爬虫应用示例--puppeteer数据抓取的实现方法(续1)
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫应用示例--puppeteer数据抓取的实现方法(续1)相关的知识,希望对你有一定的参考价值。
参考技术A 本文介绍《 爬虫应用示例--puppeteer数据抓取的实现方法 》中涉及到的puppeteer组件如何安装,以及相关的坑。Puppeteer 是一个node库,内含了一个chrome浏览器,以及一组用来操纵Chrome的API。
相关资料:
1、github:https://github.com/puppeteer/puppeteer
2、中文资料:http://www.puppeteerjs.com/
3、API:https://chromedevtools.github.io/devtools-protocol/
安装方式:
1、方式一完整安装,包含chrome浏览器+API,npm i puppeteer【本文采用这种安装方式,因为项目需要浏览器自动化的远程数据自动化抓取】
2、方式二精简安装,只包含api,npm i puppeteer-core
说明:
1、以上语句执行一次如果出错,则可以再执行1到2次试试
2、也可以尝试用cnpm安装试试
3、总之要执行后,出现以上结果则说明安装成功
试过如下几种安装方式:
1、npm install puppeteer --save
2、npm install puppeteer --unsafe-perm=true --allow-root
3、npm install puppeteer --ignore-scripts
4、cnpm install puppeteer –save
5、cnpm install puppeteer --unsafe-perm=true --allow-root
其结果都是出现“Failed to set up Chromium r901912! Set "PUPPETEER_SKIP_DOWNLOAD" env variable to skip download.”的错误,安装失败。
使用Puppeteer进行数据抓取——图片下载
大多数情况下,图片获取并不是很困难的事情,获取图片的url,然后模拟浏览器请求即可。但是,有的时候这种方法往往无法生效,常见的情形有:
- 动态图片,每次获取都是一个新的,例如图片验证码,重新获取时是一个新的验证码图片,已经失去了效果了。
- 动态上下文,有的网站为了反爬虫,获取图片时要加上其动态生成的cookie才行。
这些情况下,使用puppeteer驱动chrome浏览器能看到图片,但获取url后单独请求时,要么获取到的图片无效,要么获取不到图片。本文这里就简单的介绍下一些十分通用且有效的下载这些图片的方法。
截图:
截图是一种非常简单除暴的方法,大多数的时候也是最方便有效的。特别是对于验证码之类的动态生成的图片,这些验证码获取原始图片往往需要一定时间的分析,但chrome能直接截取渲染后生成的图片,直接跳过了分析过程,十分方便。
这里以专利检索及分析网为例,截取它登陆的验证码。
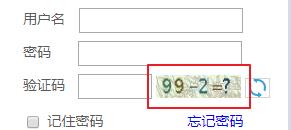
首先用devtool分析其selector path。
发现其为"#codePic",接下来的操作就非常简单了
await page.goto(\'http://www.pss-system.gov.cn/sipopublicsearch/portal/uiIndex.shtml\');
const image = await page.waitForSelector(\'#codePic\');
await image.screenshot({
path: \'验证码.png\',
omitBackground: false
});
这里用的并不是page.screenshot,因为那样对整个页面截图了,而是首先获取验证码图片的ElementHandle,然后调用ElementHandle.screenshot只对该元素截图。
这种方式非常简单有效,但由于是通过渲染的方式获取的数据,还是丢失了原始信息的,例如,svg图片就丢失了矢量信息了。
从缓存中读取
另外一种思路是直接从chrome缓存中的数据读取图片数据,就像chrome dev tool的source tab中的那样
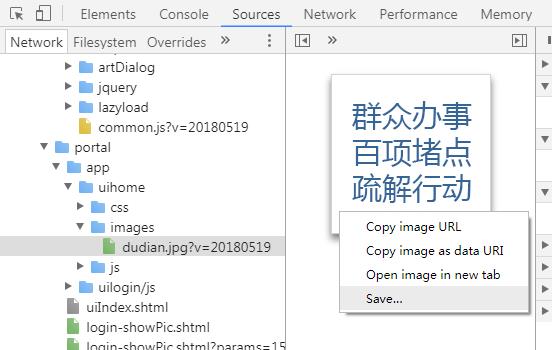
这个功能在puppeteer中并没有封装,在dev protocol中是有的,它主要涉及到如下两个api:
它可以用来获取资源树,就像上图左边所示:
它可以用来获取资源内容,它需要两个参数,frameid和url。frameid可以从page中获取,url必须是前面getResourceTree中获取的url。
虽然puppeteer没有封装这两个函数的功能,但还是有一个私有接口page._client.send可以发送原始dev protocol指令。这里我们可以简单的封装一下:
async function getResourceTree(page) {
var resource = await page._client.send(\'Page.getResourceTree\');
return resource.frameTree;
}
const assert = require(\'assert\');
async function getResourceContent(page, url) {
const { content, base64Encoded } = await page._client.send(
\'Page.getResourceContent\',
{ frameId: String(page.mainFrame()._id), url },
);
assert.equal(base64Encoded, true);
return content;
};
此时就说明我们可以利用前面的api获取该图片了。
const fs = require(\'fs\');
await page.waitForSelector(\'#codePic\');
const url = await page.$eval(\'#codePic\', i => i.src);
const content = await getResourceContent(page, url);
const contentBuffer = Buffer.from(content, \'base64\');
fs.writeFileSync(\'验证码.png\', contentBuffer, \'base64\');
这种方式并不限于只获取图片,也可以获取原始的js,svg之类的资源。
以上是关于爬虫应用示例--puppeteer数据抓取的实现方法(续1)的主要内容,如果未能解决你的问题,请参考以下文章