名第二,但离一般挽留用户差距比较大,一般挽留用户有14074人,重要保持客户4554人
从RFM分层可知,大部分用户为重要保持客户,但是这是由于极致的影响,所以RFM的划分应该尽量以业务为准。尽量用小部分的用户覆盖大部分的额度,不要为了数据好看划分等级。
RFM是人工使用象限法把数据划分为几个立方体,立方体对应相应的标签,我们可以把标签运用到业务层面上。比如重要保持客户贡献金额最多159203.62,我们如何与业务方配合把数据提高或者维护;而重要发展客户和重要挽留客户他们有一段时间没有消费了,我们如何把他们拉回来
用户每个月的消费次数,对于生命周期的划分只需要知道用户本月是否消费,消费次数在这里并不重要,需要将模型进行简化
使用数据透视表,需要明确获得什么结果。有些用户在某月没有进行过消费,会用NaA表示,这里用filna填充。
对于尾部数据,user_id2W+的数据是有问题的,因为从实际的业务场景上说,他们一月和二月都没有注册三月份才是他们第一次消费。透视会把他们一月和二月的数据补上为0,这里面需要进行判断将第一次消费作为生命周期的起始,不能从一月份开始就粗略的计算
主要分为两部分的判断,以本月是否消费为界。本月没有消费,还要额外判断他是不是新客,因为部分用户是3月份才消费成为新客,那么在1、2月份他连新客都不是,用unreg表示。如果是老客,则为unactive
本月若没有消费,需要判断是不是第一次消费,上一个时间窗口有没有消费。可以多调试几次理顺里面的逻辑关系,对用户进行分层。
《业内主流写法》
这里用户生命周期的状态变化是用数据透视表一次性做的,但在实际业务场景中我们可能用SQL把它作为中间表来处理。我们有了明细表,会通过明细表来计算出状态表;也就是它的数据上个月是什么样的情况得出来,比如上个月是新用户或者回流用户,我们直接用上个月的状态left join本月的状态。直接用SQL进行对比
可以用pandas将每个月的状态计算出来,不是逐行而是月份计算,先算出一月份哪些用户是新购买的,然后判断二月份是否购买,两者left join
由上表可知,每月用户的消费状态变化。活跃用户、持续消费的用户对应的是消费运营质量。回流用户,之前不消费本月才消费对应的是唤回运营。不活跃的用户对应的是流失
这里可以针对业务模型下个定义:流失用户增加,回流用户正在减少
user_id 1为空值,表示该客户只购买过一个订单。user_id为2 的用户第二笔订单与第二笔订单在同一天购买
订单周期呈指数分布,用户的平均购买周期是68天,绝大部分用户的购买周期都低于100天。
数据偏移比较大,中位数是0天也就是超过50%的用户他的生命周期是0天只购买了一次,但是平均生命周期有134天,最大值是544天
用户的生命周期受只购买一次的用户影响比较厉害(可以排除),用户均消费134天, 中位数仅0天
筛选出lifetime>0,既排除了仅消费了一次那些人,有不少用户生命周期靠拢在0天,部分质量差的用户虽然消费了两次,但是任然无法持续,在用户首次消费30天内应该尽量引导。少部分用户集中在50—300天,属于普通型的生命周期。高质量用户的生命周期,集中在400天以后,这属于忠诚用户。
applymap针对DataFrame里的所有数据。用lambda进行判断,因为这里设计了多个结果,所以要两个if else
用sum和count相除即可计算出复购率。因为这两个函数都会忽略NAN,而NAN是没有消费的用户,count不论是0还是1都会统计,所以是总的消费用户数,而sum求何计算了两次以上的消费用户。这里用了比较巧妙的替代法计算复购率,SQL中也可以用。
图上可以看出复购率在早期,因为大量新用户加入的关系,新客的复购率并不高,譬如1月新客们的复购率只有6%左右。而在后期,这时的用户都是大浪淘沙剩下的老客户,复购率比较稳定,在20%左右.
单看新客和老客,复购率有三倍左右的差距
接下来计算回购率。回购率是某一个时间窗口内消费的用户,在下一个时间窗口人就消费的占比。我1月消费用户1000,他们中有300个2月依然消费,回购率是30%
0代表当月消费过次月没有消费过,1代表当月消费过次月依然消费
新建一个判断函数。data是输入数据,既用户在18个月内是否消费的记录,status是空列表,后续用来保存用户是否回购的字段。因为有18个月,所以每个月都要进行一次判断,需要用到循环。if的主要逻辑是,如果用户本月进行过消费,且下月消费过,记为1,没有消费过是0.本月若没有进行过消费,为NAN,后续的统计中进行排除。apply函数应用在所有行上,获得想要的结果。
最后计算和复购率大同小异,用count和sum求出,从图中可以看出,用户的回购率高于复购,约在30%左右,和老客户差异不大。从回购率和复购率综合分析可以得出,新客的整体质量低于老客,老客的忠诚度(回购率)表现较好,消费频次稍次,这是CDNow网站的用户消费特征。
概念+实战讲解!一文带你了解RFM模型kaggle项目实战分享数据分析
今日份学习分享,请查收!
目录
必须要看的前言
RFM模型是衡量客户价值和客户创利能力的重要工具和手段。在众多的客户关系管理(CRM)的分析模式中,RFM模型是被广泛提到的。
所以RFM模型是数据分析师必须掌握的知识点,而本篇文章详细介绍RFM模型的同时,还附带了kaggle项目实战,收藏本篇文章,你还怕搞不懂RFM模型,不懂怎么对用户进行分类吗?
一、什么是RFM模型?
RFM模型通过一个客户的近期购买行为、购买的总体频率以及花了多少钱3项指标来描述该客户的价值状况。
R值:Recency, 最近一次消费
- 最近一次消费指的是上一次购买距离当前的时间。比方说最近一次买车什么时候,上一次买唱片是几时。
理论上,上一次消费时间越近的顾客应该是比较好的顾客,对提供即时的商品或是服务也最有可能会有反应。营销人员若想业绩有所成长,只能靠偷取竞争对手的市场占有率,而如果要密切地注意消费者的购买行为,那么最近的一次消费就是营销人员第一个要利用的工具。
功能:R值的功能不仅在于提供的促销信息而已,营销人员的消费报告可以监督事业的健全度。优秀的营销人员会定期查看消费分析,以掌握趋势。月报告如果显示上一次购买很近的客户,(消费为1个月)人数如增加,则表示该公司是个稳健成长的公司;反之,如上一次消费为一个月的客户越来越少,则是该公司迈向不健全之路的征兆。
F值:Frequency, 消费频率
- 消费频率是顾客在限定的期间内所购买的次数。我们可以说最常购买的顾客,往往也是满意度最高的顾客。增加顾客购买的次数意味着从竞争对手处偷取市场占有率,由别人的手中赚取营业额。
基于这个指标,我们可以把客户分为五等分:如购买一次的客户为新客户,购买两次的客户为潜力客户,购买三次的客户为老客户,购买四次的客户为成熟客户,购买五次及以上则为忠实客户。运营人员的目标是要让消费者不断升级。
注意:不同类型的商品的消费频率往往有着较大的差距,如婚礼类产品和零食类产品,前者往往也就购买一次差不多得了(多了社会就乱套了哈哈),后者属于易耗品,消耗评论搞,相对容易产生重复购买,所以说F值不适合用作跨类目比较。
M值:Monetary, 消费金额
- 消费金额同消费频率一样,有限定的时间范围,指的是一段时间(通常是1年)内的消费金额。它同时也能验证帕累托法则(俗称二八法则),即80%的收入来自于20%的客户。
M值是RFM模型中相对于R值和F值最难使用,但最具有价值的指标。同一品牌美妆类,价格浮动范围基本在某个特定消费群的可接受范围内,加上单一品类购买频次不高,所以对于一般店铺而言,M值对客户细分的作用相对较弱。
二、实践应用有哪些?
基于RFM模型进行客户细分
CRM实操时可以选择RFM模型中的1-3个指标进行客户细分,如下表所示。切记细分指标需要在自己可操控的合理范围内,并非越多越好,一旦用户细分群组过多,一来会给自己的营销方案执行带来较大的难度,而来可能会遗漏用户群或者对同个用户造成多次打扰。
如何选择最终指标有两个参考标准:店铺的客户基数,店铺的商品和客户结构。
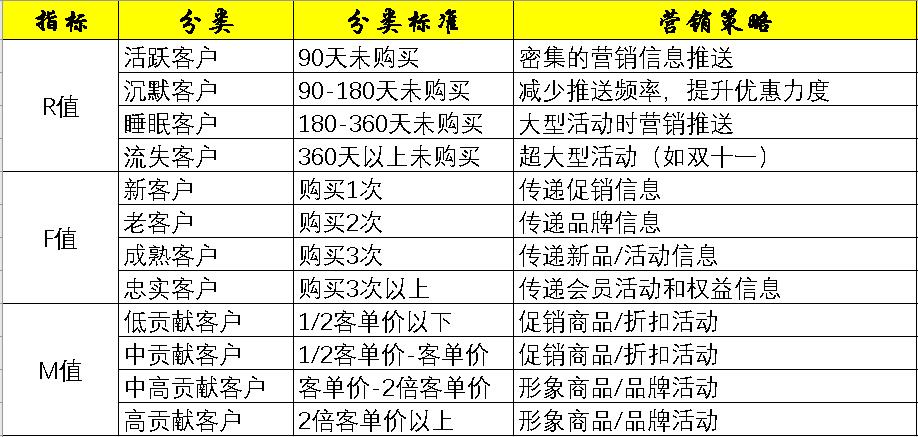
店铺的客户基数:在店铺自身客户数量不大的情况下,选择1-2个维度进行细分即可;反之可以选择2-3个指标进行用户用类。
店铺的商品和客户结构:如果在店铺的商品层次比较单一,客单价差异幅度不大的情况下,购买频次(F值)和消费金额(M值)高度相关的情况下,可以只选择比较容易操作的购买频次(F值)代替消费金额(M值)。对于刚刚开店还没形成客户粘性的店铺,则可以放弃购买频次(F值),直接用最后一次消费(R值)或者消费金额(M值)。
通过RFM模型评分后输出目标用户
RFM模型评分主要有三个部分:
-
确定RFM三个指标的分段和每个分段的分值;
-
计算每个客户RFM三个指标的得分;
-
计算每个客户的总得分,并且根据总得分筛选出优质的客户
还是以上图为例。
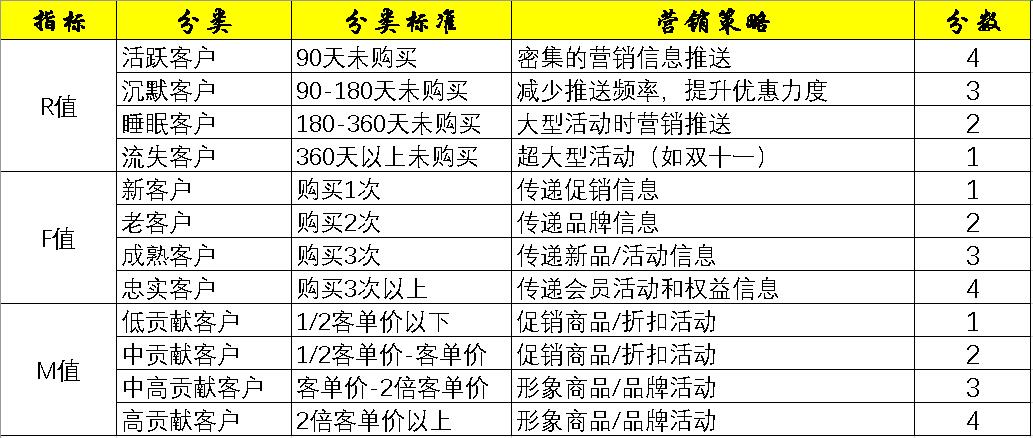
此时我们将每个用户在每个指标下所得的分数相加,就可得到最终的分数。
但这里需要注意的是,对于每个指标下所对应的每个分值不应像上图一样,应根据不同的店铺进行进一步的赋值(听其他网友说可以用AHP层次分析法,我暂时还没有去了解)。
并且,相加时最好先给每个指标设一个权重,比方说最终的计算公式可以是:score = 0.5R+0.3F+0.2M。
具体的权重设置也可以参考上文提到的两个参考标准。
基于RFM的常用策略
RFM非常适用于提供多种商品的企业,这些商品单价相对不高,或者相互间有互补性,具有多次重复购买的必要,这些企业可能提供如下商品:日用消费品、服装、小家电等;RFM也适用于这类企业,它们既提供高价值耐用商品、同时又提供配套的零部件或维修服务,如下:精密机床、成套生产设备、打印机等;RFM对于商品批发、原材料贸易、以及一些服务业(如旅行、保险、运输、快递、娱乐等)的企业也很适用。
RFM可以用来提高客户的交易次数。业界常用的DM(直接邮寄),常常一次寄发成千上万封邮购清单,其实这是很浪费钱的。根据统计(以一般邮购日用品而言),如果将所有R(Recency)的客户分为五级,最好的第五级回函率是第四级的三倍,因为这些客户刚完成交易不久,所以会更注意同一公司的产品信息。如果用M(Monetary)来把客户分为五级,最好与次好的平均回复率,几乎没有显著差异。
有些人会用客户绝对贡献金额来分析客户是否流失,但是绝对金额有时会曲解客户行为。因为每个商品价格可能不同,对不同产品的促销有不同的折扣,所以采用相对的分级(例如R、F、M都各分为五级)来比较消费者在级别区间的变动,则更可以显现出相对行为。企业用R、F的变化,可以推测客户消费的异动状况,根据客户流失的可能性,列出客户,再从M(消费金额)的角度来分析,就可以把重点放在贡献度高且流失机会也高的客户上,重点拜访或联系,以最有效的方式挽回更多的商机。
补充
以上三个指标会将维度细分出4份,这样就能够细分出4x4x4=64类用户,再根据每类用户精准营销……显然64类用户已超出普通人脑的计算范畴了,更别说针对64类用户量体定制营销策略。实际运用上,我们只需要把每个维度做一次两分即可,这样在3个维度上我们依然得到了8组用户。
(编号次序RFM,1代表高,0代表低)
重要价值客户(111):最近消费时间近、消费频次和消费金额都很高,必须是VIP啊!
重要保持客户(011):最近消费时间较远,但消费频次和金额都很高,说明这是个一段时间没来的忠诚客户,我们需要主动和他保持联系。
重要发展客户(101):最近消费时间较近、消费金额高,但频次不高,忠诚度不高,很有潜力的用户,必须重点发展。
重要挽留客户(001):最近消费时间较远、消费频次不高,但消费金额高的用户,可能是将要流失或者已经要流失的用户,应当给予挽留措施。
三、kaggle项目实战讲解
项目来源:
https://www.kaggle.com/carrie1/ecommerce-data
项目简介:
这是一个跨国数据集,其中包含在英国注册的商店于2010年12月1日至2011年12月9日之间发生的所有在线零售交易。该公司主要销售独特的全天候礼品,许多客户对象是批发商。
本次项目的主要目的是利用RFM模型进行用户分类。
PS: 本次项目是在jupyter上运行的。
导入模块
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置汉字字体,优先使用黑体
加载数据
df = pd.read_csv('data.csv',encoding = 'ISO-8859-1', dtype = {'CustomerID':str})
接下来正式开始进行分析啦!
1 数据探索与数据清洗
1.1 数据探索
df.shape

df

数据包含541910行,8个字段,字段内容为:
InvoiceNo: 订单编号,每笔交易有6个整数,退货订单编号开头有字母’C’。
StockCode: 产品编号,由5个整数组成。
Description: 产品描述。
Quantity: 产品数量,有负号的表示退货。
InvoiceDate: 订单具体时间。
UnitPrice: 单价(英镑),单位产品的价格。
CustomerID:客户编号,每个客户编号由5位数字组成。
Country: 国家的名称,每个客户所在国家/地区的名称。
df.info()

我们不难发现,我们需要进行日期格式的转换,以及常规的缺失值统计、去重以及异常值的检测与处理。
1.2 缺失值统计
# 先统计缺失率
df.apply(lambda x :sum(x.isnull())/len(x),axis=0)

# Description是用于产品描述,与后续分析无关,删去。
df.drop(['Description'],axis=1,inplace=True)
df.head()

# 这里的CustomerID对于后续分析仅起到标识作用,不做删除,可以用unknown填充。
df['CustomerID'] = df['CustomerID'].astype('str')
df.info()

df['CustomerID'] = df['CustomerID'].fillna('unknown')
1.3 日期格式的转换
df['date'] = [x.split(' ')[0] for x in df['InvoiceDate']]
df['date'] = pd.to_datetime(df['date'])
df['month'] = df['date'].astype('datetime64[M]')
df[['date', 'month']]

1.4 去重
df = df.drop_duplicates()
df.shape

1.5 异常值处理
在这里,我们把退货订单看做异常数据(即数量为负数或者货单价为负数的数据)。
df[(df['Quantity']<0) | (df['UnitPrice']<0)]

# 除去异常数据
df = df[(df['Quantity']>0) & (df['UnitPrice']>0)]
df[(df['Quantity']<0) | (df['UnitPrice']<0)]

2 用户分类
# 首先计算R值
R_value = df.groupby('CustomerID')['date'].max()
R_value = (df['date'].max() - R_value).dt.days # 这里将2011-12-9作为当前日期进行计算
R_value

# 将2010-12-1至2011-12-9视为F值的区间段,计算每个客户所下单的数量
F_value = df.groupby('CustomerID')['InvoiceNo'].nunique()
F_value

# 首先计算每个订单的消费金额
df['amount'] = df['Quantity'] * df['UnitPrice']
# 再计算M值
M_value = df.groupby('CustomerID')['InvoiceNo'].nunique()
M_value = df.groupby('CustomerID')['amount'].sum()
M_value

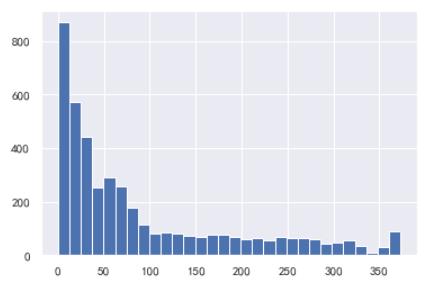
R_value.describe()

R_value.hist(bins = 30)
M_value.describe()

M_value.hist(bins = 30)

M_value.plot.box()

可见非常不均。
M_value[M_value<2000].hist(bins = 30)

# 分位数 观察出异常值还是很严重
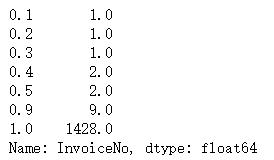
F_value.quantile([0.1,0.2,0.3,0.4,0.5,0.9,1])
F_value.hist(bins = 30)

F_value.plot.box()

F_value[F_value<30].hist(bins = 30)

一样是非常的不均。
# 每个指标下都分为五个等级
R_bins = [0,30,90,180,360,720]
F_bins = [1,2,5,10,20,5000]
M_bins = [0,500,2000,5000,10000,200000]
先是R值:
R_score = pd.cut(R_value,R_bins,labels=[5,4,3,2,1],right=False)
R_score

接着是F值:
F_score = pd.cut(F_value,F_bins,labels=[1,2,3,4,5],right=False)
F_score

最后是M值:
M_score = pd.cut(M_value,M_bins,labels=[1,2,3,4,5],right=False)
M_score

生成新的数据框看一看:
rfm = pd.concat([R_score,F_score,M_score],axis=1)
rfm.rename(columns={'date':'R_score','InvoiceNo':'F_score','amount':'M_score'},inplace=True)
rfm
rfm.info()

改下数据格式:
rfm['R_score'] = rfm['R_score'].astype('float')
rfm['F_score'] = rfm['F_score'].astype('float')
rfm['M_score'] = rfm['M_score'].astype('float')
rfm.describe()

按平均值在每个指标下划分价值高低:
rfm['R'] = np.where(rfm['R_score']>3.82,'高','低')
rfm['F'] = np.where(rfm['F_score']>2.03,'高','低')
rfm['M'] = np.where(rfm['M_score']>1.89,'高','低')
rfm

# 将三个指标结合
rfm['RFM']=rfm['R']+rfm['F']+rfm['M']
rfm

def rfm2grade(x):
if x=='高高高':
return '高价值客户'
elif x=='高低高':
return '重点发展客户'
elif x=='低高高':
return '重点保持客户'
elif x=='低低高':
return '重点挽留客户'
elif x=='高高低':
return '一般价值客户'
elif x=='高低低':
return '一般发展客户'
elif x=='低高低':
return '一般保持客户'
else:
return '一般挽留客户'
rfm['用户等级']=rfm['RFM'].apply(rfm2grade)
rfm

3 分类结果
rfm['用户等级'].value_counts()

rfm['用户等级'].hist(figsize=(12,9))

# 分类占比
rfm['用户等级'].value_counts() / rfm['用户等级'].value_counts().sum()

rfm['用户等级'].value_counts().plot(kind = 'pie', # 选择图形类型
figsize = (15, 9),
autopct='%.1f%%', # 饼图中添加数值标签
title = 'RFM用户分类', # 为饼图添加标题
textprops = {'fontsize':8},# 设置文本标签的属性值
subplots=True)
plt.legend(loc=2, bbox_to_anchor=(1.05,1.0),borderaxespad = 0.) # 添加注解

4 结论与建议
从用户分类占比的结果来看,高价值客户和重要发展客户共占总数的47%,是公司收入的重要来源。
-
高价值客户(111)
RFM三个值都很高,要提供vip服务。 -
重点发展客户(101)
消费频率低,但是其他两个值很高,就要想办法提高他的消费频率,建议及时推送公司活动信息或新品相关信息来吸引客户。 -
重点保持客户(011)
最近消费距离现在时间较远,也就是F值低,但是消费频次和消费金额高。这种用户,是一段时间没来的忠实客户。应该主动和他保持联系,提高复购率。可以赠送优惠券或推送商品折扣信息来增加购买次数。 -
重点挽留客户(001)
最近消费时间距离现在较远、消费频率低,但消费金额高。这种用户,即将流失,要主动联系用户,调查清楚哪里出了问题,并想办法挽回。当然同样可以赠送优惠券或推送商品折扣信息来增加购买次数。 -
一般发展客户(100)
公司应获取客户的详细数据信息用户画像, 从中了解客户的消费属性。建议对此类客户进行精准营销和及时推送产品信息。
当然,最终的营销策略应基于公司自身的财政投入决定。
RFM也不可以用过头,而造成高交易的客户不断收到信函。每一个企业应该设计一个客户接触频率规则,如购买三天或一周内应该发出一个感谢的电话或Email,并主动关心消费者是否有使用方面的问题,一个月后发出使用是否满意的询问,而三个月后则提供交叉销售的建议,并开始注意客户的流失可能性,不断地创造主动接触客户的机会。这样一来,客户再购买的机会也会大幅提高。
结束语
为方便需要的朋友运行代码,我也把完整的代码和数据文件放到了网盘上,需要的朋友自取。
链接:https://pan.baidu.com/s/1qzVvW2tFYquertL6jbWx8w
提取码:1024
引用鸣谢:https://www.jianshu.com/p/4b60880f24e2
推荐关注的专栏
👨👩👦👦 机器学习:分享机器学习实战项目和常用模型讲解
👨👩👦👦 数据分析:分享数据分析实战项目和常用技能整理
CSDN@报告,今天也有好好学习
以上是关于第一篇数据分析项目实战:用户消费行为分析的主要内容,如果未能解决你的问题,请参考以下文章